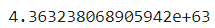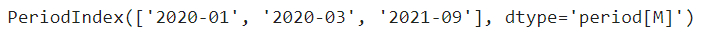📍 시계열 예측을 그래프(시각화)로 표현하는 모델 📍 Prophet 모델에 넣어줘야 하는 데이터 형태 - index는 날짜, Data컬럼, Adj Close(수정종가) 컬럼 - Prophet에서 사용하는 컬럼명은 ds, y 컬럼명을 사용함 > 기존 컬럼명을 수정해야함 > Data 컬럼명은 ds로, Adj Close 컬럼명은 y로 수정
데이터 프레임 수정
### 원본데이터에서
# - 최종 데이터 프레임 변수명 : prophet_data
prophet_data = goog_data.copy()
# - Date index는 컬럼 데이터로 변환
prophet_data.reset_index(inplace=True)
# - 훈련에 사용할 컬럼명 : Date, Adj Close
# - 훈련에 사용하지 않는 컬럼은 삭제
prophet_data.drop(["Open", "High", "Low", "Close", "Volume"], axis=1, inplace=True)
# - 훈련에 사용할 컬럼명 변경 : Data > ds, Adj Close > y
prophet_data.columns = ['ds', 'y']
# - ds 데이터 타입 변경
prophet_data["ds"] = pd.to_datetime(prophet_data["ds"])
prophet_data
Prophet 라이브러리 설치
📍Prophet 라이브러리 - 가상환경 새로 만들어서 진행 : 버전 충돌이 많이 일어남 - 가상환경 생성 시 python 버전은 3.6 버전 사용(3.9 버전은 사용이 안되기에, 3.9 이하 버전으로 사용) - Prophet 라이브러리는 C++ 프로그램으로 만들어져 있음
from fbprophet import Prophet
Prophet 모델 생성
''' 일 단위 주기성 활성화하기 '''
### prophet 모델 생성
model = Prophet(daily_seasonality=True)
''' 모델 학습 시키기 '''
model.fit(prophet_data[["ds", "y"]].iloc[:-10])
3년 후 예측하기
### 기존 값에 3년 후 일자를 포함해서 추출하기
future = model.make_future_dataframe(periods=365 * 3)
# future
### 예측하기
forecast = model.predict(future)
# forecast
### 시각화
model.plot(forecast)
# 계절성을 나타내는 그래프
# 그려진 범위 그래프가 커질 수록 오차가 있는 것
model.plot_components(forecast)
사용 라이브러리 - 한국증권거래소(KRX)의 주식거래일자에 대한 데이터 수집을 위한 라이브러리 - 설치 필요 : pip install exchange_calendars
import exchange_calendars as ecals
주식 거래일자 수집하기
### 원본 인덱스의 마지막 인덱스 일자 이후부터 1년치에 대한 거래일자 수집
# 거래 시작일
start = "2022-11-01"
# 거래 종료일
end = "2023-10-31"
### 한국증권거래소(KRX) code 값 : XKRX
k = ecals.get_calendar("XKRX")
k
시작 및 종료 기간 동안의 거래일 정보 가지고 오기
df =pd.DataFrame(k.schedule.loc[start:end])
df
open 컬럼을 사용하기 위해 날짜 정보를 리스트에 추가하기
date_list = []
for i in df["open"] :
date_list.append(i.strftime("%Y-%m-%d"))
# print(i.strftime("%Y-%m-%d"))
### DatetimeIndex 형태로 변환하기
date_index = pd.DatetimeIndex(date_list)
date_index
''' 기본 라이브러리 '''
import datetime
import matplotlib.pyplot as plt
import platform
from matplotlib import font_manager, rc
''' 마이너스 기호 및 한글 설정 '''
### 마이너스 기호 사용 설정
plt.rcParams["axes.unicode_minus"] = False
### OS 별 한글 설정
if platform.system() == "Windows" :
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
### Mac인 경우
elif platform.system() == "Darwin" :
rc("font", family="Applegothic")
### 리눅스인 경우
elif platform.system() == "Linux" :
path = "/usr/share/fonts/NanumGothic.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family="font_name")
else :
print("OS 확인 불가")
10년 치 주가 정보 수집하기
📍 증권사 : yahoo finance 📍 수집 증권 : 구글 주식(GOOG) 수집 📍 수집 기간 : 2012년 10월 31일부터 2022년 10월 31일까지 데이터 📍 증권사 제공 라이브러리 : yfinance 라이브러리를 제공하고 있음 📍 라이브러리 설치 필요 pip install yfinance
### 기간 설정 : 50일
interval = 50
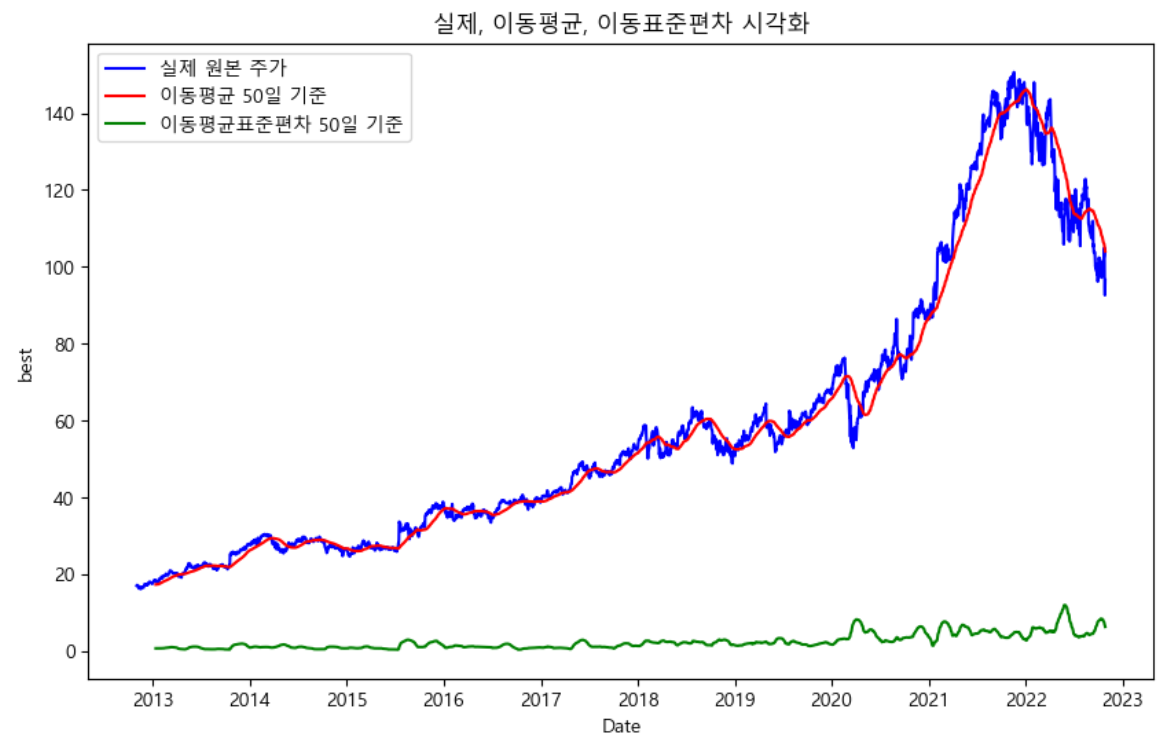
### 이동평균 계산하기
# - 주식 가격의 흐름을 유연성을 높이고 보기 좋게 하기 위해서 사용
# - 실제 가격 흐름과 이동평균값과 차이가 보이는 부분 : 변동성이 있는 부분
rolmean = data.rolling(interval).mean()
rolmean
### 이동표준편차 계산하기 : 변동성의 흐름 데이
rolstd = data.rolling(interval).std()
rolstd
<시각화 해석> * 비정상성 : 평균이 일정하지 않고 오르락내리락하는 불규칙 형태를 의미함 - 시계열 분석 시에는 비정상성을 정상성으로 만들어서 분석을 진행한다. - 정상성으로 만들기 위해 차수(d)라는 개념이 적용됨
- 표준화(정규화) 시키는 개념과 유사함 - 계절성을 나타내지 않는 것으로 보이며, 특징적 패턴을 보이고 있지 않음(=특정 주기성이 없음)
시계열 데이터 분석 모델 - ARIMA 모델
📍 시계열 분석 - 시계열 분석에서 주로 사용되는 모델은 ARIMA 모델로 오랫동안 사용되어 온 통계학적 기술통계 모델이다. - 시계열 분석은 일반적으로 예측분석 중에서도 시간을 독립변수(X)로 사용하고, 다른 데이터를 종속변수(Y)로 사용하여 예측하는 분석 방법 이다.
📍 ARIMA(Autoregressive Integrated Moving Average) - 시계열 분석(예측)에서 가장 널리 사용되는 모델 중 하나 - 시계열 분석은 현 시점까지의 데이터를 이용해서 앞으로 어떤 패턴의 차트를 그릴지 예측하는 분석기법이다.
* AR(Autoregressive) : "자기상관" 이라고 칭한다. - 이전의 값이 이후의 값에 영향을 미치고 있는 상황(관계)
* MA(Moving Average) : "이동평균"이라고 칭한다. - 특정 변수의 평균값이 지속적으로 증가한거나 감소하는 추세(추이)
📍 정상성(stationary)과 비정상성(Non-stationary) * 정상성 - 평균과 분산이 일정한 형태
* 비정상성 - 평균과 분산이 일정하지 않은 형태 - 시간에 따라 평균 수준이 다르거나, 특징적 패턴(Trend)이나 계절성(Seasonality)에 영향을 받는 형태 - 예시 데이터 형태 : 겨울에 난방비 증가, 여름에 아이스크림 판매량 증가 등
- 비정상성 데이터는 예측 범위가 너무 다양하고 많기 때문에 고려해야할 특성들이 많다. - 이에, 비정상성 데이터를 정상성으로 변환하여 분석을 진행한다. - 정상성으로 분석을 진행하며, 예측범위가 일정하게 줄어들고, 성능이 개선되는 효과를 발휘함
📍 비정상성을 정상성으로 변환하는 방법들 - 평균의 정상화를 위한 차분 사용 - 분산의 안정화를 위한 로그 변환 사용 - 제곱/제곱근 변환 가용 - 이외
* 차분 : 비정상성을 정상성으로 만들기 위해 관측값들의 차이를 계산하여 사용하게 됨
시계열 정상성 확인하기 - ADF 테스트
📍 ADF 테스트(Augmented Dickey-Fuller Test) - 시계열 데이터의 정상성 여부를 통계적인 정량 방법으로 검증하는 방법 - 귀무가설과 대립가설에 따라 결정됨 - 귀무가설 : 기존 연구이론 - 대립가설 : 신규 연구이론(우리가 하고자 하는 것) - 귀무가설과 대립가설의 보편적 기준 > p-value < 0.05(증감 가능) : p-value < 0.05이면, 귀무가설 기각, 대립가설 채택 : p-value > 0.05이면, 귀무가설 채택(연구 방향을 수정해야 함) - 시계열 분석에서는 정상성과 비정상성 데이터의 형태를 구분하는 용도로 사용됨 - ADF 테스트 라이브러리 : statsmodels 패키지의 dfuller 라이브러리 사용
''' ADF 라이브러리 '''
from statsmodels.tsa.stattools import adfuller
''' 원본(수정종가) 데이터를 이용해서 ADF 테스트 하기 '''
result = adfuller(data.values)
result
p-value 추출하기 - ADF 결과의 1번째 값이 > p-value 값임
print(f"p-value : {result[1]}")
💡 해석 - p-value < 0.05을 만족하지 않으므로, 귀무가설을 기각 할 수 없음. 즉, 유의미 하지 않음 - 따라서, 구글 주식 데이터는 "비정상성" 데이터이며, 정상성으로 만들기 위한 차분 처리가 필요함 - p-value의 값이 0.827로 0.05보다 크므로... << 이렇게 작성하면 안됨
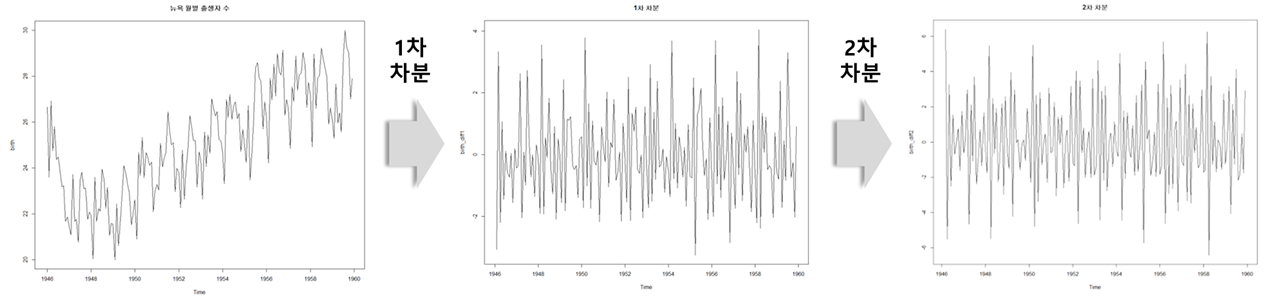
1d(1차) 차분 계산하기 - 1d(1차) : 1칸씩 이동하면서 이전과 현재의 차이값을 사용함 - 사용함수 : diff() - 차분을 계산하게되면, 최초 또는 [차분의 이동 거리]에 따라서 Nan이 발생 > Nan은 제거하고 사용함
dff1 = data.diff().dropna()
dff1
차분 결과 데이터 시각화 하기
dff1.plot(figsize=(15, 5))
plt.title("차분 결과 데이터 시각화")
plt.show()
차분 결과 데이터를 이용하여 정상성 여부 확인하기 - ADF 테스트 하여, p-value < 0.05 확인하기
💡 해석 - p-value < 0.05을 만족하므로, 유의미하다. - 즉, 귀무가설을 기각하고 대립가설을 채택 - 시계열 분석에서는 차분 처리를 통해 정상성 데이터로 변환되었으며, - 이후, ARIMA 분석을 통해 진행이 가능한 것으로 증명 되었음 - 사용된 차분은 1차 차분을 수행하여 증명하였음
차분 설명 이미지 - 차분을 할수록 정상성을 띄게 됨 - 그러나 너무 많은 차분은 오히려 비정상성을 띄게 할 수 있음 - 적절한 차수를 찾아서 차분을 진행해야 함(= 하이퍼파라미터 조정)
ARIMA 모델의 모수(하이퍼파라미터 찾기)
📍 ARIMA 모델에서 사용되는 중요한 3개의 하이퍼파라미터 - p, d, q - ARIMA(AR, MA, ARMA) 모델을 사용하기 위해서는 AR(자기회귀모형, p), 차분(d), MA(이동평균모형, q) 값을 결정해야 함
📍 결정 방법 1. ACF plot과 PACF plot을 통해 모수(하이퍼파라메터)를 결정할 수 있음 → 현재 값이 과거 값과 어떤 관계(relationship)가 있는지를 보여주는 그래프로 확인 2. pmdarima 라이브러리의 ndiffs, auto_arima 함수를 사용하여 모수(하이퍼파라미터) 결정할 수 있음 → 주로 auto_arima 함수를 사용함
(방법 - 1) ACF plot과 PACF plot을 통해 모수(하이퍼파라메터)를 결정
''' 사용 라이브러리 '''
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
''' 실제 원본 데이터를 이용해서 > ACF 및 PACF 시각화 하기 '''
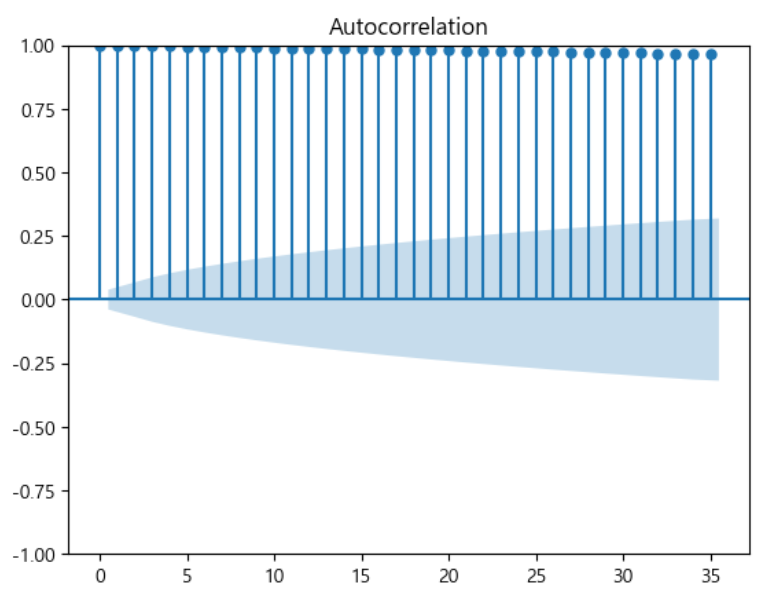
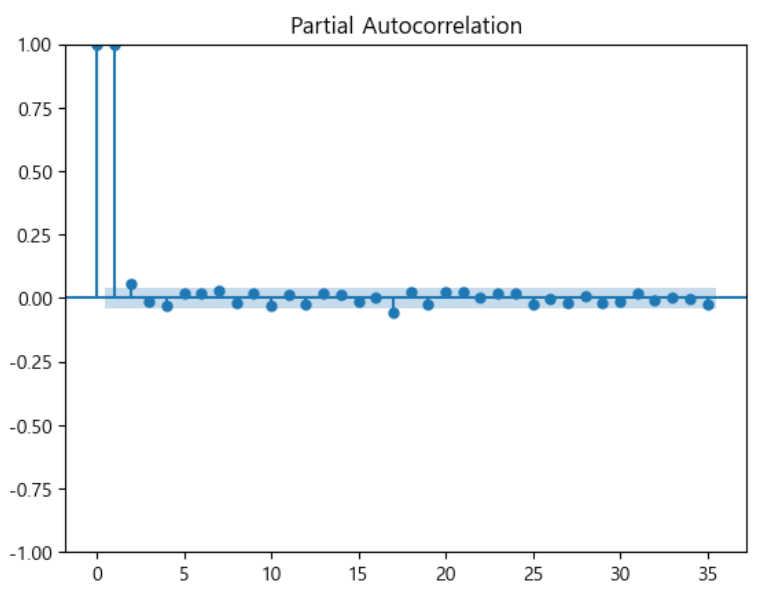
plot_acf(data)
plot_pacf(data)
plt.show()
💡 해석
< ACF plot > - ACF plot에서 막대그래프가 천천히 감소되는 것으로 보임 - 이는 주식 데이터가 주기에 따라 일정하지 않은 비정상 데이터로 판단한다.
< PACF plot > - 첫값을 제외한 1개 이후 파란 박스에 들어가면서, 막대 그래프가 끊기는 것으로 보임 - 이는 자기회귀모형(AR)의 결과값이 1개 이후인, 즉 p는 1인 값을 활용하는 것이 적절하다는 의미임 - 이동평균(MA)의 값은 AR과의 차이값이 0이 되도록 하는 것이 일반적임 - 따라서, MA는 1이 적절함을 의미함
(방법 - 1) 1차 차분데이터로 ACF 및 PACF 시각화 하기
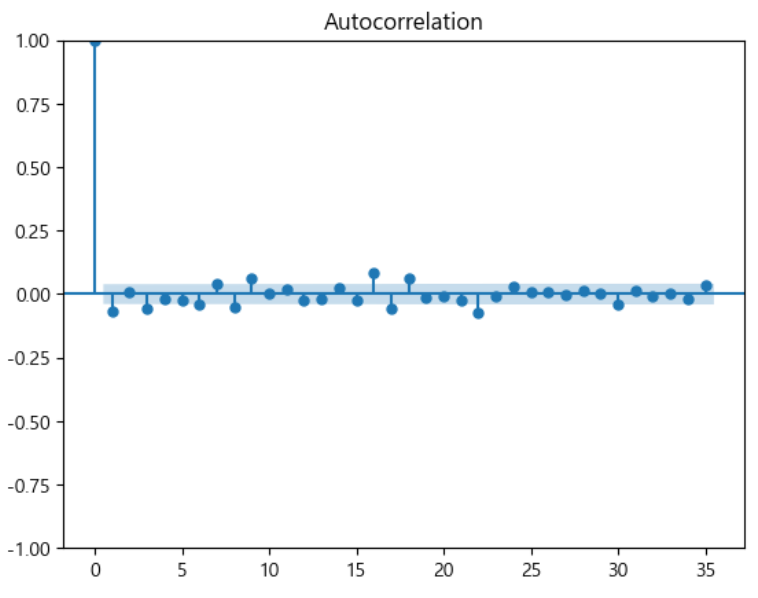
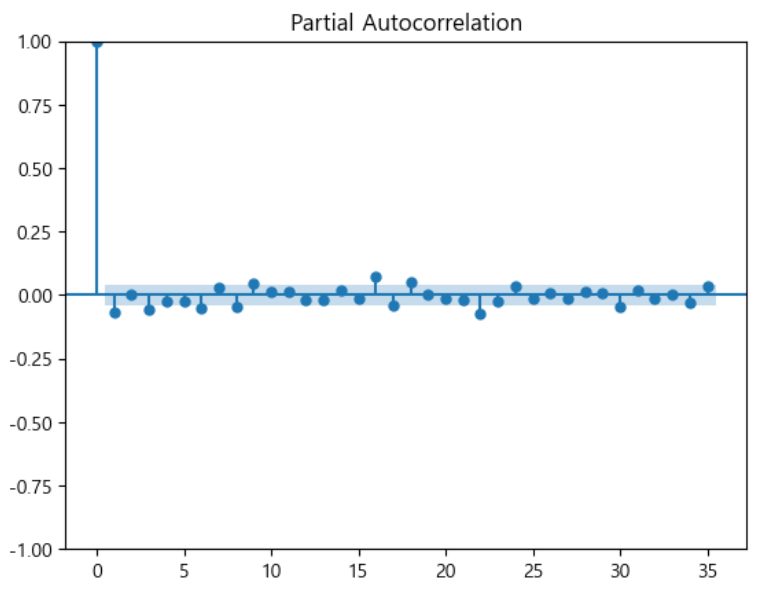
plot_acf(dff1)
plot_pacf(dff1)
plt.show()
📍 결론 - AR(p) = 1, d = 1, MA(q) = 1이 적절 - 이때, MA(q)값은 AR - MA값을 사용하기도 한다. (q=0) - MA값은 AR - MA를 사용
(방법 - 2)pmdarima 라이브러리의 ndiffs, auto_arima 함수를 사용하여 모수(하이퍼파라미터) 결정
(방법 - 2)ndiffs 함수
'''
사용 라이브러리
- 라이브러리 설치해야함 : pip install pmdarima
'''
import pmdarima as pm
from pmdarima.arima import ndiffs
'''
ndiffs 방법 : 차수를 결정하는 함수
- data : 원본 데이터
- alpha : 차분 횟수를 결정하는데 사용할 p-value(유의수준)
- test : 차분 획수를 결정하는데 사용할 테스트 방법
: 주로 adf 테스트 방법을 사용 (kpss 테스트 방법도 있으나, 거의 사용안함)
- max_d : 최대 차분 횟수를 제한함(이 범위 내에서 가장 적절한 차수를 결정)
'''
n_diffs = ndiffs(data, alpha=0.05, test="adf", max_d=6)
print(f"결정된 차수 : {n_diffs}")
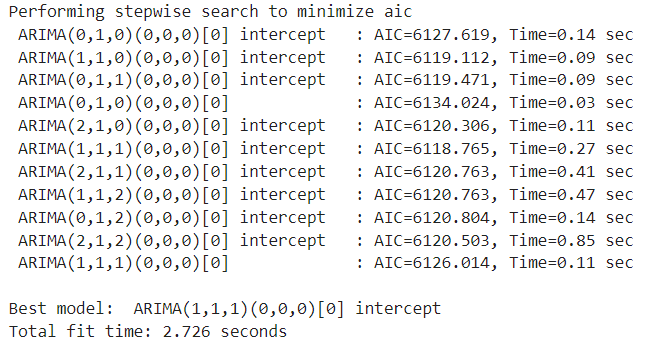
(방법 - 2)auto_arima 함수 - auto_arima 함수 사용 : p, d, q 값을 모두 추출해 준다. - y = 데이터 원본 - d = 차분의 차수, 이를 지정하지 않으면 실행 시간이 매우 길어짐(기본값 None) - start_p(기본값 2), max_p(기본값 5) : AR(p)를 찾기 위함 범위(start_p에서 max_p까지 수행) - start_q(기본값 2), max_q(기본값 5) : AR(q)를 찾기 위함 범위(start_q에서 max_q까지 수행) - m : 계절적 특성이 있을 때 사용하는 매개변수(기본값 1) > 차수를 의미함 - seasonal : 계절성 특성이 있을 때 사용(기본값 True) : 계절성 특성이 있을 때 (True) > m의 값은 계절적 특성의 범위 차수 지정(보통 3) : 계절성 특성이 없을 때 (False) > m은 1을 보통 사용 - stepwise : 최적의 모수를 찾기 위한 알고리즘을 사용할지 여부 (최적의 모수 찾기 알고리즘 : 힌드만-칸다카르 알고리즘이 적용됨) - trace : 결과 출력 여부(기본값 False)
new_Date 컬럼의 데이터를 이용해서, 0000-00(년-월) 단위로 추출하여, YM 컬럼 생성하기
''' 년-월 단위로 추출해서 YM 컬럼 생성하기 '''
df["YM"] = df["new_Date"].dt.to_period(freq="M")
''' 년-월-일 단위로 추출해서 YMD 컬럼 생성하기 '''
df["YMD"] = df["new_Date"].dt.to_period(freq="D")
new_Date 컬럼을 인덱스로 지정하기
df.set_index("new_Date", inplace=True)
df 데이터프레임의 0번째 행의 값을 추출
'''
df["2015-07-02"]
>> 이건 불가능 !! 인덱스가 RangeIndex가 아니면 직접 접근이 안되기 때문에 오류 발생
>> loc 또는 iloc를 사용해야함
'''
df_0 = df.iloc[0]
df_1 = df.loc["2015-07-02"]
df_0, df_1
인덱스 2016-06-29 ~ 2018-06-27까지의 행 조회하기
df.loc["2016-06-29":"2018-06-27"]
df 변수로 csv 파일 새로 불러들이고, new_Date 컬럼 생성 - Date 컬럼을 날짜 타입으로 변환해서 사용