728x90
반응형
군집모델
군집(Clustering)분석
- 비지도 학습
- 군집분석은 분류를 위한 분석
- 패턴이 유사한 데이터들끼리 묶는 작업
- 묶음 단위를 군집(Cluster)이라고 칭한다.
- 대표 모델 : KMeans(K평균)
KMeans(K평균) 군집 모델
- 모델 스스로 패턴이 유사한 특성(컬럼)들을 묶으면서 중심 평균을 구하는 방식
- 점진적으로 패턴이 유사한 특성들끼리 묶어나가는 방식
- 특성들이 묶이면서 중심에 대한 평균이 이동됨
- 가장 대표적인 군집모델
🖍️ 특징
- 군집할 갯수를 미리 정의해야 함
- 군집할 갯수는 종속변수의 범주의 갯수와 동일함(이미 종속변수를 알고 있는 경우도 있고, 아닌 경우도 있음)
- 군집의 갯수를 이미 알고 있는 경우에는 직접 갯수 정의, 모르는 경우에는 하이퍼파라미터 튜닝을 통해 적절한 갯수 선정
🖍️ 작동방식
- 데이터들을 이용해서 무작위로 K개의 클러스터 중심을 정함
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아서 해당 클러스터의 샘플로 지정
- 특정 클러스터에 속한 "샘플들의 평균값"으로 클러스터 중심을 변경
- 클러스터 중심에 변화가 없을 때까지 2번 ~ 3번을 반복 수행하게 되는 모델임
사용할 라이브러리
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix
''' KMeans 군집 모델 '''
from sklearn.cluster import KMeans
사용할 데이터 셋 - 와인데이터
'''
- 데이터 불러오기 : 변수명 data
- 독립변수와 종속변수로 나누기 : 변수명은 X, y
'''
data = pd.read_csv("./data/08_wine.csv")
X = data.iloc[:,:-1]
y = data["class"]
X.shape, y.shape
데이터 스케일링 - 정규화
'''
- 정규화 클래스 변수 : scaler
- 독립변수 정규화 변수명 : X_scaled
'''
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
X_scaled.shape
훈련 : 테스트 분리하기 (8:2)
'''
- 변수명 : X_train, X_test, y_train, y_test
'''
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, random_state=42, test_size=0.2)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
하이퍼파라미터 튜닝을 위한 매개변수 정의하기
'''
- n_clusters : 군집갯수
- n_init : 초기 중심점 설정 횟수
- max_iter : 최대 반복 횟수
- tol : 중심정의 이동이 설정 값보다 작으면 종료
'''
param_grid = {
"n_init" : [10, 30, 50],
"max_iter" : [10, 30, 50],
"tol" : [0.0001, 0.001, 0.01, 0.1]
# "n_clusters" : [2, 3, 4, 5]
}
튜닝 및 훈련모델 생성
- 튜닝에 사용할 훈련모델 생성
kmeans = KMeans(n_clusters=2, random_state=42)- GridSearchCV 생성하여 베스트 모델 찾기
grid_search = GridSearchCV(kmeans, param_grid, cv=5, scoring="accuracy")
grid_search
- 튜닝 시작하기
grid_search.fit(X_train, y_train)
- 최적의 매개변수를 가지는 모델 추출하기
best_model = grid_search.best_estimaitor_
best_model
훈련 및 검증(테스트) 모델 평가하기
'''
- 훈련 및 테스트 예측
- 훈련 및 테스트 정확도 확인
- 오차행렬(혼동행렬) 추출
'''
train_pred = best_model.predict(X_train)
test_pred = best_model.predict(X_test)
train_acc = accuracy_score(y_train, train_pred)
test_acc = accuracy_score(y_test, test_pred)
''' 오차행렬도(혼동행렬) '''
cm = confusion_matrix(y_test, test_pred)
print(f"훈련 정확도 : {train_acc} / 테스트 정확도 : {test_acc}")
print(f"오차행렬(혼동행렬) : {cm}")
결과
와인 데이터는 군집분석으로 적절하지 않다
지도학습 기반의 분류모델이 적절하다.
지도학습을 하려면 정답을 알아야 한다.
정답을 알지 못한다면 라벨링을 해야 한다.(종속변수를 만들어야 한다)
시각화 하기
- 시각화 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"] = False- 시각화에 사용할 데이터 생성하기
data = {
"alcohol" : X_train[:, 0],
"sugar" : X_train[:, 1],
"pH" : X_train[:, 2],
"class" : y_train,
"cluster" : train_pred
}
train_data = pd.DataFrame(data=data)
train_data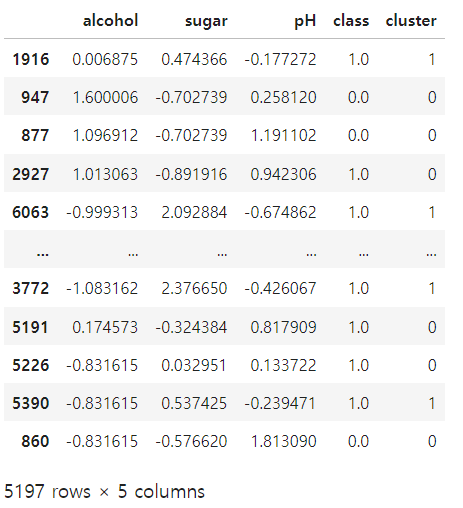
- 시각화하기
sns.pairplot(train_data, hue="cluster")
plt.show()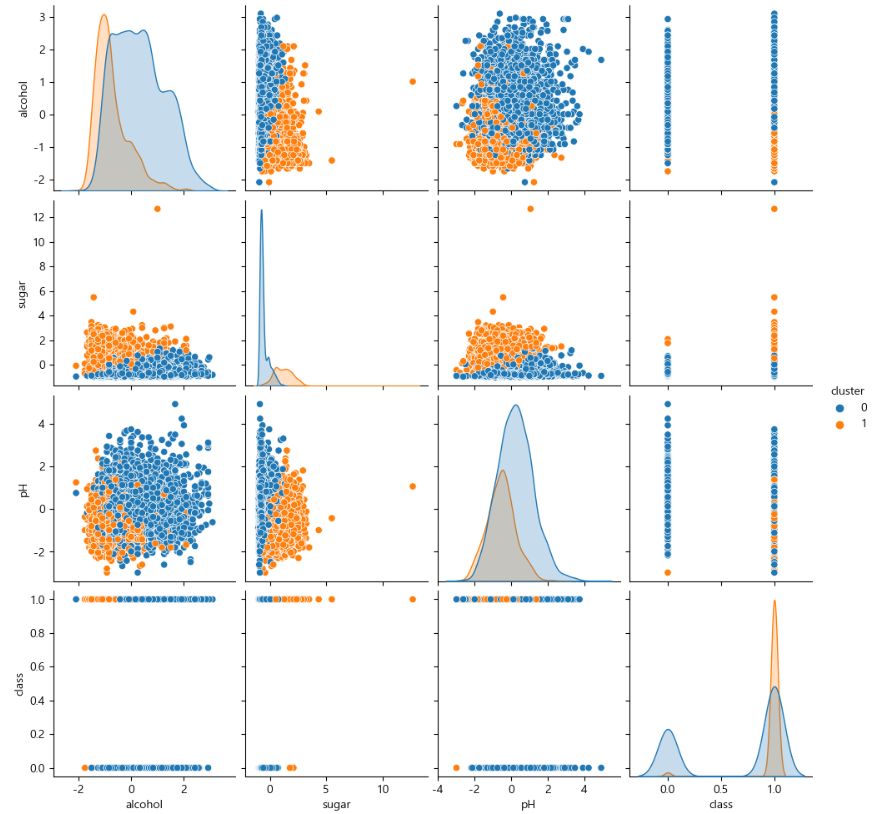
class가 0과 1 밖에 없기 때문에 위와 같은 일직선 모양의 그래프가 나타남
섞여있으면 군집이 안된 것 (예를 들어, alcohol과 pH)
파란색(0)이 1에 있으면 틀린 것 > 분류를 잘못함
주황색(1)이 0에 있으면 틀린 것 > 분류를 잘못함
Iris(붓꽃) 데이터셋을 이용한 군집(Clustering)분석

- 사용 라이브러리
from sklearn.cluster import KMeans
'''
군집분석 평가 방법 : 실루엣 score로 평가함
- 값의 범위 : -1 ~ 1 사이의 값
- -1에 가까울 경우 : 군집 분류가 잘 안된 경우
- 0에 가까울 경우 : 이도 저도 아닌 상태()
- 1에 가까울 경우 : 군집이 잘 된 경우
'''
from sklearn.metrics import silhouette_score
''' Iris(붓꽃) 데이터셋 라이브러리 '''
from sklearn.datasets import load_iris
import seaborn as sns- Iris 데이터 읽어들이기
iris = load_iris()
iris- 특성 설명

- sepal length : 꽃받침 길이
- sepal width : 꽃받침 너비
- petal length : 꽃잎 길이
- petal width : 꽃잎 너비
- 종속변수 특성 설명
- 0, 1, 2의 값 (붓꽃의 품종)
- 0 : 세토사(setosa)
- 1 : 버시컬러(verstcolor)
- 2 : 버지니카(virginica) - 분석 주제
- 4가지 독립변수 특성을 이용하여 붓꽃의 품종 종류별로 군집(클러스터) 분류하기
독립변수와 종속변수 데이터 추출하기
'''
독립변수명 : X
종속변수명 : y
'''
X = iris.data
y = iris.target
X.shape, y.shape
군집 모델 생성 / 훈련 및 예측
'''
- 군집분류에서는 별도로 훈련과 검증데이터로 분류하기 않고, 전체 데이터를 사용하여 군집합니다.
'''
'''
* 군집모델 생성하기
- 군집 갯수 지정
- n_init : 초기 중심점 설정 횟수는 10으로 설정
- 랜덤 규칙 : 42번
'''
kmeans_model = KMeans(n_clusters=3, n_init=10, random_state=42)
kmeans_model
'''
- 모델 훈련 및 군집하기(예측)
- 군집분석에서는 훈련과 동시에 예측이 수행 됨
'''
kmeans_labels = kmeans_model.fit_predict(X)
print(kmeans_labels)
print(y)
군집결과 시각화하기
- 주성분분석(PCA)을 통해 시각화하기
- 주성분분석(PCA)
→ 훈련에 사용된 특성들 중에 특징을 가장 잘 나타낼 수 있는 특성을 추출하는 방식
→ 특성을 추출하여 특성을 축소시키는 방식으로 "차원축소"라고 칭한다.
→ 주요 성분의 특성만을 사용하기 때문에 빠른 성능을 나타냄 - 주성분분석(차원축소) 라이브러리
from sklearn.decomposition import PCA
- 주성분분석(PCA) 클래스 생성하기
'''
- n_components : 주성분 몇개로 차원을 축소할지 정의
'''
pca = PCA(n_components=2)
pca
- 주성분 찾기
pca.fit(X)
X_pca = pca.transform(X)
X_pca.shape
- 시각화 하기
plt.title("K평균 군집화 결과")
plt.scatter(X_pca[:, 0], X_pca[:,1], c=kmeans_labels)
plt.show()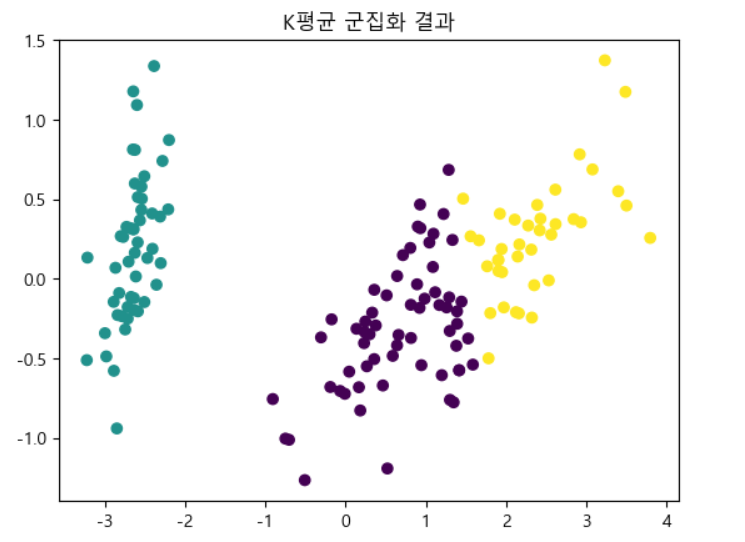
1개(초록)는 분류가 잘 되었고, 나머지 2개(보라, 노랑)는 섞여있다.
3개의 범주 중 1개는 정확히 분류 되었고 나머지는 섞여있다. 이 둘은 50% 의 확률로 분류되지 않을 수도 있다. 그렇기 때문에 이 분류모델을 사용하기엔 부족한 부분이 있다고 판단한다
그러나 보라 노랑이 섞여는 있지만 어느정도 분류된 것 처럼 보이기 때문에 사용할 수 도 있다.
- 군집분석 평가하기 : 실루엣 평가
s_score = silhouette_score(X, kmeans_labels)
s_score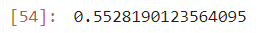
728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][DL] Deep Learning - Tensorflow / 인공신경망 (0) | 2023.12.29 |
|---|---|
| [인공지능][ML] Machine Learning - 모델 저장하기 및 불러오기 (0) | 2023.12.29 |
| [인공지능][ML] Machine Learning - 분류모델 선정하기 / GridSearchCV / 특성중요도 (0) | 2023.12.27 |
| [인공지능][ML] Machine Learning - 랜덤포레스트 (2) (1) | 2023.12.27 |
| [인공지능][ML] Machine Learning - 분류모델 / 앙상블모델 / 배깅 / 부스팅 / 랜덤포레스트 (0) | 2023.12.26 |