728x90
반응형
분류모델_선정하기
사용할 라이브러리 정의
''' 데이터 처리 '''
import pandas as pd
''' 데이터 분류 '''
from sklearn.model_selection import train_test_split
''' 하이퍼파라미터 튜닝 '''
from sklearn.model_selection import GridSearchCV
''' 사용할 분류모델들 '''
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import HistGradientBoostingClassifier
from xgboost import XGBClassifier
''' 데이터 스케일링 : 정규화 '''
from sklearn.preprocessing import StandardScaler
''' 평가 '''
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
''' 오차행렬(혼동행렬) '''
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
데이터 셋
data = pd.read_csv("./data/08_wine.csv")
data.info()
data.describe()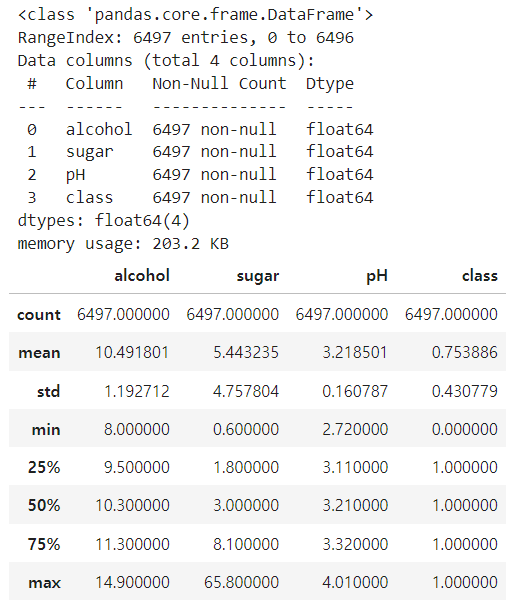
데이터프레임에서 독립변수와 종속변수로 데이터 분리하기
'''
사용할 변수
- 독립변수 : X
- 종속변수 : y
'''
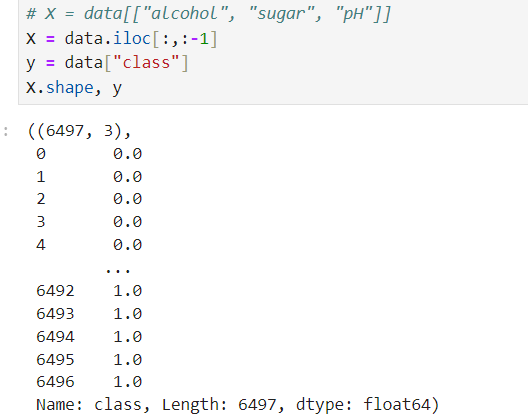
# X = data[["alcohol", "sugar", "pH"]]
X = data.iloc[:,:-1]
y = data["class"]
X, y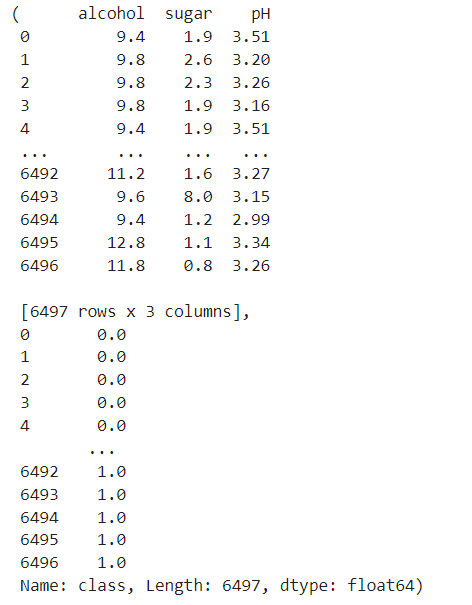
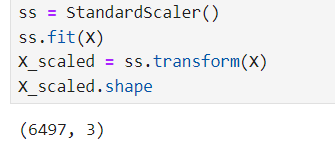
정규화
'''
사용할 변수
- 독립변수 정규화 : X_scaled
'''
ss = StandardScaler()
ss.fit(X)
X_scaled = ss.transform(X)
X_scaled
훈련:검증:테스트 = 6:2:2로 분리하기
'''
사용할 변수
- X_train, y_train
- X_val, y_val
- X_test, y_test
'''
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.4, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_test, y_test, random_state=42, test_size=0.5)
print(f"{X_train.shape} / {y_train.shape}")
print(f"{X_val.shape} / {y_val.shape}")
print(f"{X_test.shape} / {y_test.shape}")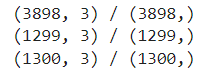
훈련에 사용할 모든 모델 생성하기
rf_model = RandomForestClassifier()
et_model = ExtraTreesClassifier()
gd_model = GradientBoostingClassifier()
hg_model = HistGradientBoostingClassifier()
xgb_model = XGBClassifier()
''' 리스트 타입의 변수에 모델 객체 담기 '''
models = [rf_model, et_model, gd_model, hg_model, xgb_model]
models
''' 모델 이름을 리스트 변수에 담기 '''
model_name = [rf_model.__class__.__name__,
et_model.__class__.__name__,
gd_model.__class__.__name__,
hg_model.__class__.__name__,
xgb_model.__class__.__name__]
model_name
GridSearchCV를 위한 하이퍼파라미터 매개변수 정의
- n_estimators()
- 트리의 갯수를 의미함
- 트리의 갯수를 늘리게 되면 모델의 복잡성이 증가됨
- 과적합을 방지하고 더 좋은 성능을 낼 수 있음
- 설정값 : 제한은 없으나, 50, 100 ~ 1000 사이의 값을 주로 사용
- rf, xt, gb, xgb에서 사용가능
- hg에서는 max_iter() 함수를 사용함 - max_depth()
- 각 트리의 최대 깊이를 의미함(root 노드는 제외)
- 트리의 최대 깊이가 길어질 수록 모델의 복잡성이 증가함
- 설정값 : 제한 없음, 주로 None ~ 50 사이의 값이 주로 사용됨
- 모든 모델 사용가능 - min_samples_split()
- 노드를 분할하기 위한 최소한의 갯수를 의미함
- 설정값: 제한없음, 2 ~ 10 사이의 값이 주로 사용됨
- rf, xt, gb 모델만 사용가능 - min_samples_leaf()
- 리프 노드 (결정노드)의 최소한의 샘플 수를 의미함
- 설정값 : 제한없음, 1 ~ 10 사이의 값이 주로 사용됨
- rf, xt, gb, hg 모델 사용가능
- xgb 모델은 min_child_weight() 함수 사용
모든 모델에 대해서 GridSearchCV 수행 후 정확도 평가하기
''' RF, GB에서 특성중요도 추출 라이브러리 '''
from sklearn.feature_selection import SelectFromModel
''' HGB에 대한 특성중요도 추출 라이브러리 '''
from sklearn.inspection import permutation_importance
''' 최종 결과는 DataFrame에 저장하여 출력 '''
df = pd.DataFrame()
for model, modelName in zip(models, model_name):
print(f"------------------{modelName} 시작------------------")
''' ------------------하이퍼파라미터 매개변수 정의하기------------------ '''
if modelName == "HistGradientBoostingClassifier" :
param_grid = {
"max_iter" : [50, 100],
"max_depth" : [None, 10],
"min_samples_leaf" : [1, 2, 4]
}
elif modelName == "XGBClassifier" :
param_grid = {
"n_estimators" : [50, 100],
"max_depth" : [None, 10],
"min_child_weight" : [1, 2, 4]
}
else :
param_grid = {
"n_estimators" : [50, 100],
"max_depth" : [None, 10],
"min_samples_split" : [2, 5],
"min_samples_leaf" : [1, 2, 4]
}
''' GridSearchCV 수행하기 '''
grid_search = GridSearchCV(model, param_grid, cv=5, scoring="accuracy")
# print(grid_search)
grid_search.fit(X_train, y_train)
''' 최적의 모델 받아오기 '''
model = grid_search.best_estimator_
#print(model)
''' ------------------훈련 및 검증정확도 확인하기------------------ '''
''' 정확도를 확인하기 위하여 예측하기 '''
train_pred = model.predict(X_train)
val_pred = model.predict(X_val)
''' 정확도 확인하기 '''
train_acc = accuracy_score(y_train, train_pred)
val_acc = accuracy_score(y_val, val_pred)
''' ------------------최종 테스트 평가하기------------------ '''
''' 테스트 데이터로 예측하기 '''
test_pred = model.predict(X_test)
''' 정확도 확인하기 '''
test_acc = accuracy_score(y_test, test_pred)
''' 정밀도 확인하기 '''
test_pre = precision_score(y_test, test_pred)
''' 재현율 확인하기 '''
test_rec = recall_score(y_test, test_pred)
''' F1 확인하기 '''
test_f1 = f1_score(y_test, test_pred)
''' 오차행렬도(혼동행렬) '''
cm = confusion_matrix(y_test, test_pred)
''' 데이터 프레임에 담기 '''
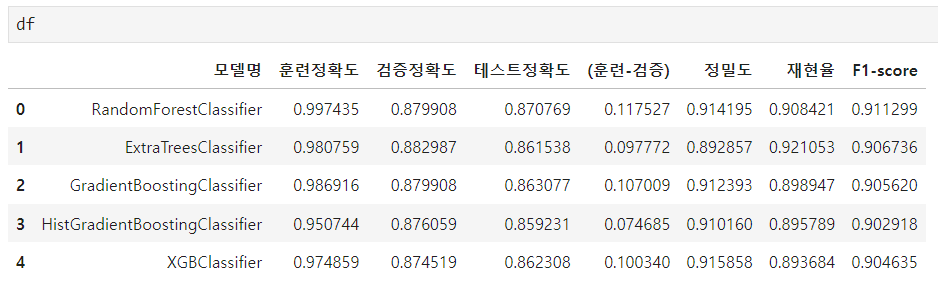
df_temp = pd.DataFrame({
"모델명" : [modelName],
"훈련정확도" : [train_acc],
"검증정확도" : [val_acc],
"테스트정확도" : [test_acc],
"(훈련-검증)" : [train_acc - val_acc],
"정밀도" : [test_pre],
"재현율" : [test_rec],
"F1-score" : [test_f1]
})
''' 하나의 데이터프레임에 추가하기 '''
df = pd.concat([df, df_temp], ignore_index=True)
print(df)
''' ------------------특성 중요도------------------ '''
''' 독립변수의 특성이름 추출하기 '''
columnNames = X.columns
''' 특성중요도를 담을 리스트 변수'''
feature_importances = []
''' 특성중요도는 모델 훈련에 따른 중요도, 따라서 훈련데이터 사용 '''
''' 추출된 특성중요도의 리스트 값의 순서는 특성의 실제 순서와 동일함 '''
if modelName == "HistGradientBoostingClassifier" :
feature_importances = permutation_importance(model, X_train, y_train, n_repeats=10, random_state=42)
feature_importances = feature_importances.importances_mean
else :
feature_importances = model.feature_importances_
''' 추출된 특성중요도 값과 실제 특성명과 매핑하여 딕셔너리에 담기 '''
feature_importances_dict = {k : v for k, v in zip(columnNames, feature_importances)}
print(f"특성중요도 : ", feature_importances_dict)
print()

728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][ML] Machine Learning - 모델 저장하기 및 불러오기 (0) | 2023.12.29 |
|---|---|
| [인공지능][ML] Machine Learning - 군집모델 / 군집분석 / 주성분분석(PCA) (0) | 2023.12.28 |
| [인공지능][ML] Machine Learning - 랜덤포레스트 (2) (1) | 2023.12.27 |
| [인공지능][ML] Machine Learning - 분류모델 / 앙상블모델 / 배깅 / 부스팅 / 랜덤포레스트 (0) | 2023.12.26 |
| [인공지능][ML] Machine Learning - 선형회귀모델 / 다항회귀모델 / 다중회귀모델 (0) | 2023.12.21 |