📝 문제
1. 문제 설명
코딩테스트를 준비하는 머쓱이는 프로그래머스에서 문제를 풀고 나중에 다시 코드를 보면서 공부하려고 작성한 코드를 컴퓨터 바탕화면에 아무 위치에나 저장해 둡니다. 저장한 코드가 많아지면서 머쓱이는 본인의 컴퓨터 바탕화면이 너무 지저분하다고 생각했습니다. 프로그래머스에서 작성했던 코드는 그 문제에 가서 다시 볼 수 있기 때문에 저장해 둔 파일들을 전부 삭제하기로 했습니다.
컴퓨터 바탕화면은 각 칸이 정사각형인 격자판입니다. 이때 컴퓨터 바탕화면의 상태를 나타낸 문자열 배열 wallpaper가 주어집니다. 파일들은 바탕화면의 격자칸에 위치하고 바탕화면의 격자점들은 바탕화면의 가장 왼쪽 위를 (0, 0)으로 시작해 (세로 좌표, 가로 좌표)로 표현합니다. 빈칸은 ".", 파일이 있는 칸은 "#"의 값을 가집니다. 드래그를 하면 파일들을 선택할 수 있고, 선택된 파일들을 삭제할 수 있습니다. 머쓱이는 최소한의 이동거리를 갖는 한 번의 드래그로 모든 파일을 선택해서 한 번에 지우려고 하며 드래그로 파일들을 선택하는 방법은 다음과 같습니다.
- 드래그는 바탕화면의 격자점 S(lux, luy)를 마우스 왼쪽 버튼으로 클릭한 상태로 격자점 E(rdx, rdy)로 이동한 뒤 마우스 왼쪽 버튼을 떼는 행동입니다. 이때, "점 S에서 점 E로 드래그한다"고 표현하고 점 S와 점 E를 각각 드래그의 시작점, 끝점이라고 표현합니다.
- 점 S(lux, luy)에서 점 E(rdx, rdy)로 드래그를 할 때, "드래그 한 거리"는 |rdx - lux| + |rdy - luy|로 정의합니다.
- 점 S에서 점 E로 드래그를 하면 바탕화면에서 두 격자점을 각각 왼쪽 위, 오른쪽 아래로 하는 직사각형 내부에 있는 모든 파일이 선택됩니다.
예를 들어 wallpaper = [".#...", "..#..", "...#."]인 바탕화면을 그림으로 나타내면 다음과 같습니다

이러한 바탕화면에서 다음 그림과 같이 S(0, 1)에서 E(3, 4)로 드래그하면 세 개의 파일이 모두 선택되므로 드래그 한 거리 (3 - 0) + (4 - 1) = 6을 최솟값으로 모든 파일을 선택 가능합니다.
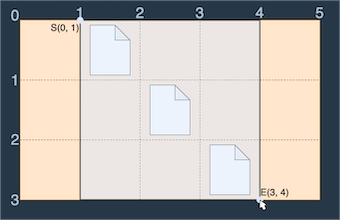
(0, 0)에서 (3, 5)로 드래그해도 모든 파일을 선택할 수 있지만 이때 드래그 한 거리는 (3 - 0) + (5 - 0) = 8이고 이전의 방법보다 거리가 늘어납니다.
머쓱이의 컴퓨터 바탕화면의 상태를 나타내는 문자열 배열 wallpaper가 매개변수로 주어질 때 바탕화면의 파일들을 한 번에 삭제하기 위해 최소한의 이동거리를 갖는 드래그의 시작점과 끝점을 담은 정수 배열을 return하는 solution 함수를 작성해 주세요. 드래그의 시작점이 (lux, luy), 끝점이 (rdx, rdy)라면 정수 배열 [lux, luy, rdx, rdy]를 return하면 됩니다.
2. 제한사항
- 1 ≤ wallpaper의 길이 ≤ 50
- 1 ≤ wallpaper[i]의 길이 ≤ 50
wallpaper의 모든 원소의 길이는 동일합니다. - wallpaper[i][j]는 바탕화면에서 i + 1행 j + 1열에 해당하는 칸의 상태를 나타냅니다.
- wallpaper[i][j]는 "#" 또는 "."의 값만 가집니다.
- 바탕화면에는 적어도 하나의 파일이 있습니다.
- 드래그 시작점 (lux, luy)와 끝점 (rdx, rdy)는 lux < rdx, luy < rdy를 만족해야 합니다.
3. 입출력 예
| wallpaper | result |
| [".#...", "..#..", "...#."] | [0, 1, 3, 4] |
| ["..........", ".....#....", "......##..", "...##.....", "....#....."] | [1, 3, 5, 8] |
| [".##...##.", "#..#.#..#", "#...#...#", ".#.....#.", "..#...#..", "...#.#...", "....#...."] | [0, 0, 7, 9] |
| ["..", "#."] | [1, 0, 2, 1] |
4. 입출력 예
- 입출력 예 #1
문제 설명의 예시와 같은 예제입니다. (0, 1)에서 (3, 4)로 드래그 하면 모든 파일을 선택할 수 있고 드래그 한 거리는 6이었고, 6보다 적은 거리로 모든 파일을 선택하는 방법은 없습니다. 따라서 [0, 1, 3, 4]를 return합니다. - 입출력 예 #2
예제 2번의 바탕화면은 다음과 같습니다.(1, 3)에서 (5, 8)로 드래그하면 모든 파일을 선택할 수 있고 이보다 적은 이동거리로 모든 파일을 선택하는 방법은 없습니다. 따라서 가장 적은 이동의 드래그로 모든 파일을 선택하는 방법인 [1, 3, 5, 8]을 return합니다.

- 입출력 예 #3
예제 3번의 바탕화면은 다음과 같습니다.모든 파일을 선택하기 위해선 바탕화면의 가장 왼쪽 위 (0, 0)에서 가장 오른쪽 아래 (7, 9)로 드래그 해야만 합니다. 따라서 [0, 0, 7, 9]를 return합니다.

- 입출력 예 #4
예제 4번의 바탕화면은 다음과 같이 2행 1열에만 아이콘이 있습니다.이를 드래그로 선택하기 위해서는 그 칸의 왼쪽 위 (1, 0)에서 오른쪽 아래 (2, 1)로 드래그 하면 됩니다. (1, 0)에서 (2, 2)로 드래그 해도 아이콘을 선택할 수 있지만 이전보다 이동거리가 늘어납니다. 따라서 [1, 0, 2, 1]을 return합니다.

✏️작성한 코드
코드 풀이를 해보자.
일단 X, Y를 행과 열로 생각한다.
- int[] X = new int[wallpaper.length];
wallpaper 배열에 들어가 있는 값의 길이 만큼 X, Y도 출력되서 나오므로 X, Y를 wallpaper 만큼의 길이를 가진 리스트로 설정했다. - int xMin = Integer.MAX_VALUE;
X, Y에 들어간 값 중 행의 최솟값과 행의 최댓값, 열의 최솟값과 열의 최댓값을 찾아야 하므로 각각을 변수로 설정한다. Integer.MAX_VALUE는 JAVA에서의 정수 최댓값을 의미하기 때문에 최솟값을 구하려고 할 때 MAX_VALUE와 비교해야 한다. - for 문
중첩된 루프를 사용하여 wallpaper 배열을 순회하면서 '#' 문자를 찾고, 해당 위치의 행과 열을 X와 Y 배열에 저장하고 최솟값과 최댓값을 업데이트합니다. - Math.min(A, X[i])
Math.min(a, b)은 두 인자 값 중 작은 값을 리턴한다. 즉, A가 Integer.MAX_VALUE 이므로 X[i]이 그보다 더 클 수 없다. 그러므로 처음 들어오는 X[i]의 값이 A로 리턴되면서 새로 들어오는 X[i]과 비교하여 최소값을 반환하게 된다. - xMax = Math.max(C, X[i]+1);
Max 값에 1을 더해준 이유는 파일이 교차되는 점에 위치해 있는게 아닌 한 개의 구역을 차지하고 있기 때문에 드래그 했을 때 마지막 위치가 구역의 시작이 아닌 마지막이므로 1을 더 해줘야 해야 한다.
class Solution {
public int[] solution(String[] wallpaper) {
int[] X = new int[wallpaper.length];
int[] Y = new int[wallpaper.length];
int xMin = Integer.MAX_VALUE;
int yMin = Integer.MAX_VALUE;
int xMax = Integer.MIN_VALUE;
int yMax = Integer.MIN_VALUE;
for (int i = 0; i < wallpaper.length; i++) {
for (int j = 0; j < wallpaper[i].length(); j++) {
if (wallpaper[i].charAt(j) == '#') {
X[i] = i;
Y[i] = j;
xMin = Math.min(A, X[i]);
yMin = Math.min(B, Y[i]);
xMax = Math.max(C, X[i]+1);
yMax = Math.max(D, Y[i]+1);
}
}
}
int[] answer = {xMin, yMin, xMax, yMax};
return answer;
}
}
'Digital Boot > Programmers' 카테고리의 다른 글
| [Programmers][Java] 프로그래머스 코딩테스트 Lv. 1 - 과일 장수 (3) | 2023.11.30 |
|---|---|
| [Programmers][SQL] 프로그래머스 코딩테스트 Lv. 1 - 평균 일일 대여 요금 구하기 / 조건에 맞는 도서 리스트 출력하기 (0) | 2023.11.28 |
| [Programmers][Java] 프로그래머스 코딩테스트 Lv. 1 - 달리기 경주 (2) | 2023.11.27 |
| [Programmers][SQL] 프로그래머스 코딩테스트 Lv. 3 - 대여 횟수가 많은 자동차들의 월별 대여 횟수 구하기 (2) | 2023.11.27 |
| [Programmers][Java] 프로그래머스 코딩테스트 Lv. 1 - 추억 점수 (2) | 2023.11.24 |