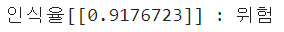new_Date 컬럼의 데이터를 이용해서, 0000-00(년-월) 단위로 추출하여, YM 컬럼 생성하기
''' 년-월 단위로 추출해서 YM 컬럼 생성하기 '''
df["YM"] = df["new_Date"].dt.to_period(freq="M")
''' 년-월-일 단위로 추출해서 YMD 컬럼 생성하기 '''
df["YMD"] = df["new_Date"].dt.to_period(freq="D")
new_Date 컬럼을 인덱스로 지정하기
df.set_index("new_Date", inplace=True)
df 데이터프레임의 0번째 행의 값을 추출
'''
df["2015-07-02"]
>> 이건 불가능 !! 인덱스가 RangeIndex가 아니면 직접 접근이 안되기 때문에 오류 발생
>> loc 또는 iloc를 사용해야함
'''
df_0 = df.iloc[0]
df_1 = df.loc["2015-07-02"]
df_0, df_1
인덱스 2016-06-29 ~ 2018-06-27까지의 행 조회하기
df.loc["2016-06-29":"2018-06-27"]
df 변수로 csv 파일 새로 불러들이고, new_Date 컬럼 생성 - Date 컬럼을 날짜 타입으로 변환해서 사용
''' 이미지 증식에 사용되는 라이브러리 '''
from keras.preprocessing.image import ImageDataGenerator
''' numpy 배열을 이미지로 변환하는 라이브러리 '''
from keras.preprocessing.image import array_to_img
''' 이미지를 numpy 배열로 변환하는 라이브러리 '''
from keras.preprocessing.image import img_to_array
''' 이미지를 읽어들이는 라이브러리 '''
from keras.preprocessing.image import load_img
''' 시각화 '''
import matplotlib.pyplot as plt
이미지 증식 객체 생성하기
📍 이미지 증식을 하는 이유? - 이미지를 이용하여 모델 훈련 시 데이터 확보가 어려운 경우 수행 - 기존 이미지 훈련모델의 성능이 낮은 경우에 데이터를 증가 시키고자 할 때 사용 - 이미지 증식은 하나의 원본 이미지 형태를 랜덤하게 변형시켜서 많은 양의 이미지를 생성 가능
이미지 증식개체 생성하기
imgGen = ImageDataGenerator(
### 이미지 데이터를 0과 1사이의 값으로 정규화하기
rescale=1./255,
### 이미지 회전시키기, 0 ~ 90 사이의 랜덤하게 회전
rotation_range=15,
### 수평이동 시키기, 0 ~ 1 사이의 비율에 따라 랜덤하게 이동
# - 0.1=10%, 10%의 비율로 좌/우 랜덤하게 이동
width_shift_range=0.1,
### 수직이동 시키기
height_shift_range=0.1,
### 이미지 형태 변형(반시계방향)
shear_range=0.5,
### 이미지 확대/축소(0.8 ~ 2.0 사이의 범위 값으로 랜덤하게 확대/축소)
zoom_range=[0.8, 2.0],
### 수평방향으로 뒤집기 여부
horizontal_flip=True,
### 수직방향으로 뒤집기 여부
vertical_flip=True,
### 이미지 변형 시 발생하는 빈 공간의 픽셀값 처리 방법 지정
# - nearset : 가까운 곳의 픽셀값으로 채우기(기본값, default, 생략가능, 주로 사용 됨)
# - reflect : 빈공간 만큼의 영역을 근처 공간의 반전된 픽셀값으로 채우기
# - warp : 빈공간을 이동하면서 잘려나간 이미지로 채우기
# - constant : 빈공간을 검정 또는 흰색으로 채우기
fill_mode="nearest"
)
원본 이미지 불러오기
img = load_img("./new_img/img_sample.jpg")
img
사용 이미지 ↓ (출처 : 말티즈 장군이)
이미지를 데이터화 시키기 - 이미지를 array 배열 데이터로 변환하기 - 3차원 데이터로 반환됨 - (높이, 너비, 채널)
### 반복을 종료하기 위한 coount값으로 사용
i = 0
### 생성할 이미지 갯수
cnt = 100
### 이미지를 반복해서 생성
# - flow() : imgGen객체를 이용해서 랜덤하게 만들어진 이미지를 저장시키는 함수
# - save_to_dir : 저장할 폴더 위치
# - save_prefix : 저장할 파일명에 사용할 이니셜, 이니셜 뒤에 자동으로 이름이 부여됨
# - save_format : 저장할 파일의 포멧, 파일명 뒤에 확장자 정의
for new_img in imgGen.flow(img_array,
save_to_dir="./new_img/new",
save_prefix="train",
save_format="png") :
''' 생성할 이미지 갯수까지만 반복 시키고 반복을 종료시키기 '''
if i > cnt :
break
''' 생성된 이미지 출력하기 '''
plt.imshow(new_img[0])
''' x, y축 그래프 숨기기 '''
plt.axis('off')
'''
반복하면서 이미지를 보여주는 경우에는 show()를 사용해야 한다.
- 그렇지 않으면 1개의 이미지만 보이게 된다.
- show() 이미지를 보여주고, 자원을 반환하는 역할도 같이 수행된다.
- 자원이 반환되야 다음 이미지를 plt를 통해서 사용가능하다.
'''
plt.show()
''' 반복을 위한 count값 증가 '''
i += 1
print(">>>>>>>>>> 이미지 증식 종료 <<<<<<<<<<<<")
사람이미지 증식 및 4차원 독립변수와 종속변수(라벨링) 생성하기
사용할 라이브러리
import os
import numpy as np
import pandas as pd
''' OpenCV 라이브러리 '''
import cv2
''' 이미지 증식 라이브러리 '''
from tensorflow.keras.preprocessing.image import ImageDataGenerator
''' 이미지를 numpy array(배열)로 변환하는 라이브러리 '''
from keras.preprocessing.image import img_to_array
특정 폴더 내에 모든 원본 이미지를 읽어들이는 함수 정의
특정 원본 이미지 폴더 내에 모든 이미지 파일을 읽어들여서, 이미지 픽셀 데이터로 변환해서 리턴하는 함수 정의
def load_images(directory) :
''' 긱 이미지별 변환 데이터를 저장할 리스트 변수 '''
images = []
''' 특정 디렉토리의 모든 파일 읽어들이기 '''
for filename in os.listdir(directory) :
''' 특정 확장자를 가지는 파일만 읽어들이기 '''
if filename.endswith((".jpg", ".jpeg", ".png")) :
''' 파일명 추출 '''
img_path = os.path.join(directory, filename)
''' 이미지를 3차원 데이터로 변환하기 '''
img = cv2.imread(img_path)
''' 이미지 데이터의 픽셀 크기를 너비 170, 높이 175로 통일시키기(정규화) '''
img = cv2.resize(img, (170, 175))
''' 변환된 이미지 데이터를 리스트 변수에 담기 '''
images.append(img)
''' numpy 배열로 변환하여 리턴 '''
return np.array(images)
읽어들인 모든 원본 이미지 각각에 대해서 이미지 증식 및 종속변수(라벨) 정의 함수
'''
- images : 원본 전체에 대한 각 이미지 데이터
- output_directory : 증식한 이미지를 저장할 폴더 위치
- target_filename : 종속변수 데이터를 저장할 (폴더+파일명)
'''
def create_images(images, output_directory, target_filename) :
### 종속 변수 데이터를 담을 리스트 변수
target = []
### 이미지 10개(원본 이미지 10개에 대)에 대한 라벨링 기준
# - 1은 위험인자, 0은 비위험인자
target_list = [1, 0, 1, 0, 1, 1, 0, 1, 1, 0]
############### 이미지 증식 객체 생성하기 ###############
datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.5,
zoom_range=[0.8, 2.0],
horizontal_flip=True,
vertical_flip=True,
fill_mode="nearest"
)
############### 이미지 증식 시키기 ###############
# - i : images의 인덱스 번소
# - img : 각 인덱스별 이미지 데이터
for i, img in enumerate(images) :
print(f"------------------ [{i + 1} /{len(images)}] 번째 증식 중 ------------------")
### 3차원 이미지 데이터를 4차원으로 변환하기
img = img.reshape((1,) + img.shape)
### 증식된 이미지를 저장할 파일명 정의
save_prefix = "train_img_" + str(i)
### 각 이미지 별로 생성(증식)할 이미지의 갯수 정의
create_img_cnt = 20
############### 이미지 증식 및 파일 저장 시키기 ###############
for batsh in datagen.flow(img,
save_to_dir=output_directory,
save_prefix=save_prefix,
save_format="png") :
### 증식된 이미지 별로 [종속변수]로 사용할 값을 리스트에 담기
target.append(target_list[i])
create_img_cnt -= 1
### 생성할 이미지 갯수만큼 만들어지면 종료시키기
if create_img_cnt == 0 :
break
### 종속변수 리스트를 numpy 배열 타입으로 변환하기
target = np.array(target)
### 종속변수 리스트를 numpy 파일로 저장시키기
# - target_filename : 저장할 폴더 + 파일명
# - target : 종속변수 리스트
np.save(target_filename, target)
'''
너무 많은 증식을 할 경우, 원하는 갯수만큼 증식이 안되는 경우가 있다.
- 증식을 만드는 시간과 시스템 폴더에 저장되는 시간차로 발생
- 많은 양을 만들경우 조금씩 여러번에 걸쳐서 증식
'''
증식한 이미지 폴던 내에 모든 이미지 파일을 차원 [4차원 데이터]로 변환 및 저장하는 함수
증식된 파일이 저장된 폴더 내 모든 파일에 대해서 4차원 데이터로 변환하여 numpy 배열 형태로 저장시키기
'''
- output_directory : 증식된 파일이 위치한 폴더
- save_4d_filename : 저장할 파일명
'''
def save_4d_data(output_directory, save_4d_filename) :
### 4차원 데이터를 담을 리스트 변수
data = []
### 증식된 모든 파일 읽어들이기
for filename in os.listdir(output_directory) :
if filename.endswith((".jpg", ".jpeg", ".png")) :
img_path = os.path.join(output_directory, filename)
### 3차원 데이터로 읽어들이기
img = cv2.imread(img_path)
### 픽셀 정규화
img = cv2.resize(img, (170, 175))
### 리스트에 담기
data.append(img)
data = np.array(data)
print(data.shape)
np.save(save_4d_filename, data)
함수 호출
특정 폴더 내에 모든 이미지파일 로드하여, 이미지 데이터로 변환하는 함수 호출
### 폴더 위치 지정
input_directory = "./data/01_org_img/"
### 함수 호출하기
images = load_images(input_directory)
images.shape
이미지 증식 및 파일저장, 종속변수 생성 및 파일 저장 함수 호출
### 증식된 이미지 파일 저장 폴더
output_directory = "./data/02_train_img/"
### 종속변수 데이터 파일명
# - numpy 파일의 확장자는 보통 .npy를 사용한다.
target_filename = "./data/03_train_4d_data/target_data.npy"
### 함수 호출하기
create_images(images, output_directory, target_filename)
# - coco.names : 인식(감지)된 객체의 레이블 명칭(이름)이 저장된 파일
''' 저장할 변수 정의 '''
classes = []
# open() : 파일 열기
# - 모드 : r 읽기모드, w 쓰기모드, b 바이너리
# as(별칭) f에는 열려있는 파일 정보가 담겨있음
with open("./yolo/config/coco.names", "r") as f :
# strip() : 왼쪽 오른쪽 공백제거
# readlines() : 파일 내에 문장들을 행단위로 모두 읽어들이기
classes = [line.strip() for line in f.readlines()]
classes
출력계층 이름 추출하기
''' YOLO 레이어 전체 추출 '''
layer_names = YOLO_net.getLayerNames()
''' YOLO 출력 레이어(계층)만 추출 '''
output_layer = [layer_names[i - 1] for i in YOLO_net.getUnconnectedOutLayers()]
layer_names, output_layer
윈도우 창 관리 영역 : 카메라 영상 처리 영역
import cv2
import numpy as np
VideoSignal = cv2.VideoCapture(0)
YOLO_net = cv2.dnn.readNet("./yolo/config/yolov2-tiny.weights",
"./yolo/config/yolov2-tiny.cfg")
classes = []
# open() : 파일 열기
# - 모드 : r 읽기모드, w 쓰기모드, b 바이너리
# as(별칭) f에는 열려있는 파일 정보가 담겨있음
with open("./yolo/config/coco.names", "r") as f :
# strip() : 왼쪽 오른쪽 공백제거
# readlines() : 파일 내에 문장들을 행단위로 모두 읽어들이기
classes = [line.strip() for line in f.readlines()]
''' YOLO 레이어 전체 추출 '''
layer_names = YOLO_net.getLayerNames()
''' YOLO 출력 레이어(계층)만 추출 '''
output_layer = [layer_names[i - 1] for i in YOLO_net.getUnconnectedOutLayers()]
'''
대표 윈도우 설정
- 윈도우 창 관리는 이름으로 한다.
'''
cv2.namedWindow("YOLO3_CM_01")
'''
카메라를 통한 영상처리 시에는 윈도우 창을 계속 띄어 놓아야 한다.
- 정지 옵션(윈도우 창 닫기)은 필수
'''
while True :
'''
카메라에서 영상 읽어들이기 : read() 함수 사용
- 영상파일 또는 카메라로부터 프레임을 읽어오는 역할 수행
* ret : 읽어들이는 프레임이 있는지 여부 판단(True or False)
: 더 이상 읽어들일 프레임이 없으면 False가 됨
* frame : 실제로 읽어들이는 프레임(이미지) 자체
: 더 이상 읽어들일 프레임이 없으면 None이 됨
: 우리가 사용할 변수
'''
ret, frame = VideoSignal.read()
''' frame 정보에서 높이, 너비, 채널(흑백 또는 컬러) 추출하기 '''
h, w, c = frame.shape
''' --------------------------------------------------------- '''
''' BLOB 데이터 구조화 '''
blob = cv2.dnn.blobFromImage(
### 카메라에서 읽어들인 frame(이미지) 데이터
image = frame,
### 이미지 픽셀 값 정규화(스케일링)
scalefactor = 1/255.0,
### Yolo 모델이 사용할 크기로 조정
size=(416, 416),
### BRG, RGB 선택
# - True이면 OpenCV의 기본 BGR 생상 순서를 RGB로 변경
swapRB=True,
### 위에 size로 조정 후 어떻게 할지 결정
# - True이면 잘라내기
# - Fasle이면 size 전체 조정하기
crop=False
)
''' YOLO 입력 데이터로 넣어주기 '''
YOLO_net.setInput(blob)
''' YOLO모델에 출력계층 이름을 알려주고, 출력 결과 받아오기 '''
outs = YOLO_net.forward(output_layer)
''' 라벨(명칭, 이름) 담을 리스트 변수 '''
class_ids = []
''' 인식률(정확도) 담을 리스트 변수 '''
confidences = []
''' 바운딩 박스의 좌표를 담을 리스트 변수 '''
boxes = []
''' 출력 결과 여러개(인식된 객체 여러개)'''
for out in outs :
''' 실제 객체 인식 데이터 처리 '''
for detection in out :
''' 인식 데이터의 인식률(정밀도) '''
scores = detection[5:]
''' 인식률(정밀도)가 가장 높은 인덱스 위치 얻기 : 라벨(명칭, 이름)의 위치값 '''
class_id = np.argmax(scores)
''' 인식률(정밀도) 값 추출하기 : class_id의 인덱스 번호 위치값이 정밀도 '''
confidence = scores[class_id]
''' 정밀도가 50% 이상인 경우만 처리 : 기준은 자유롭게 정의 '''
if confidence > 0.5 :
''' 중앙값의 좌표 비율에 실제 너비로 연산하여 중앙 x값 추출 '''
center_x = int(detection[0] * w)
''' 중앙값의 좌표 비율에 실제 높이로 연산하여 중앙 y값 추출 '''
center_y = int(detection[1] * h)
''' 바운딩 박스의 실제 너비와 높이 계산하기 '''
dw = int(detection[2] * w)
dh = int(detection[3] * h)
''' 바운딩 박스의 시작 좌표(x, y) 계산하기 '''
x = int(center_x - dw /2)
y = int(center_x - dh / 2)
boxes.append([x, y, dw, dh])
confidences.append(float(confidence))
class_ids.append(class_id)
'''
중복된 바운딩 박스 제거하기
-정확도가 0.45보다 작으면 제거
'''
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.45, 0.4)
''' 인식된 객체마다 바운딩 박스 처리하기 '''
for i in range(len(boxes)) :
''' 중복 제거 이후 남은 바운딩 박스의 정보만 이용 '''
if i in indexes :
''' 해당 객체에 대한 좌표값 '''
x, y, w, h = boxes[i]
''' 해당 객체에 대한 라벨값 '''
label = str(classes[class_ids[i]])
''' 해당 객체에 대한 정확도 '''
score = confidences[i]
''' 바운딩 박스 그리기 '''
cv2.rectangle(
### 원본 이미지(frame)
frame,
### 시작좌표
(x, y),
### 종료좌표
(x+w, y+h),
### 선 색상
(0, 0, 255),
### 선 굵기
5
)
''' 라벨, 정확도 이미지에 텍스트 그리기 '''
cv2.putText(
### 지금까지 그려진 frame 이미지
img = frame,
### 추가할 텍스트(문자열 타입으로)
text = label,
### 텍스트 시작위치 지정
org=(x, y-20),
### 텍스트 font 스타일
fontFace=cv2.FONT_ITALIC,
### font 크기
fontScale=0.5,
### font 색상
color=(255, 255, 255),
### font 굵기
thickness=1
)
''' 윈도우 창 open하기 '''
cv2.imshow("YOLO3_CM_01", frame)
''' 윈도우 창 크기 조절하기 '''
cv2.resizeWindow("YOLO3_CM_01", 650, 500)
''' 키보드에서 아무키 눌리면, while문 종료하기 '''
if cv2.waitKey(100) > 0 :
''' 윈도우 무조건 종료 '''
cv2.destroyAllWindows()
break
''' 키보드에서 q 입력 시 종료시키기 '''
if cv2.waitKey(1) & 0xFF == ord("q") :
''' 윈도우 무조건 종료 '''
cv2.destroyAllWindows()
break
'''
위도우 종료 후 재실행 시 안되는 경우가 발생할 수 있음.
이때는 주피터가 실행된 프롬프트 창에서 [CTRL+C]
'''
YOLO - Camera 객체탐지 이미지로 추출하기
정확도가 0.8 이상일 때 이미지 저장
import cv2
import numpy as np
VideoSignal = cv2.VideoCapture(0)
YOLO_net = cv2.dnn.readNet("./yolo/config/yolov2-tiny.weights",
"./yolo/config/yolov2-tiny.cfg")
classes = []
# open() : 파일 열기
# - 모드 : r 읽기모드, w 쓰기모드, b 바이너리
# as(별칭) f에는 열려있는 파일 정보가 담겨있음
with open("./yolo/config/coco.names", "r") as f :
# strip() : 왼쪽 오른쪽 공백제거
# readlines() : 파일 내에 문장들을 행단위로 모두 읽어들이기
classes = [line.strip() for line in f.readlines()]
''' YOLO 레이어 전체 추출 '''
layer_names = YOLO_net.getLayerNames()
''' YOLO 출력 레이어(계층)만 추출 '''
output_layer = [layer_names[i - 1] for i in YOLO_net.getUnconnectedOutLayers()]
cv2.namedWindow("YOLO3_CM_01")
############################
### 인식된 객체 이미지로 저장
# - 이미지 파일 저장 시 파일명에 번호 붙이기
img_cnt = 1
############################
'''
카메라를 통한 영상처리 시에는 윈도우 창을 계속 띄어 놓아야 한다.
- 정지 옵션(윈도우 창 닫기)은 필수
'''
while True :
'''
카메라에서 영상 읽어들이기 : read() 함수 사용
- 영상파일 또는 카메라로부터 프레임을 읽어오는 역할 수행
* ret : 읽어들이는 프레임이 있는지 여부 판단(True or False)
: 더 이상 읽어들일 프레임이 없으면 False가 됨
* frame : 실제로 읽어들이는 프레임(이미지) 자체
: 더 이상 읽어들일 프레임이 없으면 None이 됨
: 우리가 사용할 변수
'''
ret, frame = VideoSignal.read()
''' frame 정보에서 높이, 너비, 채널(흑백 또는 컬러) 추출하기 '''
h, w, c = frame.shape
''' --------------------------------------------------------- '''
''' BLOB 데이터 구조화 '''
blob = cv2.dnn.blobFromImage(
### 카메라에서 읽어들인 frame(이미지) 데이터
image = frame,
### 이미지 픽셀 값 정규화(스케일링)
scalefactor = 1/255.0,
### Yolo 모델이 사용할 크기로 조정
size=(416, 416),
### BRG, RGB 선택
# - True이면 OpenCV의 기본 BGR 생상 순서를 RGB로 변경
swapRB=True,
### 위에 size로 조정 후 어떻게 할지 결정
# - True이면 잘라내기
# - Fasle이면 size 전체 조정하기
crop=False
)
''' YOLO 입력 데이터로 넣어주기 '''
YOLO_net.setInput(blob)
''' YOLO모델에 출력계층 이름을 알려주고, 출력 결과 받아오기 '''
outs = YOLO_net.forward(output_layer)
''' 라벨(명칭, 이름) 담을 리스트 변수 '''
class_ids = []
''' 인식률(정확도) 담을 리스트 변수 '''
confidences = []
''' 바운딩 박스의 좌표를 담을 리스트 변수 '''
boxes = []
''' 출력 결과 여러개(인식된 객체 여러개)'''
for out in outs :
''' 실제 객체 인식 데이터 처리 '''
for detection in out :
''' 인식 데이터의 인식률(정밀도) '''
scores = detection[5:]
''' 인식률(정밀도)가 가장 높은 인덱스 위치 얻기 : 라벨(명칭, 이름)의 위치값 '''
class_id = np.argmax(scores)
''' 인식률(정밀도) 값 추출하기 : class_id의 인덱스 번호 위치값이 정밀도 '''
confidence = scores[class_id]
''' 정밀도가 50% 이상인 경우만 처리 : 기준은 자유롭게 정의 '''
if confidence > 0.5 :
''' 중앙값의 좌표 비율에 실제 너비로 연산하여 중앙 x값 추출 '''
center_x = int(detection[0] * w)
''' 중앙값의 좌표 비율에 실제 높이로 연산하여 중앙 y값 추출 '''
center_y = int(detection[1] * h)
''' 바운딩 박스의 실제 너비와 높이 계산하기 '''
dw = int(detection[2] * w)
dh = int(detection[3] * h)
''' 바운딩 박스의 시작 좌표(x, y) 계산하기 '''
x = int(center_x - dw /2)
y = int(center_x - dh / 2)
boxes.append([x, y, dw, dh])
confidences.append(float(confidence))
class_ids.append(class_id)
'''
중복된 바운딩 박스 제거하기
-정확도가 0.45보다 작으면 제거
'''
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.45, 0.4)
''' 인식된 객체마다 바운딩 박스 처리하기 '''
for i in range(len(boxes)) :
''' 중복 제거 이후 남은 바운딩 박스의 정보만 이용 '''
if i in indexes :
''' 해당 객체에 대한 좌표값 '''
x, y, w, h = boxes[i]
''' 해당 객체에 대한 라벨값 '''
label = str(classes[class_ids[i]])
''' 해당 객체에 대한 정확도 '''
score = confidences[i]
''' 바운딩 박스 그리기 '''
cv2.rectangle(
### 원본 이미지(frame)
frame,
### 시작좌표
(x, y),
### 종료좌표
(x+w, y+h),
### 선 색상
(0, 0, 255),
### 선 굵기
5
)
''' 라벨, 정확도 이미지에 텍스트 그리기 '''
cv2.putText(
### 지금까지 그려진 frame 이미지
img = frame,
### 추가할 텍스트(문자열 타입으로)
text = label,
### 텍스트 시작위치 지정
org=(x, y-20),
### 텍스트 font 스타일
fontFace=cv2.FONT_ITALIC,
### font 크기
fontScale=0.5,
### font 색상
color=(255, 255, 255),
### font 굵기
thickness=1
)
''' 윈도우 창 open하기 '''
cv2.imshow("YOLO3_CM_01", frame)
''' 윈도우 창 크기 조절하기 '''
cv2.resizeWindow("YOLO3_CM_01", 650, 500)
###########################################################
### 이미지로 저장하기
print(f">>>>>>>>>>>>>>정확도 평균 : {np.mean(confidences)}")
### 정확도 평균이 0.8이상인 경우만 저장시키기
if np.mean(confidences) >= 0.8 :
# 이미지 저장 함수 : imwrite() 함수 사용
cv2.imwrite(f"./yolo/images_new/img_{img_cnt}.jpg", frame)
img_cnt = img_cnt + 1
############################################################
''' 키보드에서 아무키 눌리면, while문 종료하기 '''
if cv2.waitKey(100) > 0 :
''' 윈도우 무조건 종료 '''
cv2.destroyAllWindows()
break
''' 키보드에서 q 입력 시 종료시키기 '''
if cv2.waitKey(1) & 0xFF == ord("q") :
''' 윈도우 무조건 종료 '''
cv2.destroyAllWindows()
break
'''
위도우 종료 후 재실행 시 안되는 경우가 발생할 수 있음.
이때는 주피터가 실행된 프롬프트 창에서 [CTRL+C]
'''
📍 YOLO(You Only Look Once) - '욜로'라고 칭한다. - 한개의 네트워크(계층, 모델 같은 의미로 칭함)에서 객체(물체, 사물)을 탐지 - 탐지된 객체의 영역(바운딩 박스-사각형)과 객체의 이름(사람, 고양이...)을 표시해 주는 기능을 수행함 - 객체 탐지 기술이라고 해서 "Object Detection"이라고 언어 소통이 된다.
📍 객체탐지 - 객체탐지는 컴퓨터 비전 기술의 세부 분야 중 하나로 - 주어진 이미지 또는 영상 내에 사용자가 관심있는 객체를 탐지하는 기술을 의미함 - 객체탐지 모델을 만들기에 앞서 바운딩 박스를 만드는 것이 우선시 되어야 함 - 바운딩 박스란? 사각형의 시작 좌표(x1, y1), 종료 좌표(x2, y2)로 표현되는 타겟 위치(객체 위치)를 사각형으로 표현한 것을 의미함
📍 YOLO 원리 - 이미지를 입력으로 받음(이미지파일 또는 카메라에서 들어오는 영상) - 이미지파일, 영상파일 등을 이용해서 numpy의 배열(array)로 데이터 생성이 가능하다면 처리가능 - 이미지를 내부를 격자(그리드)로 세분화해서 예측하는 구조를 가짐 - 예측된 부분은 바운딩박스로 그려줌 - 이미 훈련된 모델을 사용할 수 있기 때문에 별도의 훈련모델을 생성하지 않아도 됨 - (경우에 따라, 별도의 객체 인지를 위해 재훈련하여 사용하는 경우도 있음)
📍 YOLO 사용법 - Yolo를 사용하기 위해서는 YOLO 기반의 딥러닝 프레임워크가 필요함
📍 YOLO 기반의 딥러닝 프레임워크 종류 💡 DarkNet 프레임워크 - Yolo 개발자가 만든 프레임워크 -장점 : 객체 탐지 속도가 빠름, GPU 또는 CPU와 함께 사용 가능 -단점 : 리눅스 운영체제(os)에서 안정적으로 작동됨 : GPU와 CPU 동시 사용 시에 속도가 빠름 💡Darkflow 프레임워크 -DarkNet 프레임워크를 Tensorflow에 적용한 것 -장점 : DarkNet과 동일 : 리눅스, 윈도우, 맥과 호환가능 - 단점 : 설치가 매우 복잡함 💡OpenCV 프레임워크 - 주로 사전 개발테스트 시에 많이 사용되는 프레임워크 - 장점 : 설치가 간단하며 리눅스, 윈도우, 맥과 호환가능 -단점 : CPU에서만 작동함 : 실시간 영상 처리시에 속도가 다소 느릴 수 있음
사용하는 이미지 파일이름에 해당하는 바운딩박스의 xy 좌표값 추출하기 - vid_4_1000.jpg 이미지 파일이름은 0번째 인덱스에 있음 - 0번째 인덱스의 모든 컬럼값 추출하기
point = box.iloc[0]
point, type(point)
시작 좌표(xmin, ymin)와 종료 좌표(xmax, ymax) 추출하기 - 시작 좌표 변수 : pt1 = (xmin, ymin) - 종료 좌표 변수 : pt2 = (xmax, ymax) - 시작과 종료 좌표는 튜플 타입으로 생성 - 각 포인트 값은 정수 타입으로 변환
자동차 좌표값을 이용해서 이미지에 바운딩박스 그리기 - rectangle() : 사각형(바운딩박스는 사각형으로 표시하기 위해)을 그리는 함수 - sample : 원본 이미지 데이터 - pt1 : 박스의 시작점 좌표 - pt2 : 박스의 종료 좌표 - color : 박스 선의 색 - thickness : 박스 선의 굵기 지정
cv2.rectangle(sample, pt1, pt2, color=(255, 0, 0), thickness=2)
''' 이미지에 바운딩박스를 그리고 잘 보이는지 다시 imshow() 하기 '''
plt.imshow(sample)
기존의 그림에 바운딩박스라는 하나의 그림이 더 그려진 것
이미지 파일(vid_4_10000.jpg)에 대한 바운딩 박스 그려보기
''' 이미지 불러오기 '''
sample2 = cv2.imread('./yolo/cardataset/training_images/vid_4_10000.jpg')
''' RGB 순서로 변경하기 '''
sample = cv2.cvtColor(sample2, cv2.COLOR_BGR2RGB)
''' 해당 이미지 파일에 대한 좌표값 추출하기 '''
point = box.iloc[1]
''' 시작좌표 종료좌표 생성하기 '''
pt1 = (int(point["xmin"]), int(point["ymin"]))
pt2 = (int(point["xmax"]), int(point["ymax"]))
''' 원본 이미지에 바운딩 박스 그리기 '''
cv2.rectangle(sample, pt1, pt2, color=(255, 0, 0), thickness=2)
''' 이미지에 바운딩박스를 그리고 잘 보이는지 다시 imshow() 하기 '''
plt.imshow(sample)
YOLO에서 제공된 가중치 모델을 이용해서 객체(자동차) Detection하기
📍사용되는 파일 - yolov3.weignts : 이미 훈련된 모델의 가중치 데이터 파일 - yolov3.cfg : yolo 모델 매개변수 설정 파일 - coco.names : 인식(감지)된 객체의 레이블 명칭(이름)이 저장된 파일
가중체 데이터 및 환경설정 파일 읽어들이기 - DNN(심층신경망) 모델을 사용하여 모델 셋팅하기 - 첫번째 인자 : 가중치 파일 - 두번째 인자 : 모델 설정 파일
net = cv2.dnn.readNet("./yolo/config/yolov3.weights",
"./yolo/config/yolov3.cfg")
net
레이블 명칭(이름) 데이터 읽어들이기 - 인식한 객체에 대한 이름을 표시하기 위함
''' 저장할 변수 정의 '''
classes = []
# open() : 파일 열기
# - 모드 : r 읽기모드, w 쓰기모드, b 바이너리
# as(별칭) f에는 열려있는 파일 정보가 담겨있음
with open("./yolo/config/coco.names", "r") as f :
# strip() : 왼쪽 오른쪽 공백제거
# readlines() : 파일 내에 문장들을 행단위로 모두 읽어들이기
classes = [line.strip() for line in f.readlines()]
classes
YOLO가 사용하는 계층 구조 확인하기 - 우리가 사용했던 summary()함수의 기능과 유사
net.getLayerNames()
YOLO에서 사용하는 출력계층 확인하기 - YOLO는 객체 검출을 위해서 여러 개의 출력 계층을 사용하고 있음 - 객체 탐지 시에 출력계층에서 출력해준 값들을 이용해서 사용 > 바운딩 박스의 좌표값, 객체 인지 정확도, 인지된 객체의 레이블 명칭(이름) 등의 출력을 담당함 -net.getUnconnectedOutLayers() : 출력계층 추출함수로 출력계층의 인덱스 위치를 반환해줌 : 다음 계층과 연결되지 않은(UnConnect) 마지막 계층(OutLayer)을 추출하는 함수 - layer_names[i-1] :-1을 한 이유? 반환값의 인덱스 순서는 1부터 시작된 인덱스 값이다. 따라서 1을 빼주면 됨
output_layer = [layer_names[i-1] for i in net.getUnconnectedOutLayers()]
print(net.getUnconnectedOutLayers())
output_layer
바운딩박스의 시작좌표와 종료좌표값을 계산할 때 사용할 높이와 너비 추출 - yolo 출력계층에서 예측한 좌표값은 객체의 중심점 좌표에 대한 비율값을 추출함 - 비율에 실제 높이와 너비를 이용해서 예측된 중심점 좌표와 계산하여 바운딩박스의 시작좌표와 종료좌표를 정의해야 함
📍 Blob(Binary Large Object) - Blob는 이미지 처리 및 딥러닝에서 사용되는 데이터 구조임 - 이미지나 동영상에서 추출된 특정 부분이나 물체를 나타내기 위한 데이터 구조형태로 되어 있음 - 주로 딥러닝 모델에 이미지를 전달하거나 이미지 프로세싱 작업에서 특정 부분을 추출하여 처리하는 데 사용되는 구조임 (객체 탐지용 데이터 구조라고 이해하면 된다) - Yolo 모델에서 사용되는 데이터 구조가 Blob 구조를 따름 > 사용할 이미지를 Blob 데이터 구조로 변환한 후에 Yolo 네트워크(모델)에 전달하여 객체를 검출하게 됨
- Blob 데이터 구조에 포함될(된) 수 있는 값들 > 이미지 데이터 : 이미지 또는 영상 프레임(이미지)에서 추출된 특졍 영역에 대한 이미지 데이터 > 채널 정보 : 컬러 이미지인 경우 RGB 또는 BGR과 같은 컬러 정보 > 공간 차원 정보 : 높이와 너비 > 픽셀 값 범위 : 0 ~ 255까지의 값을 갖는 흑백 이미지 데이터 또는 -1 ~ 1 or 0 ~ 1 사이의 정규화 된 이미지 값
- Yolo 모델(네트워크)에서는 이미지 데이터를 바로 사용할 수 없음 >먼저 이미지를 Blob 데이터 형태로 변환해야 함 >Blob 데이터를 통해 Yolo가 예측할 수 있도록 이미지에서 특징을 찾아내고 크기를 저장하는 작업을 수행함 >이미지 크기 저장을 이미지 크기 정규화라고 함 → 이미지 크기 정규화 : 사용되는 높이와 너비의 이미지 사이즈를 통일 시키는 작업
- Yolo에서 사용되는 이미지 크기 >320 x 320 : 이미지가 작고 정확도는 떨어지지만 속도가 빠름 >609 x 609 : 이미지가 크고 정확도는 높지만 속도가 느림 >416 x 416 : 이미지 중간크기, 정확도와 속도가 적당함 (주로 사용되는 크기임)
원본 이미지 데이터를 Blob로 변환하면서, 동시에 정규화(사이즈 통일) 하기 - 사용 함수 :cv2.dnn.blobFromImage() - 4차원으로 반환됨 - img : 원본 이미지 데이터 - 1/256 : 픽셀값에서 256으로 나누어서 데이터 정규화 진행 : 0 ~ 1 사이의 값으로 정규화 - (416, 416) : 높이와 너비의 사이즈를 통일시키는 정규화 진행 - (0, 0, 0) : 원본 이미지와 채널 값을 그레이 색으로 변환하기 - swapRB : RGB에서 R값과 B값을 바꿀 것인지 결정(기본값 False) : True인 경우 BRG를 RGB로 변경 - crop : 크기를 조정한 후에 이미지를 자를지 여부 결정 : 일반적으로 자르면 안되기에 False 지정(기본값 False) : 크기가 변경된 사이즈로 이미지를 변환해서 사용할지, 아니면 변경 사이즈 부분을 제외하고 자를지 결정
입력데이터를 이용해서 예측된 출력결과 받아오기 - net.forward() : Yolo 모델이 이미지 내에 있는 객체를 인식하여 정보를 출력해준다 : 이때, 출력계층의 이름을 넣어서, 해당 출력계층의 값이 반환되게 된다.
outs = net.forward(output_layer
# outs
'''
array 배열의 3개 데이터를 튜플형태로 반환함
- 각 튜플은 출력계층 3개가 출력해준 값들임
'''
len(outs)
인식된 객체(물체) 좌표, 레이블명칭(이름), 정확도 확인하기
''' 인식된 객체(물체)의 인덱스 번호를 담을 변수 '''
class_ids = []
''' 인식된 객체의 인식률(정확도)를 담을 변수 '''
confidences = []
''' 인식된 객체의 좌표값을 담을 변수 '''
boxes = []
''' 출력계층이 반환한 값들을 처리하기 위하여 반복문 사용 '''
for out in outs :
# print(out)
''' 인식된 객체에 대한 정보가 담겨 있음 '''
for detection in out :
'''
- 0번 인덱스 값 : 인식된 객체(바운딩박스)의 x 중심좌표 비율값
- 1번 인덱스 값 : 인식된 객체(바운딩박스)의 y 중심좌표 비율값
- 2번 인덱스 값 : 바운딩 박스의 너비 비율값
- 3번 인덱스 값 : 바운딩 박스의 높이 비율값
- 4번 인덱스 값 : 물체 인식률
- 5번 인덱스부터 전체 : 바운딩 박스에 대한 클래스(레이블 명칭(이름)) 확률 값들
> 5번 이후의 갯수는 레이블의 갯수(클래스 수)만큼
> 레이블 이름은 실제 레이블의 값들과 비교하여 가장 높은 값을 가지는 인덱스의 값을 이용하여 실제 레이블 이름을 추출함
'''
# print(detection)
''' 인식된 객체에 대한 정보 추출하기(클래스=레이어 명칭) 확률 정보 '''
scores = detection[5:]
# print(len(scores),scores)
'''
scores 값이 가장 큰 인덱스번호 찾기
- 0은 인식 못했다는 의미
- 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
- 가장 큰 인덱스 값 : 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
'''
class_id = np.argmax(scores)
# print(class_id)
''' score 값이 가장 큰 위치의 인덱스 번호에 해당하는 값은 인식률(정확도를 의미) '''
confidence = scores[class_id]
# print(confidence)
''' 정확도(인식률, 탐지율) 50% 이상인 데이터에 대해서 처리하기 '''
if confidence > 0.5 :
# print(f"scores : {scores}")
# print(f"class_id : {class_id}")
# print(f"confidence : {confidence}")
''' 바운딩 박스의 상대적 중심 x, y좌표 비율 추출하여 실제 중심점 길이 좌표(절대 좌표)로 변환하기 '''
''' 실제 중심점 x좌표 '''
center_x = int(detection[0] * width)
''' 실제 중심점 y좌표 '''
center_y = int(detection[1] * height)
print(center_x, center_y)
''' 바운딩 박스의 상대적 너비와 높이 비율 추출하기 '''
''' 실제 너비로 변환 '''
w = int(detection[2] * width)
''' 실제 높이로 변환 '''
h = int(detection[3] * height)
print(w, h)
''' 시작점 좌표 계산하기 '''
x = int(center_x - w / 2)
y = int(center_y - h / 2)
print(x, y)
'''
- 이미지 좌표계는 좌상단이 0, 0
- 그래프 좌표계는 좌하단이 0, 0
'''
''' 실제 x, y, 너비, 높이 담기 '''
boxes.append([x, y, w, h])
''' 객체 인식률(정확도) 실수형 타입으로 담기 '''
confidences.append(float(confidence))
''' 레이블 명칭(이름) 인덱스 담기 '''
class_ids.append(class_id)
print(boxes)
print(confidences)
print(class_ids)
중복된 바운딩박스 제거하기
인식된 객체별로 1개의 바운딩 박스만 남기기 - cv2.dnn.NMSBoxes() : 중복 바운딩 박스 제거하는 함수 - boxes : 추출된 바운딩 박스 데이터 - confidences : 바운딩 박스별 정확도 - 0.5 : 정확도에 대한 임계값, 바운딩 박스 정확도가 0.5보다 작으며 박스 제거 - 0.4 : 비최대 억제 임계값이라고 칭한다. 이 값보다 크면 박스 제거 시킨다.
'''
<폰트 스타일 지정>
'''
font = cv2.FONT_HERSHEY_PLAIN
'''
<바운딩 박스의 색상 지정하기>
- 인식된 객체가 많은 경우, 각각 색상을 지정해서 구분해 줄 필요성이 있기 때문에
> 랜덤하게 색상을 추출하여 정의
- np.random.uniform() : 랜덤한 값 추출 함수
- 색상을 RGB의 형태로 추출하기 위해 값의 범위는 0 ~ 255를 사용
- 0, 255 : RGB 각 값의 랜덤 범위
- size=(len(boxes), 3) : 추출할 사이즈 : 행, 열 정의
> 인식된 각 바운딩 박스의 갯수만큼, 3개씩의 RGB값 추출을 의미함
'''
colors = np.random.uniform(0, 255, size=(len(boxes), 3))
### 인식된 객체가 있는 경우
if len(indexes) > 0 :
''' 무조건 1차원으로 변환 '''
print(indexes.flatten())
for i in indexes.flatten() :
''' x, y, w, h 값 추출하기 '''
x, y, w, h = boxes[i]
print(x, y, w, h)
''' 실제 레이블 명칭(이름) 추출하기 '''
label = str(classes[class_ids[i]])
print(label)
''' 인식률(정확도) 추출하기 '''
confidence = str(round(confidences[i], 2))
print(confidence)
''' 바운딩 박스의 색상 추출하기 '''
color = colors[i]
print(color)
''' 바운딩 박스 그리기
- 마지막 값 2 : 바운딩 박스 선의 굵기
'''
cv2.rectangle(img, (x, y), ((x + w),(y + h)), color, 2)
''' 인식된 객체의 레이블 명칭(이름)과 정확도 넣기(그리기)
* putText() : 원본 이미지에 텍스트 넣는 함수
- img : 원본 이미지
- label : 인식된 레이블 명칭(이름)
- confidence : 인식률(정확도)
- (x, y+20) : 텍스트 시작 좌표
- font : 폰트 스타일
- font 다음의 숫자 2 : 폰트 사이즈
- (0, 255, 0) : 폰트 색상
- 마지막 숫자 2 : 폰트 굵기
'''
cv2.putText(img, label + " " + confidence,
(x, y+20), font, 2, (0, 255, 0), 2)
plt.imshow(img)
### 인식된 객체가 없는 경우
else :
print("인식된 객체가 없습니다.")
Yolo 모델로 위에서 처리한 부분을 함수로 정의하기
함수 정의
'''
- 함수 이름 : predict_yolo(img_path)
'''
def predict_yolo(img_path) :
''' 샘플 이미지 데이터 가져오기 '''
img = cv2.imread(img_path)
''' BRG를 RGB로 변환하기 '''
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
height, width, channel = img.shape
blob = cv2.dnn.blobFromImage(
img,
1/256,
(416, 416),
(0, 0, 0),
swapRB = True,
crop = False
)
''' Yolo 모델에 입력 데이터로 넣어주기 '''
net.setInput(blob)
outs = net.forward(output_layer)
### -------------------------------------------------------------------
''' 인식된 객체(물체)의 인덱스 번호를 담을 변수 '''
class_ids = []
''' 인식된 객체의 인식률(정확도)를 담을 변수 '''
confidences = []
''' 인식된 객체의 좌표값을 담을 변수 '''
boxes = []
''' 출력계층이 반환한 값들을 처리하기 위하여 반복문 사용 '''
for out in outs :
# print(out)
''' 인식된 객체에 대한 정보가 담겨 있음 '''
for detection in out :
# print(detection)
''' 인식된 객체에 대한 정보 추출하기(클래스=레이어 명칭) 확률 정보 '''
scores = detection[5:]
# print(len(scores),scores)
'''
scores 값이 가장 큰 인덱스번호 찾기
- 0은 인식 못했다는 의미
- 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
- 가장 큰 인덱스 값 : 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
'''
class_id = np.argmax(scores)
# print(class_id)
''' score 값이 가장 큰 위치의 인덱스 번호에 해당하는 값은 인식률(정확도를 의미) '''
confidence = scores[class_id]
# print(confidence)
''' 정확도(인식률, 탐지율) 50% 이상인 데이터에 대해서 처리하기 '''
if confidence > 0.5 :
# print(f"scores : {scores}")
# print(f"class_id : {class_id}")
# print(f"confidence : {confidence}")
''' 바운딩 박스의 상대적 중심 x, y좌표 비율 추출하여 실제 중심점 길이 좌표(절대 좌표)로 변환하기 '''
''' 실제 중심점 x좌표 '''
center_x = int(detection[0] * width)
''' 실제 중심점 y좌표 '''
center_y = int(detection[1] * height)
# print(center_x, center_y)
''' 바운딩 박스의 상대적 너비와 높이 비율 추출하기 '''
''' 실제 너비로 변환 '''
w = int(detection[2] * width)
''' 실제 높이로 변환 '''
h = int(detection[3] * height)
# print(w, h)
''' 시작점 좌표 계산하기 '''
x = int(center_x - w / 2)
y = int(center_y - h / 2)
# print(x, y)
'''
- 이미지 좌표계는 좌상단이 0, 0
- 그래프 좌표계는 좌하단이 0, 0
'''
''' 실제 x, y, 너비, 높이 담기 '''
boxes.append([x, y, w, h])
''' 객체 인식률(정확도) 실수형 타입으로 담기 '''
confidences.append(float(confidence))
''' 레이블 명칭(이름) 인덱스 담기 '''
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
### ---------------------------------------------------------------------
'''
<폰트 스타일 지정>
'''
font = cv2.FONT_HERSHEY_PLAIN
''' 바운딩 박스의 색상 지정하기 '''
colors = np.random.uniform(0, 255, size=(len(boxes), 3))
### 인식된 객체가 있는 경우
if len(indexes) > 0 :
''' 무조건 1차원으로 변환 '''
print(indexes.flatten())
for i in indexes.flatten() :
''' x, y, w, h 값 추출하기 '''
x, y, w, h = boxes[i]
# print(x, y, w, h)
''' 실제 레이블 명칭(이름) 추출하기 '''
label = str(classes[class_ids[i]])
# print(label)
''' 인식률(정확도) 추출하기 '''
confidence = str(round(confidences[i], 2))
# print(confidence)
''' 바운딩 박스의 색상 추출하기 '''
color = colors[i]
# print(color)
''' 바운딩 박스 그리기
- 마지막 값 2 : 바운딩 박스 선의 굵기
'''
cv2.rectangle(img, (x, y), ((x + w),(y + h)), color, 2)
''' 인식된 객체의 레이블 명칭(이름)과 정확도 넣기(그리기) '''
cv2.putText(img, label + " " + confidence,
(x, y+20), font, 2, (0, 255, 0), 2)
plt.imshow(img)
### 인식된 객체가 없는 경우
else :
print("인식된 객체가 없습니다.")
함수 호출
''' 테스트 이미지 모두 가지고 오기 '''
import glob
import random
paths = glob.glob("./yolo/cardataset/testing_images/*.jpg")
''' 랜덤하게 이미지 선택하기 '''
img_path = random.choice(paths)
img_path
''' 파일 경로의 문자열 내에 역슬래시(\)를 슬래시(/)로 바꾸기 '''
img_path = img_path.replace("\\", "/")
img_path
''' 함수 호출하기 '''
print(f"인식에 사용된 이미지 파일명 : {img_path}")
predict_yolo(img_path)
📍합성곱신경망(CNN, Convolutional Neural Network) - 이미지 분석에 주로 사용되는 대표적 계층 - 기존의 인공신경망에서의 이미지 분석시에는 높이와 너비를 곱한 1차원을 사용하였다면CNN은 원형 그대로의 높이와 너비 차원을 사용함 - 전체 4차원의 데이터를 사용함
- 기존 이미지 분석 시 높이와 너비를 곱하여 사용하다보면, 원형 그대로의 주변 이미지 공간 정보를 활용하지 못하는 단점이 있으며, 이러한 이유로 특징 추출을 잘 못하여, 학습이 잘 이루어지지 않는 경우가 발생함
- 이러한 기존 인공신경망 모델의 단점을 보완하여 만들어진 모델이 CNN임 * 원형 형태의 이미지 정보를 그대로 유지한 상태로 학습 가능하도록 만들어졌음 *이미지의 공간정보를 이용하여 특징을 추출함 *인접 이미지의 특징을 포함하여 훈련됨
📍 합성곱 신경망(CNN)의 계층 구조 1. 입력 계층(Input_Layor) - 데이터 입력 계층 (기존과 동일) 2. 합성곱 계층(Convolutional Layor, CNN 계층) - 이미지의 특징을 추출하는 합성곱 계층이 여러층으로 구성되어 있음 3. 활성화 함수 계층 (은닉계층, Actiation Layer) -합성곱 계층의 출력에 대한 비선형성 추가한 활성화 함수 ReLU와 같은 함수 적용 4. 풀링 계층(Pooling Layer) - 공간 크기를 줄이고 계산량을 감소시키기 위한 계층(중요 특징만 추출하는 계층) - 풀링 방법으로 최대풀링(Max Pooling), 평균풀링(Average Pooling)이 있음 - 주로 Max Pooling 사용됨 5. 완전연결 계층 (은닉계층, Dense Layer) - 추출된 특징을 이용하여 최종 예측을 수행하는 계층 - 이때는 기본의 방법과 동일하게 1차원(높이 x 높이)의 전처리 계층(Plattern)을 사용하는 경우도 있음 (인공신경망 모델과 동일한 계층 구조로 진행) 6. 출력 계층(Output Layer) - 최종 예측이 이루어지는 계층
*** CNN에서 2 ~ 5번의 계층구조가 일반적으로 사용됨, 나머지 계층은 기존과 동일한 계층 *** 2 ~ 5번의 CNN계층은 여러개 추가 가능
라이브러리
import tensorflow as tf
from tensorflow import keras
💡 CNN - 데이터와 필터(filter)가 곱해진다고 해서 합성곱이라는 단어가 붙었음 - 이미지와 같은 2차원 데이터 분류에는 보통 2차원 합성곱(Conv2D)이 사용됨 - 입력 계층으로 사용하는 경우에는 input_shape의 입력 차원 속성을 함께 사용
📍 kernel_size - 이미지를 훑으면서 특징을 추출하는 역할을 수행 - 필터가 사용할 사이즈를 정의함 - kernel_size=3 > 필터가 사용할 사이즈 3행 3열을 의미함(3 X 3을 줄여서 3이라고 칭함) - 커널 사이즈는 홀수로 정의함(3, 5가 주로 사용됨)
📍 filters - 커널사이즈의 행렬의 공간 1개에 대한 필터의 갯수 정의 - 데이터를 훑으면서 특징을 감지함 - 필터의 값이 클수록 훈련속도가 오래 걸림 - 보통 32, 64가 주로 사용됨 - CNN계층을 여러개 사용하는 경우네는 처음 CNN계층에는 작은값부터 시작 → 16, 32, 64, 128 정도가 주로 사용됨 📍 padding - 경계 처리 방식을 정의함 - 입력 데이터의 주변에 추가되는 가상의 공간을 만들 수 있음 - 처리방식 : same과 valid가 있음 * same : 패딩을 사용하여 입력과 출력의 크기를 동일하게 만들어서 훈련하고자 할 때 사용 : 주로 권장되는 방식 * valid : 패딩을 사용하지 않음을 의미함 📍 strides - 커널이 이미지 데이터를 훑을 때(특징 추출 시)의 스탭을 정의함 - 커널이 데이터 특징 추출 순서(행렬을 기준으로) → 왼쪽 상단에서 시작하여 오른쪽으로 이동하는 스텝 정의 → 오른쪽 열을 다 훑고난 다음 아래로 이동하는 스텝 정의 - strides=1 : 오른쪽으로 1씩 이동, 아래로 1씩 이동을 의미
💡풀링레이어(Pooling Layer) - CNN 계층 추가 이후에 일반적으로 사용되는 계층 - CNN 계층에서 추출된 특징들 중에 중요한 정보만을 추출하는 계층 - 머신러닝에서 주성분 분석(PCA)과 유사한 개념 - 이미지를 구성하는 픽생들이, 주변 픽셀들끼리는 유사한 정보를 가진다는 개념에서 중복된 값들이나 유사한 값들을 대표하는 값들, 즉 중요한 특징들만 추출하게 됩니다. - 과적합 방지에 효율적으로 사용되며 훈련 성능에 영향을 미치지 않는 전처리 계층임
📍MaxPool2D - 사소한 값들은 무시하고 최대갑의 특징들만 추출하는 방식 - pool_size=2 : 2행 2열의 공간에 중요 특징들만 저장하라는 의미 - strides=2 : CNN에서 추출한 특징값들의 행렬을 오른쪽 2칸씩, 아래로 2칸씩 이동하면서 중요 특징값을 추출하라는 의미(default = 2, 생략가능) - 풀링에서 가장 대표적으로 사용되는 방식임
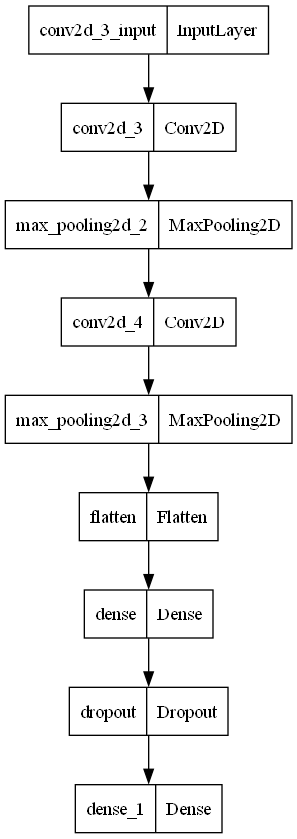
''' (전처리 계층)예측을 위해 중요 특징 데이터를 1차원(높이 x 너비)로 변환하기 '''
model.add(keras.layers.Flatten())
''' 은닉계층 추가
- 활성화함수 추가됨
'''
model.add(keras.layers.Dense(100, activation="relu"))
''' 드롭아웃 적용 '''
model.add(keras.layers.Dropout(0.2))
''' 출력계층 추가 '''
model.add(keras.layers.Dense(10, activation="softmax"))
생성된 모델 확인
훈련계층 이미지로 시각화해보기
from tensorflow.keras.utils import plot_model
plot_model(model)
계층모델 속성 정의하여 시각화 및 저장시키기 - show_shapes : 층의 형태를 세부적으로 표현 (기본값은 False) - dpi : 이미지 해상도 - to_file : 저장위치(기본값은 현재 실행파일이 있는 위치와 동일한 곳에 저장됨)
import tensorflow as tf
''' 단어사전 만들기 '''
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
규칙기반 데이터 정의하기 (질문 / 답변) - "03_RNN응용에_사용할_규칙기반_데이터셋(질문_답변)" txt파일 사용
단어사전 만들기
텍스트 데이터를 토큰화하여 단어 사전을 구축하기
tokenizer = Tokenizer()
tokenizer
단어에 인덱스 부여하기 - 질문과 답변을 하나의 데이터로 합쳐서 전체 텍스트 데이터로 사용 - 이를 기반으로 토크나이저가 단어 사전을 구축하게 됨 - 각 단어들은 순차적인 인덱스 번호를 부여받게 됨 - 토크나이저가 인식하는 문장 내에서 단어의 의미 : 띄어쓰기가 없이 연결되어 있으면 하나의 단어로 인지 - fit_on_texts(텍스트 문장) : 문장 내에서 단어들을 추출하여 순차적 인덱스 부여하기
질문 데이터 단어의 길이 통일 시키기(정규화) - 잘라낼 max 길이 기준 : 문장들 중 최대 max 단어길이 기준으로 - maxlen을 넣지 않으면, 문장들의 길이가 가장 긴 것을 기준으로 한다.(default : 알아서 가장 긴 갯수를 찾아낸다) - padding="post" : 채우기는 뒤쪽
''' <모델 생성하기> '''
model = tf.keras.Sequential()
'''
<계층 추가하기>
- 단어 임베딩(입력계층) : 출력 64
- Simple Rnn 사용 : 출력 128, 활성화함수 : RelU
'''
model.add(tf.keras.layers.Embedding(vocab_size, 64, input_length=questions_padded.shape[1]))
model.add(tf.keras.layers.SimpleRNN(128, activation="relu"))
''' 입력을 복제하는 전처리 계층 : 텍스트에 대한 Encoder와 Decoder를 담당함 '''
model.add(tf.keras.layers.RepeatVector(answers_padded.shape[1]))
model.add(tf.keras.layers.SimpleRNN(128, activation="relu", return_sequences=True))
'''
- 각 타임별로 동일한 가중치를 적용하도록 처리하며,
전체 시퀀스들의 이전/다음 인덱트 처리 값을 가지고 있다고 보면 됨
- 예측에 주로 사용되는 계층
- 최종 출력 계층을 감싸고 있음
'''
model.add(tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(vocab_size,
activation="softmax")))
model.summary()
모델 설정 및 훈련하기
''' 모델 설정하기 '''
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
''' 모델 훈련하기 '''
model.fit(questions_padded, answers_padded, epochs=100,
batch_size=64, verbose=1)
질문 / 답변 테스트
''' 질문/답변 테스트'''
user_input = "너 이름이 뭐니?"
''' 새로운 질문 텍스트를 단어사전의 인덱스번호로 변환하기 '''
input_seq = tokenizer.texts_to_sequences([user_input])
input_seq
''' 단어의 길이를 훈련에서 사용한 길이로 통일시키기 (정규화) '''
padded_seq = pad_sequences(input_seq, padding="post", maxlen=questions_padded.shape[1])
padded_seq
''' 예측하기 : 새로운 질문에 대한 답변 추출하기 '''
pred = model.predict(padded_seq)
len(pred[0][1])
'''' 답변으로 가장 확률이 높은 값 추출하기 '''
pred_index = tf.argmax(pred, axis=-1).numpy()[0]
print(len(pred_index), pred_index)
''' 시퀀스에 해당하는 텍스트 추출하기
- 인덱스에 해당하는 실제 텍스트 추출하기
'''
response = tokenizer.sequences_to_texts([pred_index])[0]
response
답변 함수 만들기
def get_Generate_Response(model, tokenizer, user_input) :
''' 새로운 질문 텍스트를 단어사전의 인덱스번호로 변환하기 '''
input_seq = tokenizer.texts_to_sequences([user_input])
''' 단어의 길이를 훈련에서 사용한 길이로 통일시키기 (정규화) '''
padded_seq = pad_sequences(input_seq, padding="post", maxlen=questions_padded.shape[1])
''' 예측하기 : 새로운 질문에 대한 답변 추출하기 '''
pred = model.predict(padded_seq)
'''' 답변으로 가장 확률이 높은 값 추출하기 '''
pred_index = tf.argmax(pred, axis=-1).numpy()[0]
''' 시퀀스에 해당하는 텍스트 추출하기
- 인덱스에 해당하는 실제 텍스트 추출하기
'''
response = tokenizer.sequences_to_texts([pred_index])[0]
return response
질문 받고 응답하기 : 무한반복 만들기
while True :
''' 새로운 질문 입력 받기 '''
user_input = input("사용자 : ")
''' 반복을 종료시키기 '''
if user_input == "종료" :
print("채팅 종료")
break
''' 함수 호출하여 질문에 대한 답변 받아오기 '''
response = get_Generate_Response(model, tokenizer, user_input)
''' 답변 출력하기 '''
print("챗봇 : ", response)