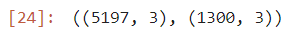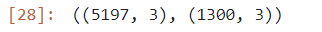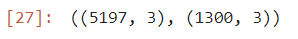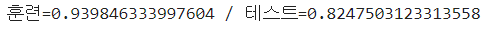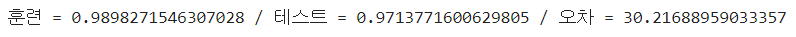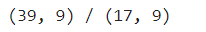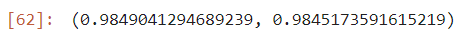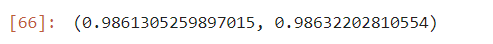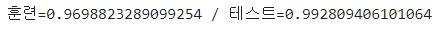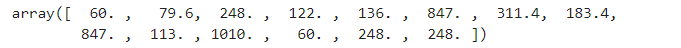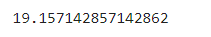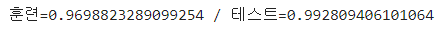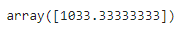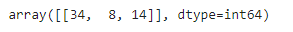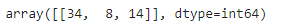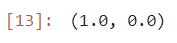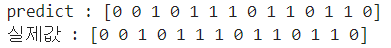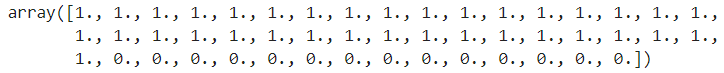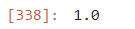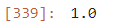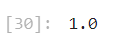728x90
반응형
https://mzero.tistory.com/115 에 이어서
[인공지능][ML] Machine Learning - 분류모델 / 앙상블모델 / 배깅 / 부스팅 / 랜덤포레스트
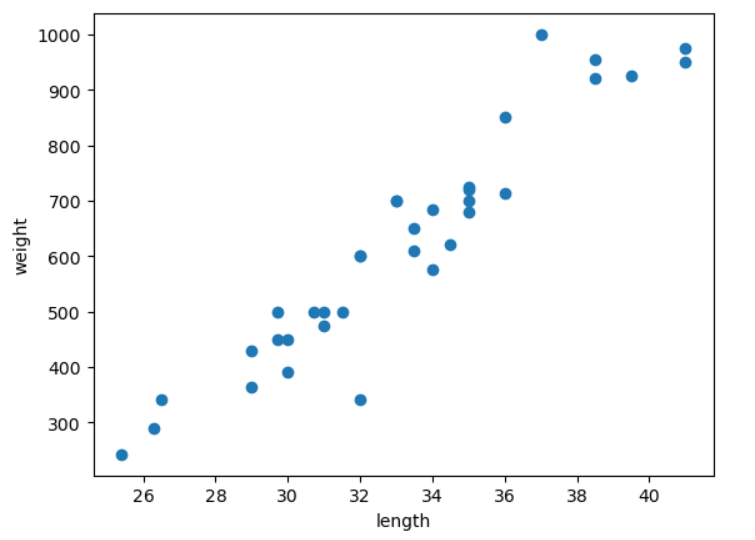
분류 앙상블 모델 🍇 앙상블 모델 tree구조(결정트리)를 기반으로 만들어진 모델 여러개의 트리 모델을 이용해서 훈련하는 모델을 앙상블 모델이라고 칭한다. 🍇 앙상블 모델 분류 회귀와 분류
mzero.tistory.com
Randomforest(랜덤포레스트)
🍇 훈련하기
1. StandardScaler 사용
''' 훈련모델 생성하기 '''
from sklearn.ensemble import RandomForestClassifier
''' 모델(클래스) 생성하기
- cpu의 코어는 모두 사용, 랜덤값은 42번을 사용하여 생성하기
- 모델 변수의 이름은 rf 사용
'''
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
''' 모델 훈련 시키기 '''
rf.fit(train_std_scaler, train_target)
''' 훈련 및 검증(테스트) 정확도(score) 확인하기 '''
train_score = rf.score(train_std_scaler, train_target)
test_score = rf.score(test_std_scaler, test_target)
print(f"훈련 = {train_score} / 검증 = {test_score}")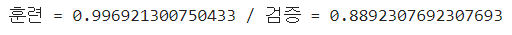
2. RobustScaler 사용
''' 모델(클래스) 생성하기
- cpu의 코어는 모두 사용, 랜덤값은 42번을 사용하여 생성하기
- 모델 변수의 이름은 rf 사용
'''
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
''' 모델 훈련 시키기 '''
rf.fit(train_rbs_scaler, train_target)
''' 훈련 및 검증(테스트) 정확도(score) 확인하기 '''
train_score = rf.score(train_rbs_scaler, train_target)
test_score = rf.score(test_rbs_scaler, test_target)
print(f"훈련 = {train_score} / 검증 = {test_score}")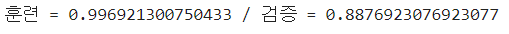
3. MinMaxScaler 사용
''' 모델(클래스) 생성하기
- cpu의 코어는 모두 사용, 랜덤값은 42번을 사용하여 생성하기
- 모델 변수의 이름은 rf 사용
'''
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
''' 모델 훈련 시키기 '''
rf.fit(train_mm_scaler, train_target)
''' 훈련 및 검증(테스트) 정확도(score) 확인하기 '''
train_score = rf.score(train_mm_scaler, train_target)
test_score = rf.score(test_mm_scaler, test_target)
print(f"훈련 = {train_score} / 검증 = {test_score}")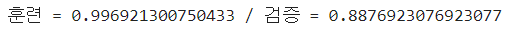
해석
- 가장 일반화된 모델을 나타내는 스케일링 방법으로는 StandardScaler 정규화 방법을 사용했을 때 이다.
- 3개 모두 0.1 이상의 과대적합 양상을 보인다.
- 따라서, 하이퍼파라미터 튜닝 및 다른 분류모델에 의한 훈련이 필요할 것으로 보인다.
🍇 예측하기
''' 모델(클래스) 생성하기 '''
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
''' 모델 훈련 시키기 '''
rf.fit(train_std_scaler, train_target)
''' 예측하기 '''
y_pred = rf.predict(test_std_scaler)
y_pred
🍇 성능평가하기
- 분류 모델 평가 방법
- 정확도, 정밀도, 재현율, F1-score 값을 이용해서 평가함
- 예측에 오류가 있는지 확인 : 오차행렬도(혼동행렬도)를 통해 확인 - 평가 기준
- 정확도를 이용하여 과적합 여부 확인(이미 위에서 실행함)
- 재현율이 높고, F1-score 값이 높은 값을 가지는 모델을 선정하게 됨
- 정확도, 정밀도, 재현율, F1-score의 모든 값은 0~1 사이의 값을 가지며, 값이 높을 수록 좋다.
- 재현율을 가장 중요시 여긴다. - 성능 평가에 시각화 자료 사용
''' 시각화 라이브러리 정의하기 '''
import matplotlib.pyplot as plt
import seaborn as sns
''' 한글처리 '''
plt.rc("font", family = "Malgun Gothic")
''' 마이너스 기호 처리 '''
plt.rcParams["axes.unicode_minus"] = True
import numpy as np
''' 오차행렬 계산 라이브러리 '''
from sklearn.metrics import confusion_matrix
''' 오차행렬도 시각화 라이브러리 '''
from sklearn.metrics import ConfusionMatrixDisplay
- 오차행렬도 그리기
''' 오차행렬의 기준 특성은 종속변수 기준 '''
''' 훈련에서 사용한 종속변수의 범주 확인하기 '''
rf.classes_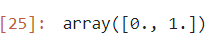
''' 오차행렬 평가 매트릭스 추출하기 '''
cm = confusion_matrix(test_target, y_pred, labels=rf.classes_)
''' 오차행렬도 시각화 하기 '''
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=rf.classes_)
disp.plot()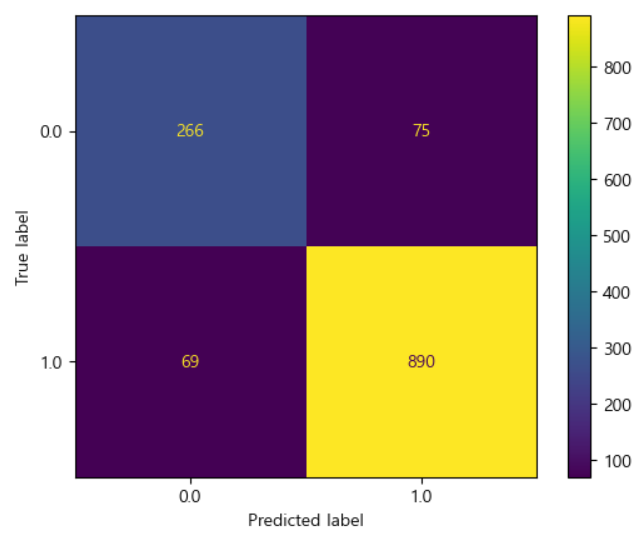
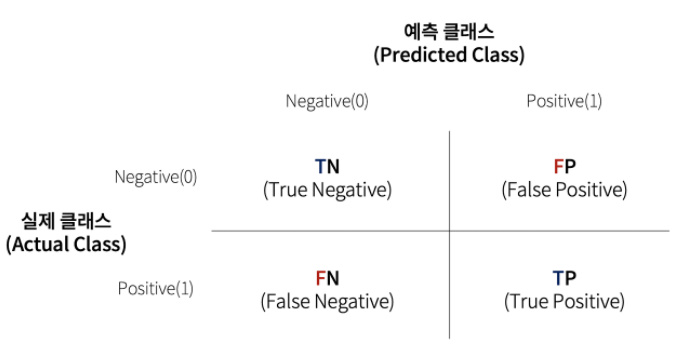
TN (0, 0) 실제 0인 값을 0으로 예측 > 참
FP (0, 1) 실제 0인 값을 1로 예측 > 긍정적 오류
FN (1, 0) 실제 1인 값을 0으로 예측 > 부정적 오류 : 해당 값이 많을 수록 사용할 수 없는 모델이 된다.
TP (1, 1) 실제 1인 값을 1로 예측 > 참
<오차행렬(혼동행렬)>
- 어떠한 유형의 오류가 발생하고 있는지를 나타내는 값
- 이를 시각화한 것을 오차행렬도 또는 혼동행렬도라고 칭함
- 정확도(score)의 값과 오차행렬도의 시각화 결과로 최종 모델을 선정한다.
<해석 방법>
- 긍정(Positive)적 오류인지, 부정(Negative)적 오류인지로 해석함
* FP(False Positive)
: 예측결과가 맞지는 않음(False)
: 긍정적(Positive)로 해석함 : 위험하지 않은 오류
* FN(False Negative)
: 예측결과가 맞지는 않음(False)
: 부정적(Negative) 오류로 해석함
: 위험한 오류로 해석
: FN의 값이 크다면, 정확도(score)의 값이 높더라도 예측 모델로 사용하는데 고려해야함
* TP(True Positive)
: 예측결과가 맞는 경우(True)
: 1을 1로 잘 예측한 경우
* TN(True Negative)
: 예측결과가 맞는 경우(True)
: 0을 0으로 잘 예측한 경우
<평가에 사용되는 값 : 정확도, 정밀도, 재현율, F1_score>
* 정확도
- 예측결과가 실제값과 얼마나 정확한가를 나타내는 값
- Accuracy = (TP + TN) / (TP + TN + FP + FN)
* 정밀도(Precision)
- 모델이 1로 예측한 데이터 중에 실제로 1로 잘 예측한 겂
- Precision = TP / (TP + FP)
* 재현율(Recall)
- 실제로 1인 데이터를 1로 잘 예측한 값
- Recall = TP / (TP + FN)
- 위험한 오류가 포함되어 있음
* F1-score
- 정밀도와 재현율을 조합하여 하나의 통계치로 반환한 값
- 정밀도와 재현율의 평균이라고 생각해소 됨
- F1 Score = 2 * {(정밀도 * 재현율) / (정밀도 + 재현율)}
<최종 모델 선정 방법>
- 과소 및 과대 적합이 일어나지 않아야 함
- 재현율과 F1-score가 모두 높으면 우수한 모델로 평가할 수 있음
- 재현율이 현저히 낮은 경우에는 모델 선정에서 고려, 또는 제외
- 분류모델 평가 라이브러리
''' 정확도 : 훈련 및 검증 정확도에서 사용한 score()함수와 동일함 '''
from sklearn.metrics import accuracy_score
''' 정밀도 '''
from sklearn.metrics import precision_score
''' 재현율 '''
from sklearn.metrics import recall_score
''' F1-score '''
from sklearn.metrics import f1_score
1. 정확도
acc = accuracy_score(test_target, y_pred)
acc
2. 정밀도
pre = precision_score(test_target, y_pred)
pre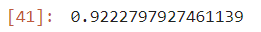
3. 재현율
rec = recall_score(test_target, y_pred)
rec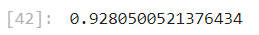
4. F1-score
rec = recall_score(test_target, y_pred)
rec
해석
- 정확도는 0.89로 높은편
- 정밀도, 재현율, F1_score의 값이 0.92 이상으로 매우 높은 값을 나타내고 있음
- 따라서, 랜덤포레스트 모델을 이용해서 해당 데이터에 대한 예측을 하는데 사용가능
- 즉, 예측 모델로 사용가능
728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][ML] Machine Learning - 군집모델 / 군집분석 / 주성분분석(PCA) (0) | 2023.12.28 |
|---|---|
| [인공지능][ML] Machine Learning - 분류모델 선정하기 / GridSearchCV / 특성중요도 (0) | 2023.12.27 |
| [인공지능][ML] Machine Learning - 분류모델 / 앙상블모델 / 배깅 / 부스팅 / 랜덤포레스트 (0) | 2023.12.26 |
| [인공지능][ML] Machine Learning - 선형회귀모델 / 다항회귀모델 / 다중회귀모델 (0) | 2023.12.21 |
| [인공지능][ML] Machine Learning - KNN 회귀모델 / 평균절대오차(MAE) (0) | 2023.12.21 |