1. 다음 보기 중 슈퍼/서브타입 데이터 모델의 변환타입에 대한 설명으로 옳은 것은?
1) One To One이란 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성하고 테이블의 수가 많아진다.
2) Plus Type은 하나의 테이블을 생성하는 것으로 조인(Join)이 발생하지 않는다.
3) Plus Type은 슈퍼+서브타입 형식으로 데이터를 처리하는 경우로 조인성능이 우수하여
Super Type과 Sub Type변환 시에 항상 사용된다.
4) One To One type은 조인성능이 우수하기 때문에 관리가 편리하다.
정답
정답 : 1번
슈퍼/서브 타입 데이터 모델의 변환
데이터량이 소량일 경우 성능에 영향을 미치지 않기 때문에 데이터처리의 유연성을 고려하여 1:1 관계를 유지한다.
그러나 데이터용량이 많아지는 경우, 해당 업무적인 특징이 성능에 민감한 경우는 트랜잭션이 해당 테이블에 어떻게 발생되는지에 따라 3가지 변환방법을 참조하여 상황에 맞게 변환하도록 해야 한다.
- One To One Type : 개별로 발생되는 트랜잭션에 대해서는 슈퍼,서브 개별 테이블로 구성된다.
>> 테이블 수 많음, 조인 많음, 관리 어려움
- Plus Type : 슈퍼타입 + 서브타입에 대해 발생되는 트랜잭션에 대해서 는 슈퍼 + 서브타입 테이블로 구성된다.
>> 조인 발생, 관리 어려움
- Single Type (All in One 타입) : 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성된다.
>> 조인 성능 좋음, 관리 편함, I/O성능 나쁨
2. 다음 보기 중 해시조인(Hash Join)에 대한 설명으로 옳지 않은 것은?
1) 해시조인은 두 개의 테이블 간에 조인을 할 때 범위검색이 아닌 동등조인(EQUI-Join)에 적합한 방식이다.
2) 작은 테이블(Build Input)을 먼저 읽어서 Hash Area에 해시 테이블을 생성하는 방법으로 큰 테이블로
Hash Area를 생성하면 과다한Sort가 유발 되어 성능이 저하될 수 있다.
3) 온라인 트랜잭션 처리(OLTP)에 유용하다.
4) 해시조인은 수행 빈도가 낮고 수행시간이 오래 걸리는 대용량 테이블에 대한 조인을 할 때 유용하다.
정답
정답 : 2번
- NL Join : 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행하고, 랜덤 액세스 방식으로 데이터 읽는다. (대용량 데이터 처리 시 불리, 유니크 인덱스를 이용하여 소량 테이블 조인할 때 유리함)
- Sort Merge Join : 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행하고 스캔 방식으로 데이터를 읽음. (대용량 데이터 처리 시 성능상 불리함)
- Hash Join : 조인 칼럼을 기준으로 동일한 해시값을 갖는 데이터의 실제값을 비교하며 조인한다. NL Join의 랜덤 액세스 문제와 SMJ의 정렬 작업 부담을 해결하기 위한 대안으로 등장했다. (선행 테이블이 작을때 유리, 별도의 공간 필요)
| 방 법 | 설 명 |
| 중첩 반복 조인 (Nested Loop Join) |
- 좁은 범위에 유리 - 유리순차적으로 처리하며, Random Access 위주 - 후행(Driven) 테이블에는 조인을 위한 인덱스가 생성되어 있어야 함 - 실행속도 = 선행 테이블 사이즈 * 후행 테이블 접근횟수 |
| 색인된 중첩 반복 조인, 단일 반복 조인 (Single Loop Join) |
- 후행(Driven) 테이블의 조인 속성에 인덱스가 존재할 경우 사용 - 선행 테이블의 각 레코드들에 대하여 후행 테이블의 인덱스 접근 구조를 사용하여 직접 검색 후 조인하는 방식 |
| 정렬 합병 조인 (Sort Merge Join) |
- Sort Merge 조인은 해당 테이블의 인덱스가 없을때 수행이 된다. - 테이블을 정렬(Sort) 한 후에 정렬된 테이블을 병합(Merge) 하면서 조인을 실행한다. - 조인 연결고리의 비교 연산자가 범위 연산( >, < )인 경우 Nested Loop 조인보다 유리 - 두 결과집합의 크기가 차이가 많이 나는 경우에는 비효율적 |
| 해시 조인 (Hash Join) |
- 해시(Hash)함수를 사용하여 두 테이블의 자료를 결합하는 조인 방식 - Nested Loop 조인과 Sort Merge 조인의 문제점을 해결 - 대용량 데이터 처리는 상당히 큰 hash area를 필요로 함으로, 메모리의 지나친 사용으로 오버헤드 발생 가능성 |
3. 다음 파티션에 대한 설명으로 틀린 것을 고르시오.
1) RANK() OVER (PARTITION BY JOB ORDER BY 급여 DESC) JOB_RANK
#직업별 급여가 높은 순서대로 부여되고 동일한 순위는 동일한 값이 부여 된다.
2) SUM(급여) OVER (PARTITION BY MGR ORDER BY 급여 RANGE UNBOUNDED PRECEDING)
#RANGE는 논리적 주소에 의한 행 집합을 의미하고 MGR별 현재 행부터
파티션내 첫번째 행까지 급여의 합계를 계산한다.
3) AVG(급여) OVER (PARTITION BY MGR ORDER BY 날짜 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING))
#각 MGR 별로 앞의 한건, 현재 행, 뒤의 한건 사이에서 급여의 평균을 계산한다.
4) COUNT(*) OVER (ORDER BY 급여) RANGE BETWEEN 10 PRECEDING AND 300 FOLLOWING)
#급여를 기준으로 현재 행에서의 급여의 10에서 300사이의 급여를 가지는 행의 수를 COUNT
정답
정답 : 3번
3번은 각 MGR별로 급여의 평균을 계산하기 전에 날짜를 기준으로 정렬을 수행한 다음에 급여의 평균을 계산한다.
즉, 각 MGR 파티션내에서 날짜 기준으로 정렬을 수행하였을 때, 파티션 내에서 앞의 한 건, 현재 행 뒤의 한 건 사이 급여의 평균을 계산한다.
4. 아래의 테이블들에 대해서 SQL문을 수행하였을 때의 결과 값은?
[TEST29_1]
COL
----
1
2
3
4
[TEST29_2]
COL
----
2
NULL
[SQL]
SELECT COUNT(*)
FROM TEST29_1 A
WHERE A.COL NOT IN (SELECT COL FROM TEST29_2);
-----------------------------------------------------
1) 0
2) 1
3) 3
4) 6
정답
정답 : 1번
NOT IN문 서브쿼리의 결과 중에 NULL이 포함되는 경우 데이터가 출력되지 않는다.
X IN (A, B) --> X = A OR X=BX NOT IN (A, B) --> NOT(X = A OR X = B) --> X != A AND X !=B
B를 NULL로 바꾸면
X NOT IN (A, NULL) --> NOT(X = A OR X = NULL ) --> X != A AND X != NULL
X != NULL 조건은 NULL을 비교하므로 항상 거짓이 됨.
항상 거짓인 조건이 AND로 연결되니 전체 조건은 참이 될 수 없다.
5. 다음 중 보기의 테이블을 설계할 사항으로 가장 적절한 것은?
- 개인 고객과 법인 고객이 있고 각 고객 데이터는 공통 속성을 가지고 있다.
- 각각의 고객 데이터에서만 사용되는 개별 속성도 있다.
- 로그인 관리는 동일하게 관리된다.
- 법인 고객과 개인 고객 중 개인 고객의 비율이 98%를 차지한다.
- 개인 고객에 대한 사용이 압도적으로 많다.
-------------------------------------------------------------------------
1) 통합하여 하나의 테이블을 만든다. (All in One)
2) 공통 속성을 중복으로 두어 슈퍼-서브 타입으로 한다. (슈퍼-서브타입)
3) 공통 속성을 별도로 두고 개인 고객과 법인 고객도 별도의 테이블로 생성한다. (1:1)
4) 위 보기 모두 성능 조절을 위한 방법으로 부적절한다.정답
정답 : 2
해설 : 슈퍼/서브타입 데이터의 특징은 공통점과 차이점을 고려하여 효과적으로 표현할 수 있다는 것이다.
즉, 공통의 부분을 슈퍼타입으로 모델링하고 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서는 별도의 서브엔터티로 구분하여 업무의 모습을 정확하게 표현하면서 물리적인 데이터 모델로 변환을 할 때 선택의 폭을 넓힐 수 있는 장점이 있다.
6. 주어진 테이블에서 아래와 같은 결과를 반환하는 SQL문을 고르시오.
[SQLD_33_12]
DNAME YEAR SAL
------------------------
경영지원부 2010 4900
경영지원부 2011 5000
경영지원부 2012 5100
인사부 2010 4800
인사부 2011 4900
인사부 2012 5000
[RESULT]
DNAME YEAR SUM(SAL)
----------------------------
인사부 2010 4800
인사부 2011 4900
인사부 2012 5000
인사부 14700
경영지원부 2010 4900
경영지원부 2011 5000
경영지원부 2012 5100
경영지원부 15000
297001)
SELECT DNAME, YEAR, SUM(SAL)
FROM SQLD_33_12
GROUP BY ROLLUP((DNAME, YEAR), NULL);
2)
SELECT DNAME, YEAR, SUM(SAL)
FROM SQLD_33_12
GROUP BY ROLLUP(DNAME, (DNAME, YEAR));
3)
SELECT DNAME, SUM(SAL)
FROM SQLD_33_12
GROUP BY ROLLUP((DNAME, YEAR));
4)
SELECT DNAME, SUM(SAL)
FROM SQLD_33_12
GROUP BY ROLLUP(DNAME, YEAR, (DNAME, YEAR));
정답
정답 : 2
ROLLUP은 단계별 합계
우측 항목을 하나씩 단계별로 제거
1. ROLLUP (DNAME, (DNAME, YEAR))
>> (DNAME, YEAR)를 한 묶음으로 처리하여 합계 도출
2. ROLLUP (DNAME, ())
>> DNAME 합계 도출
3. ROLLUP ()
>> () 전체 합계 도출
7. 다음 주어진 테이블에 대해서 아래의 SQL문을 수행하였을 때의 결과로 올바른 것은?
[SQLD_32_1]
N1 V1
-------
1 A
2
3 B
4 C
[SQLD_32_2]
N1 V1
-------
1 A
2
3 B
[SQL]
SELECT SUM(A.N1)
FROM SQLD_32_1 A,
SQLD_32_2 B
WHERE A.V1 <> B.V1;
----------------------------------------
1) 10
2) 30
3) 12
4) 8
정답
8. 주어진 테이블에서 날짜 값을 2020, 02로 분리하여 추출하도록 아래 SQL문의 ( )을 완성하시오.
[SQLD_33_47]
COL1
--------
2020-2-1
[SQL]
SELECT EXTRACT(YEAR FROM SYSDATE),
LPAD(EXTRACT(month from sysdate),( ))
FROM SQLD_33_47;
정답
정답 : 2, '0'
EXTRACT(‘YEAR’|”MONTH’|’DAY’ from SYSDATE) : 날짜유형 데이터 추출
LPAD("값", "총 문자길이", "채움문자")
LPAD 함수는 지정한 길이만큼 왼쪽부터 채움문자로 채운다.
채움문자를 지정하지 않으면 공백으로 해당 길이만큼 문자를 채운다.
9. 아래의 보기를 만족하는 조인 기법은 무엇인가?
- 먼저 선행 테이블의 조건을 만족하는 행을 추출하여 후행 테이블을 읽으면서 조인을 수행한다.
- 랜덤 방식으로 엑세스 한다.
- 결과를 가능한 빨리 화면에 보여줘야 하는 온라인 프로그램에 적당하다.
정답
NESTED LOOP JOIN
10. SELECT NVL(COUNT(*), 9999) FROM TABLE WHERE 1 = 2 의 결과값은?
1) 9999
2) 0
3) NULL
4) 1
정답
정답 : 2
집계 함수에서 COUNT(*) 함수는 조건절이 거짓일 때 0을 반환한다.
11. 다음은 ABC증권회사의 회원정보를 모델링 한 것이다. 회원정보는 수퍼타입이고 개인회원과 법인회원 정보는 서브타입이다. 애플리케이션에 회원정보를 조회하는 경우는 항상 개인회원과 법인회원을 동시에 조회하는 특성이 있을 때 수퍼타입과 서브타입을 변환하는 방법으로 가장 올바른 것은?

1) ONE TO ONE
2) PLUS TYPE
3) SINGLE TYPE
4) 정답 없음
정답
정답 : 3번
항상 같이 조회한다고 했으므로 하나의 테이블로 통합해서 만드는 SINGLE TYPE 방법이 가장 올바른 방법이다.
수퍼타입과 서브타입의 변환 시에 가장 고려되어야 하는 것은 애플리케이션이 테이블을 어떻게 사용하는지 이다.
슈퍼/서브타입 데이터 모델의 변환타입 비교
| 구분 | One To One Type | Plus Type | Single Type |
| 특징 | 개별 테이블 유지 | 슈퍼+서브타입 테이블 | 하나의 테이블 |
| 확장성 | 우수함 | 보통 | 나쁨 |
| 조인성능 | 나쁨 | 나쁨 | 우수함 |
| I/O량 성능 | 좋음 | 좋음 | 나쁨 |
| 관리용이성 | 좋지않음 | 좋지않음 | 좋음(1개) |
| 트랜잭션 유형에 따른 선택방법 | 개별 테이블로 접근이 많은 경우 선택 | 슈퍼+서브 형식으로 데이터를 처리하는 경우 선택 | 전체를 일괄적으로 처리하는 경우 선택 |
12. 다음은 ABC증권회사의 데이터베이스 모델링이다. 모델링은 고객과 계좌간의 관계를 표현한 것이다. 다음의 보기 중에서 그 설명이 올바르지 않은 것은?

1) 계좌를 개설하지 않은 고객은 ABC증권 회사에 고객이 될 수가 없다.
2) 계좌번호는 전체 고객마다 유일한 번호가 부여된다.
3) 고객마스터와 계좌마스터의 관계는 식별관계이다.
4) 한 명의 고객에 하나의 고객등급만 부여된다.정답
정답 : 2번
테이블상의 계좌마스터의 식별자 속성이 계좌번호 + 고객번호이므로 전체 고객에게 유일한 번호가 할당되는것은아니다. 같은 계좌번호라도 다른 고객번호로 계좌마스터에서 고유한 레코드를 식별 할 수 있다.
즉, 고객별로 계좌번호가 같을수 있지만 (예: 고객 A, 계좌 123 / 고객 B, 계좌 123)
한 명의 고객의 계좌번호는 유일하다. (예: 고객 A, 계좌 123 / 고객 A, 계좌 124)
13. 식별자 중에서 비즈니스 프로세스에 의하여 만들어지는 식별자로 대체여부로 분리되는 식별자는 무엇인가?
1) 본질 식별자
2) 단일 식별자
3) 내부 식별자
4) 인조 식별자
정답
정답 : 1번
식별자 분류
대표성 여부
•주식별자 : 엔터티 내에서 각 어커런스를 구분할 수 있는 구분자, 타 엔터티와 참조관계를 연결할 수 있음
•보조식별자 : 어커런스를 구분할 수 있는 구분자이나 대표 성을 가지지 못해 참조관계 연결불가
스스로 생성여부
•내부식별자 : 스스로 생성되는 식별자 (본질식별자)
•외부식별자 : 타 엔터티로부터 받아오는 식별자
속성의 수
•단일식별자 : 하나의 속성으로 구성
•복합식별자 : 2개 이상의 속성으로 구성
대체 여부
•본질식별자 : 대체될 수 없는 식별자, 업무에 의해 만들어 지는 식별자
•인조식별자 : 대체 가능한 식별자, 인위적으로 만든 식별 자
14. 다음 중 문자에 대한 설명으로 부적절한 것은 무엇인가?
1) VARCHAR(가변길이 문자형)은 비교시 서로 길이가 다를 경우 서로 다른 내용으로 판단한다.
2) CHAR(고정길이 문자형)은 비교 시 서로 길이가 다를 경우 서로 다른 내용으로 판단한다.
3) 문자형과 숫자형을 비교 시 문자형을 숫자형으로 묵시적 변환하여 비교한다.
4) 연산자 실행 순서는 괄호, NOT, 비교연산자, AND, OR순이다.정답
정답 : 2번
CHAR는 길이가 서로 다르면 짧은 쪽에 스페이스를 추가하여 같은 값으로 판단한다. 같은 값에서 길이만 서로 다를 경우 다른 값으로 판단하는 것은 VARCHAR(가변길이 문자형 : 입력한 크기만큼 할당 )로 비교하는 경우이다.
데이터 유형
CHAR(s) : 고정 길이 문자열 정보 ‘AA’ = ‘AA ’
할당된 변수 값의 길이가 L이하 일 때 차이는 공백으로 채워짐
VARCHAR(s) : 가변 길이가 문자열 정보 ‘AA’ != ‘AA ’
할당된 변수 값의 길이의 최대값이 L인 문자열은 가능한 최대 길이로 설정
NUMERIC : 정수(L:전체 자릿 수), 실수(D:소수점 자릿수) 등 숫자 정보
DATE : 날짜와 시각 정보
15. 테이블의 칼럼을 변경하는 DDL문으로 올바른 것은?
TEST 테이블의 NAME 칼럼의 데이터 타입을
CHAR에서 VARCHAR로 변경하고
데이터 크기를 100으로 늘린다.(1)
ALTER TABLE TEST ALTER COLUMN NAME VARCHAR(100);
(2)
ALTER TABLE TEST MODIFY(NAME VARCHAR(100));
(3)
ALTER TABLE TEST ADD COLUMN NAME VARCHAR(100);
(4)
ALTER TABLE TEST ADD CONSTRAINT COLUMN NAME NAME VARCHAR(100);
정답
정답 : 2번
칼럼의 변경은 ALTER TABLE ~ MODIFY 문을 사용하면 된다. 칼럼은 데이터 타입 및 길이를 변경 할 수 있다.
추가(ADD), 삭제(DROP)
※ SQL Server 에선 1번이 정답이지만 따로 DBMS를 명시하지 않으면 기본적으로 ORACLE을 기준으로 생각
16. 다음 보기 중 서브쿼리에 대한 설명을 옳지 않은 것은?
1) 서브쿼리에서는 정렬을 수행하기 위해서 내부에 ORDER BY를 사용하지 못한다.
2) 메인 쿼리를 작성할 때 서브쿼리에 있는 칼럼을 자유롭게 사용할 수 있으면 편리하다.
3) 여러 개의 행을 되돌리는 서브쿼리는 다중행 연산자를 사용해야 한다.
4) EXIST는 TRUE와 FALSE만 되돌린다.정답
정답 : 2
서브쿼리에 있는 칼럼을 자유롭게 사용할수 없다.
서브쿼리 중에서 INLINE VIEW의 칼럼은 메인쿼리에서도 사용이 가능하다.
즉, 어떤 서브쿼리를 사용하느냐에 따라 사용가능여부가 달라지므로 자유롭게 사용할 수 없다.
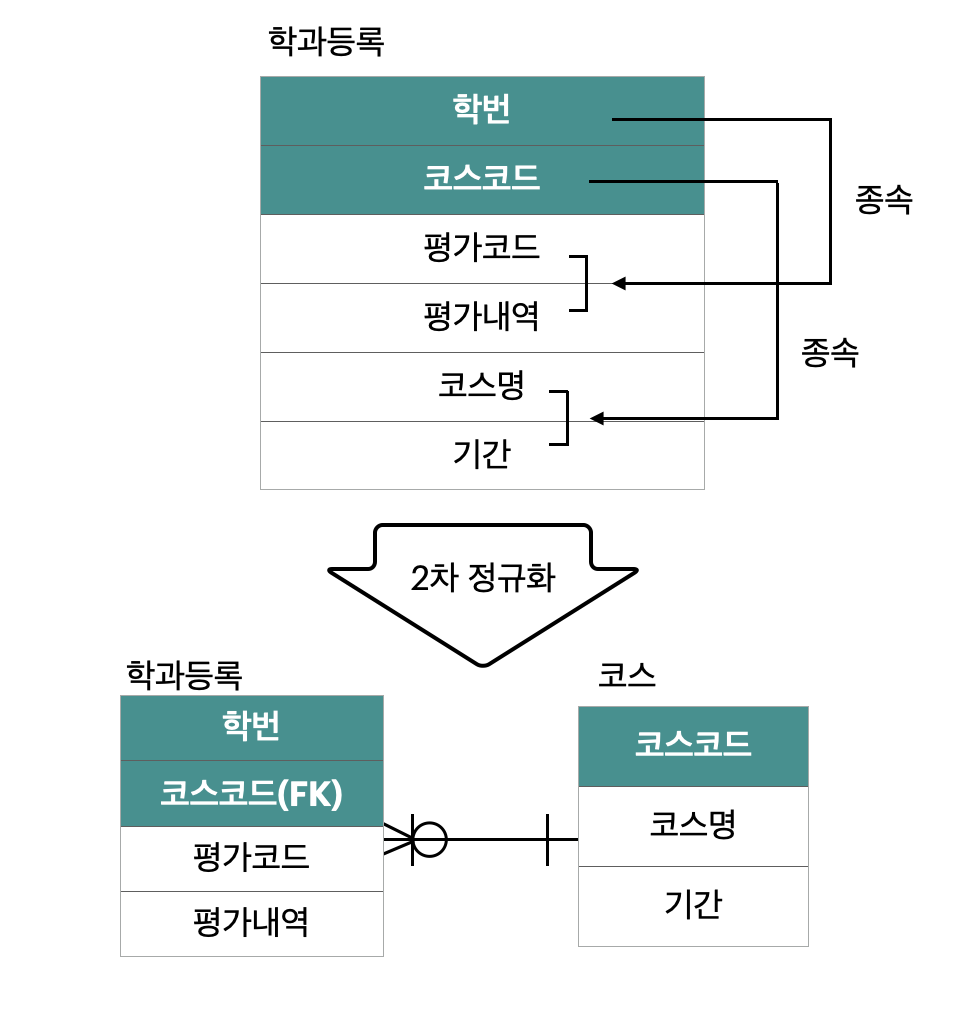
17. 아래의 ERD에서 3차 정규형을 만족할 때 학과등록 엔터티의 개수는 몇 개가 되는가?
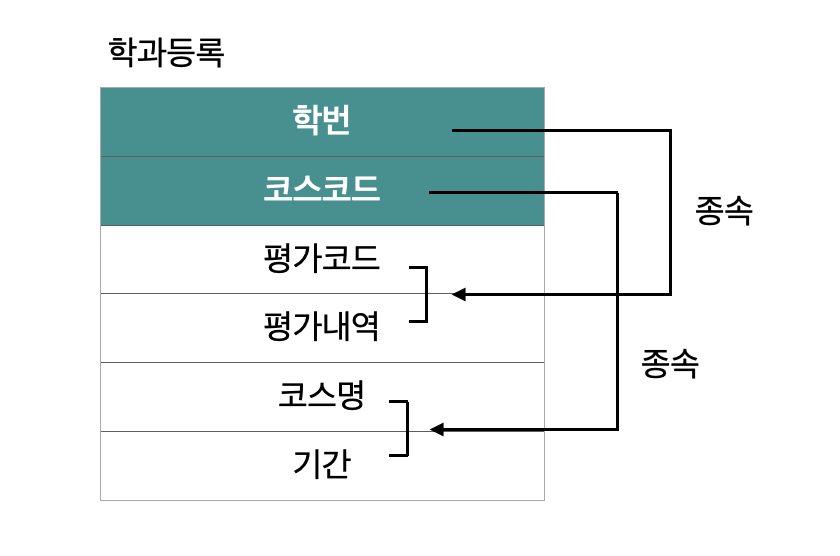
[조건]
가) 평가코드, 평가내역은 한번에 종속
나) 코스명, 기간은 코스코드에 종속
다) 평가코드, 평가내역은 속성 간 종속적 관계
[참고]
1차정규형 : 모든 속성은 반드시 하나의 값, 속성값의 중복 제거
2차정규형 : 식별자에 종속되지 않는 속성의 중복 제거
3차정규형 : 2차정규형을 만족하며 식별자 외 일반 칼럼간의 종속 존재 제거
정답
정답 : 3
2차 정규화 → 3차 정규화(종속 존재를 분해)
>> 학번, 코스코드(FK), 평가코드(FK) = 3개

18. 아래의 SQL1과 동일한 값을 반환하도록 SQL2의 빈칸에 서브쿼리 연산자를 작성하시오.
[SQLD39_50_1] [SQLD39_50_2]
COL1 COL2 COL1 COL2 COL3
100 200 100 200 1000
110 300 110 350 2000
120 400 120 400 3000
130 500 130 550 4000
[SQL1]
SELECT * FROM SQLD39_50_1 A
WHERE(A.COL1, A.COL2)
IN (SELECT B.COL1, B.COL2
FROM SQLD39_50_2 B
WHERE B.COL3 > 2000);
[SQL2]
SELECT * FROM SQLD39_50_1 A
WHERE ( )
(SELECT 1
FROM SQLD39_50_2 B
WHERE A.COL1 = B.COL1
AND A.COL2 = B.COL2
AND B.COL3 > 2000);
정답
정답 : EXISTS
SQL1 의 결과는 (120, 400)
SQL2 에 같은 결과를 반환하기 위해서는 빈칸에 EXISTS를 작성
EXISTS 연산자는 하위 쿼리에 레코드가 있는지 테스트 하는 데 사용
하위 쿼리가 하나 이상의 레코드를 반환하는 경우 TRUE 그렇지 않은 경우 FALSE
19. 주어진 SQL문의 빈칸에 올 수 있는 함수로 옳지 않는 것은?
[SQLD_34]
DEPT NAME SALARY
------------------------------
MARKETING A 30
SALES B 40
MARKETING C 40
SALES D 50
MANUFACTURE E 50
MARKETING F 50
MANUFACTURE G 60
SALES H 60
MANUFACTURE I 70
SELECT*FROM SQLD_34
WHERE SALARY ( );1) <= (SELECT MAX(SALARY) FROM SQLD_34 GROUP BY DEPT)
2) >= ANY(30,40,50,60,70)
3) <= ALL(30,40,50,60,70)
4) IN (SELECT SALARY FROM SQLD_34 WHERE DEPT = 'MARKETING')
정답
정답 : 1번
- 1번의 쿼리는 각 부서(DEPT)에 대해 멀티행을 반환한다. 그러나 <= 연산자는 오른쪽에 단일 값이 있어야 한다. 따라서 여러 값을 반환하는 이 서브쿼리를 직접 사용할 수 없다.
- 4번 쿼리의 IN 연산자는 오른쪽에 지정된 목록 중 하나와 일치하는 경우에 조건을 충족시키는 데 사용된다. 쿼리는 'MARKETING' 부서에 속하는 직원들의 급여를 반환하고 이 목록을 왼쪽에 있는 IN 연산자와 함께 사용하면, 왼쪽 테이블의 각 행의 급여가 해당 부서의 급여 목록 중 하나와 일치하면 조건을 충족시킨다.
단일행 서브쿼리
- 서브쿼리의 실행 결과가 항상 1건 이하인 서브쿼리
- 항상 비교연산자와 함께 사용된다.
- 비교연산자 뒤에는 단일행이 와야 하는데 뒤에 GROUP BY DEPT는 다중행 함수로 멀티행을 반환하여 에러가 발생함.
20. 아래의 ERD 에 대한 반정규화 기법으로 적절하지 않은 것은?
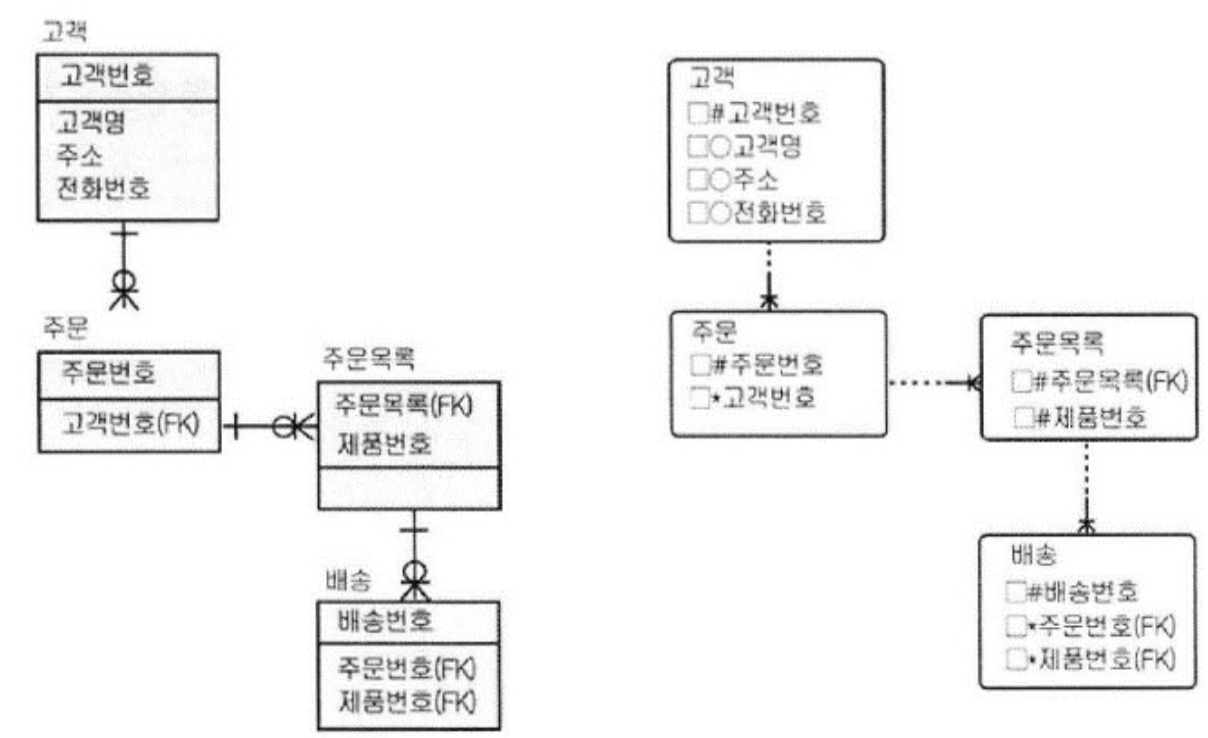
1) 배송 테이블에서 고객의 정보를 찾는 빈도가 높을 경우 고객과 배송 테이블의 관계를 추가하는 관계의 반정규화를 한다.
2) 주문목록 테이블에서 고객이 정보를 찾는 빈도가 높을 경우 고객과 주문 테이블의 비식별자 관계를 식별자 관계로 한다.
3) 주문 테이블에서 항상 고객명을 같이 조회하는 경우 고객 테이블의 고객명을 주문 테이블에 넣어 컬럼의 반정규화를 한다.
4) 주문과 주문목록, 배송 테이블의 모든 컬럼을 고객 (최상위 테이블) 테이블에 모두 넣는 반정규화를 한다.
정답
정답 : 4번
1번 : 중복관계 추가
2번 : PK에 의한 컬럼 추가
3번 : 중복컬럼 추가
4번 : 이력 테이블 추가
이력 테이블 중에서 마스터 테이블에 존재하는 레코드를 중복하여 이력 테이블에 존재시켜 성능 향상
마스터테이블을 이력테이블에 중복시켜야하는데 그 반대를 말하고 있다.
1 : M 관계인데 M의 자료를 1에다 넣을 수 없다.
21. 아래의 SQL을 ORACLE 과 SQL SERVER에서 수행할 때 SQL에 대해 틀린 설명은? (AUTO COMMIT은 FALSE로 설정)
<SCRIPT>
UPDATE SQLD_34_30 SET N1=3 WHERE N2=1;
CREATE TABLE SQLD_34_30_TEMP (N1 NUMBER);
ROLLBACK;1) SQL SERVER 의 경우 ROLLBACK 이 된 후 UPDATE 와 CREATE 구문 모두 취소된다
2) SQL SERVER 의 경우 ROLLBACK 이 된 후 SQLD_34_21_TEMP 는 만들어지지 않는다.
3) ORACLE 의 경우 ROLLBACK 이 된 후 UPDATE 와 CREATE 구문 모두 취소된다.
4) ORACLE 의 경우 UPDATE 는 취소되지 않는다.
정답
정답 : 3번
- SQL Server : 기본값이 AUTO COMMIT이지만 AUTO COMMIT을 False로 두면 DDL, DML 모두 ROLLBACK 가능
- Oracle : AUTO COMMIT이 없이 명시적으로 Commit을 해줘야 하나, DDL의 경우 명령문 수행과 동시에 COMMIT이 진행되어 ROLLBACK이 되지 않는다.
22. 주어진 ERD에서 오류가 나지 않는 SQL문을 고르시오.

1)
SELECT * FROM 계좌마스터
WHERE 회원번호 = (SELECT DISTINCT 회원번호 FROM 고객);
2)
SELECT * FROM 계좌마스터
WHERE 회원번호 IN (SELECT DISTINCT 회원번호 FROM 고객);
3)
SELECT 회원번호, 종목코드 FROM 일자별주문내역
WHERE 주문일자 EXISTS (SELECT DISTINCT 주문일자 FROM 계좌마스터);
4)
SELECT 회원번호, 종목코드 FROM 일자별주문내역
WHERE 주문일자 ALL (SELECT DISTINCT 주문일자 FROM 계좌마스터);
정답
정답 : 2번
1번
서브쿼리 결과가 여러개의 행이 리턴 되므로 오류가 발생한다
"=" 는 단일행 연산자로 서브쿼리의 결과가 반드시 하나만 리턴 되어야 한다.
3번
EXISTS 앞에 뭔가 있어서 오류
수정 > WHERE EXISTS
4번
ALL은 비교 연산자(=, >, <, <>, !=)가 필요하다.
앞에 뭔가 없어서 오류
수정 > WHERE 주문일자 = ALL
23. 아래의 SQL문을 수행한 결과로 잘못된 것은?
CREATE TABLE 주문 (
C1 NUMBER(10),
C2 DATE,
C3 VARCHAR(10),
C4 NUMBER DEFAULT 100
);
INSERT INTO 주문 (C1,C2,C3) VALUES (1, SYSDATE, 'TEST1');1) INSERT INTO 주문 VALUES(2, SYSDATE, 'TEST2');
2) DELETE 주문
3) DELETE FROM 주문;
4) UPDATE 주문 SET C1=1;
정답
정답 : 1번
데이터 값을 넣을 때 컬럼을 따로 지정하지 않으면 테이블의 모든 컬럼에 값을 넣어줘야 한다.
즉, INSERT INTO 주문 VALUES(2, SYSDATE, 'TEST2'); 여기선 C4에 대한 값을 넣지 않아서 오류가 난다.
24. 다음 ERD로 작성한 SQL문에서 오류가 발생하는 것은?
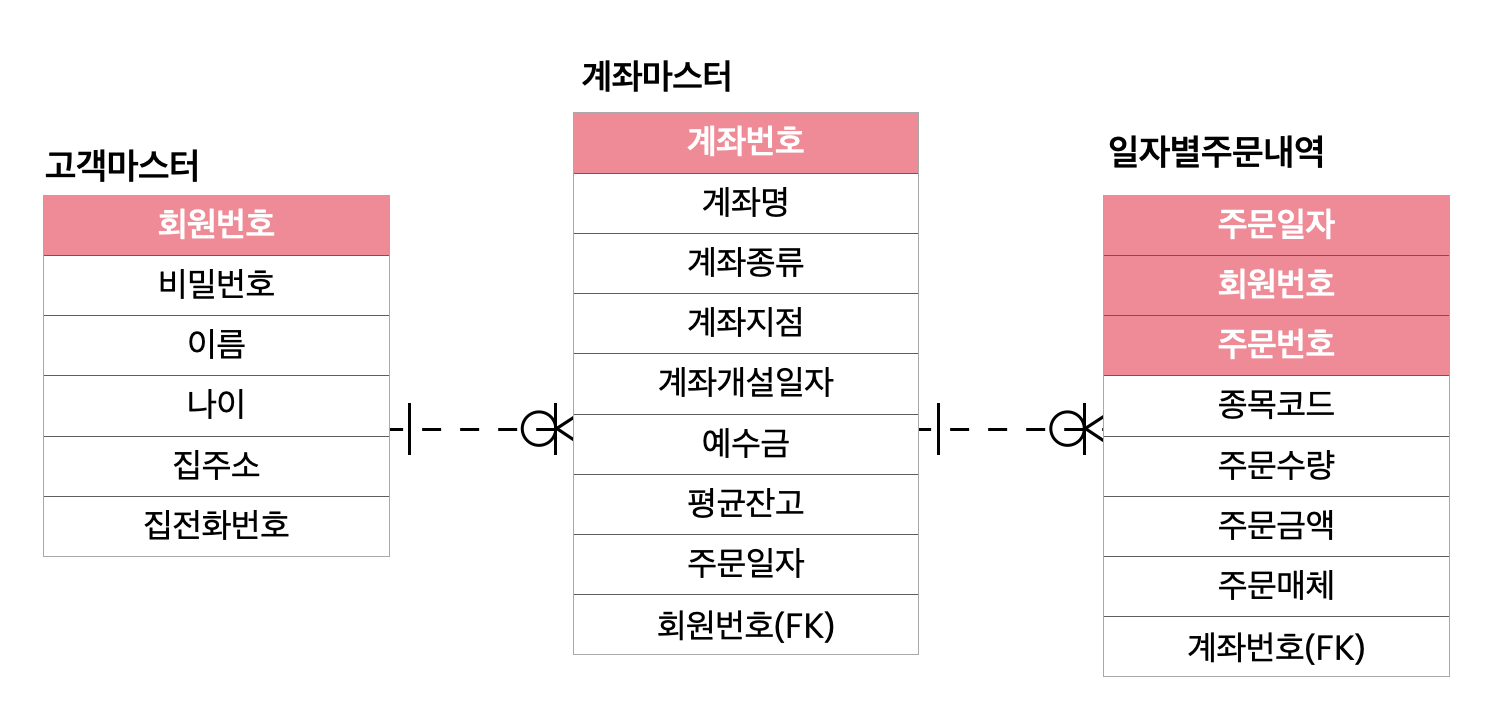
1)
SELECT (SELECT SUM(주문금액) FROM 일자별주문내역)
FROM 고객마스터 GROUP BY 회원번호;
2)
SELECT SUM(일자별주문내역.주문금액)
FROM 일자별주문내역
FULL OUTER JOIN 고객마스터
ON 고객마스터.회원번호 = 일자별주문내역.회원번호
GROUP BY 회원번호;
3)
SELECT SUM(일자별주문내역.주문금액)
FROM 고객마스터, 일자별주문내역
WHERE 고객마스터.회원번호 = 일자별주문내역.회원번호
GROUP BY 회원번호;
4)
SELECT SUM(주문금액)
FROM 일자별주문내역
WHERE EXISTS (SELECT*FROM 고객마스터
UNION ALL SELECT*FROM 일자별주문내역)
GROUP BY 회원번호;
정답
정답 : 4번
고객마스터와 일자별주문내역에 나오는 칼럼 수와 데이터 타입이 일치하지 않으므로 에러가 난다.
UNION 및 UNION ALL을 사용할 때 나오는 SQL문은 칼럼 수와 데이터 타입이 완전 일치해야 한다.
'Certificate > SQLD' 카테고리의 다른 글
| [SQLD] 기출문제 오답정리 2 (3) | 2023.11.15 |
|---|---|
| [SQLD] 2과목 2장 핵심정리 모아놓기 (1) | 2023.11.12 |
| [SQLD] 2과목 1장 핵심정리 모아놓기 (0) | 2023.11.05 |
| [SQLD] 단답형 정리 (0) | 2023.11.05 |
| [SQLD] 1과목 핵심정리 모아놓기 (0) | 2023.11.05 |