728x90
반응형
🎄 Machine Learning 개요
🎄 Machine Learning이란?
- 알고리즘(algorithms) : 어떠한 문제를 해결하기 위한 일련의 절차나 방법
- 유튜브는 개인이 유튜브 영상을 보는 패턴에 대해 학습하는 프로그램(머신러닝)을 만든 다음 그 패턴(알고리즘)에 맞게 다음 영상을 계속 추천해 준다.
- 머신러닝을 통해 데이터를 훈련시켜서 패턴을 파악한다. 그 후 파악되는 패턴을 통해 미래를 예측하는 방법을 사용한다.
- 머신러닝이 필수인가? 데이터를 분석할 때 머신러닝을 사용하는 회사가 존재한다.
- 설문조사(리서치) 회사 - 탐색적 데이터 분석을 통해 데이터의 인사이트 도출, 파이썬을 통해 예측
- 데이터 분석 및 예측 회사 - 데이터의 흐름을 가지고 미래 예측. 예를 들어, 기상청은 지형지물에 대한 영상을 보고 어떠한 형태인지 파악 후 미래 날씨 예측
- 영상에서 통해 수집되는 행위분석(이미지분석) 회사 - 딥러닝, CCTV를 통해 물건을 훔치는 모션이 정보로 들어오면 스스로 신고하게하는 행위
- 인공지능 : 스스로 학습하고 스스로 판단하게 하는 능력을 가지는 것으로 인공지능으로 가려면 데이터 분석이 필요하다.
- ICBMS : 4차 산업을 이끄는 핵심기술 (IoT / Cloud / Big Data / Mobile / Security)
- 사이킷런(scikit-learn) : 머신러닝 프레임워크, 실제 머신러닝 모델을 생성하고 데이터에 적용할 수 있도록 도와주는 도구
- 머신러닝(machine learning) : 기계가 패턴을 학습하여 자동화하는 알고리즘, 데이터를 컴퓨터에 학습 시켜 그 패턴과 규칙을 컴퓨터가 스스로 학습하도록 만드는 기술
- 이전에는 사람이 지식을 직접 데이터베이스화한 후 컴퓨터 가 처리하도록 프로그램으로 만듦
- 머신러닝은 데이터를 분류하는 수학적 모델을 프로그래밍 하여, 데이터만 입력하면 이미 만들어진 수학 모델이 규칙으로 적용되어 여러 문제를 풀 수 있음
- 딥러닝(deep learning) : 머신러닝 기법 중 신경망(neural network)을 기반으로 사물이나 데이터를 군집화하거나 분류하는데 사용하는 기술
- 인공지능 ⊃ 머신러닝 ⊃ 딥러닝

🎄머신러닝의 학습 프로세스와 종류

- 모델과 알고리즘
- ‘모델’은 ‘수식’이나 ‘통계 분포’, ‘알고리즘’은 모델을 산출하기 위해 규정화된 과정(훈련과정 = 학습)
- 보통 하나의 모델은 다양한 알고리즘으로 표현할 수 있다
- 때때로 ‘알고리즘’은 하나의 ‘수식’으로 표현 가능하다
- 그림 1 : 모델을 훈련시킨다.
- 원천데이터 전처리 가공 후 머신러닝이라는 알고리즘에 넣어줌(라이브러리 활용, 라이브러리에는 계산 공식이 들어 있음 ) > 넣어준 데이터를 가지고 훈련시킴 > 훈련을 통해 가장 정확한 것 같은 패턴을 파악
- 선형예측, 회귀예측, 분류예측
- 머신러닝의 종류(데이터 종류)
- 지도학습(supervised learning) : 문제와 답을 함께 학습
- 비지도학습(unsupervised learning) : 조력자의 도움 없 이 컴퓨터 스스로 학습. 컴퓨터가 훈련 데이터를 이용 하여 데이터들 간의 규칙성을 찾아냄
- 실제 답(ground truth) 의 존재 여부에 따라 구분

x = 넣어준 데이터(문제, 독립변수)
y = 문제에 대한 답으로 구성된 데이터(정답, 종속변수)
x와 y 사이의 패턴 파악
새로운 x값을 넣어주면, 스스로 y값을 도출해냄
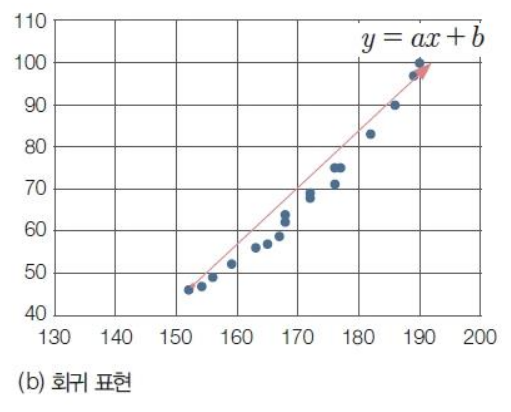
- 회귀(regression)
- 독립변수 x와 종속변수 y의 관계를 함수식으로 설명
- 추세선을 표현하는 수학적 모델을 만드는 기법
- 사용하는 데이터 : 연속형 데이터(나이, 키, 몸무게)
우상향, 선형
x(키), y(몸무게) 값을 넣어줌.
a, b를 대표하는 값을 찾아내기 위해 컴퓨터를 훈련시킴.
빨간색 = 추세선 알아내고 x 값을 넣었을 때 y값을 도출해냄
- 분류(classification)
- 데이터를 어떤 기준(패턴)에 따라 나눔
- 이진분류(binary classification) : 2개의 값 중 1개를 분류
- 다중분류(multi-class classification) : 3개 이상 분류 실행
- 사용하는 데이터 : 범주형 데이터(성별, 형태를 구분하는 것)

x(키), y(몸무게)의 패턴값을 확인해서 분포를 확인.
스스로 학습하여 확률적으로 패턴확인.
그리고 구분선(빨간색)을 그려 분류하고 성별을 분류하여 알아냄
- 군집(clustering)
- 기존에 모여 있던 데이터에 대해 따로 분류 기준을 주지 않고 모델이 스스로 분류 기준을 찾아 집단을 모으는 기법
- 비슷한 수준의 농구팀 3개 만들기
- 사용하는 데이터 : 연속형 / 범주형 데이터
- 비지도 학습은 분류를 하기 위해 사용하기 때문에 대부분 범주형 데이터를 주로 사용

집단을 나누는 것.
집단의 갯수는 따로 지정할 수 있음.
갯수에 대한 범주를 스스로 만들어 군집을 만들어 냄
중복되는 부분(이상데이터)은 해소시켜줘야 함
> 데이터를 제거? 추가? 추가한다면 어느 군집으로 넣을 것인가?
🐟 Machine Learning 실습
🐟 생선구분하기_K최근접이웃모델
- 데이터 처리
- 빙어와 도미 데이터
- 생선의 종류를 분류(구분)하기 위한 모델 생성을 위해 독립변수와 종속변수로 데이터를 가공해야함
- 독립변수(x) : 길이, 무게
- 종속변수(y) : 생선종류(빙어 또는 도미)
- 훈련모델 처리 절차
- 데이터 전처리
- 데이터 정규화
- 훈련 : 검증 : 테스트 데이터로 분류 (또는 훈련 : 테스트 데이터로 분류)
>> 6 : 2 : 2 또는 7 : 2 : 1, 데이터가 적은 경우에는 8 : 2 또는 7 : 3 정도로 분류 - 모델 생성
- 모델 훈련(fit) (훈련 데이터와 검증 데이터 사용, 또는 테스트 데이터)
- 모델 평가 (모델 선정, 검증데이터)
- 하이퍼파라미터 튜닝
- 5번 ~ 6번 진행
- 최종 테스트(예측, predict) (테스트 데이터 또는 새로운 데이터로 사용)
I want to be good at machine learning!
728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][ML] Machine Learning - 분류모델 / 앙상블모델 / 배깅 / 부스팅 / 랜덤포레스트 (0) | 2023.12.26 |
|---|---|
| [인공지능][ML] Machine Learning - 선형회귀모델 / 다항회귀모델 / 다중회귀모델 (0) | 2023.12.21 |
| [인공지능][ML] Machine Learning - KNN 회귀모델 / 평균절대오차(MAE) (0) | 2023.12.21 |
| [인공지능][ML] Machine Learning - 훈련 및 테스트 데이터 분류하기 / 정규화 (3) | 2023.12.20 |
| [인공지능][ML] Machine Learning - K최근접이웃모델 / KNN (5) | 2023.12.20 |