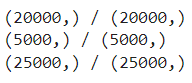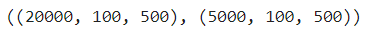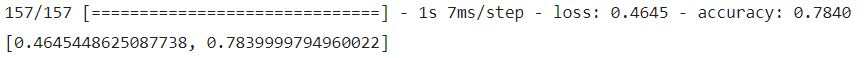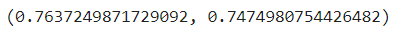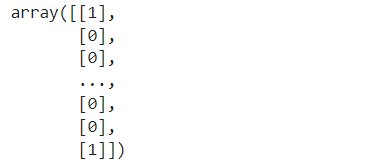728x90
반응형
순환신경망(RNN)
📍 순환신경망(Recurrent Neural Network, RNN)
- RNN은 텍스트 처리를 위해 고안된 모델(계층)
- 바로 이전의 데이터(텍스트)를 재사용하는 신경망 계층임 - 이전에 진행한 훈련기억을 가지고 다시 훈련하는 방식
📍 순환신경망 종류
- 심플 순환신경망(Simple RNN)
- 장기기억 순환신경망(LSTM)
- 게이트웨이 반복 순환신경망(GRU)
📍 Simple RNN 단점
- 긴 문장(시퀀스)을 학습하기 어려움
- 시퀀스가 길 수록 초반의 정보는 점진적으로 희석(소멸)
- 즉, 멀리 떨어져 있는 단어의 정보를 인식하는데 어려움이 있음
- 이러한 단점을 보환한 모델이 LSTM과 GRU
📍 LSTM(Long Shot-Term Memory, 장기기억)
- 단기기억을 오래 기억할 수 있도록 고안된 모델
- 많은 이전 정보를 기억해야 하기 때문에 훈련 속도가 느리며, 시스템 저장 공간이 많이 필요함
📍 GRU(Gated Recurrent Unit, 게이트 반복 단위)
- LSTM의 느린 속도를 개선하기 위해 고안된 모델
- 성능은 LSTM과 유사함
📍 Simle RNN, LSTM, GRU 모두 RMSprop 옵티마이저를 일반적으로 사용
- 사용 라이브러리
import tensorflow as tf from tensorflow import keras ''' 영화 감상평에 대한 긍정/부정 데이터셋 ''' from tensorflow.keras.datasets import imdb from sklearn.model_selection import train_test_split ''' 텍스트 길이 정규화 라이브러리 ''' from tensorflow.keras.preprocessing.sequence import pad_sequences - 사용할 데이터 : IMDB
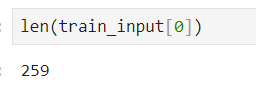
''' 데이터 불러들이기 - IMDB 데이터 사용, 말뭉치 500개 사용 ''' (train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=500) print(train_input.shape, train_target.shape) print(test_input.shape, test_target.shape)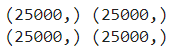
- 훈련 : 검증 데이터로 분류하기 (8 : 2)
''' train : val = 8 : 2로 분류하기 ''' train_input, val_input, train_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42) print(train_input.shape, train_target.shape) print(val_input.shape, val_target.shape) print(test_input.shape, test_target.shape)
- 텍스트 정규화하기
- 훈련, 검증, 테스트 데이터 내의 각 문장의 길이를 100으로 통일(정규화) 시키기
- 왜 100인가? 단어 갯수의 분포를 이용해서 훈련에 사용할 독립변수 각 값들의 길이 기준 정의했을 때, 전체적으로 왼쪽편에 집중되어 있으며, x축 125 정도에 많은 빈도를 나타내고 있음. 따라서, 독립변수 각 값들의 길이를 100으로 통일(정규화)
- 앞쪽을 제거, 채우기
- pad_sequences() : 텍스트의 길이를 maxlen 갯수로 통일시키기
- maxlen보다 작으면 0으로 채우고, 크면 제거한다.
train_seq = pad_sequences(train_input, maxlen=100) val_seq = pad_sequences(val_input, maxlen=100) test_seq = pad_sequences(test_input, maxlen=100) print(train_seq.shape, train_target.shape) print(val_seq.shape, val_target.shape) print(test_seq.shape, test_target.shape)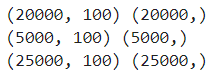
장기기억 순환신경망(LSTM)
- LSTM 모델 생성하기
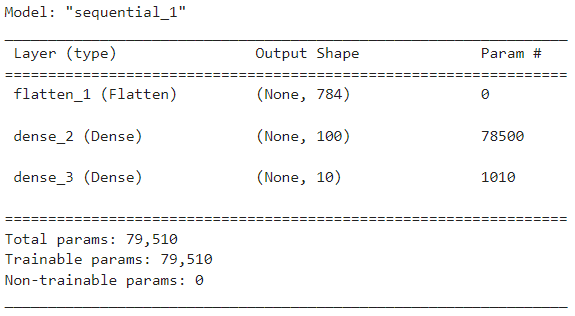
model = keras.Sequential() model - 계층 생성 및 모델에 추가하기
- 임베딩 계층 추가 : 말뭉치 500, 출력크기 16, 입력크기 100
- LSTM 계층 추가 : 출력크기 8
- 출력 계층 추가
model.add(keras.layers.Embedding(500, 16, input_length=100)) model.add(keras.layers.LSTM(8)) model.add(keras.layers.Dense(1, activation="sigmoid")) model.summary()
- 모델 설정하기
- 학습율 : 0.0001
- 옵티마이저 : RMSprop
- RMSprop : 먼 거리는 조금 반영, 가까운 거리는 많이 반영하는 개념을 적용
rmsprop = keras.optimizers.RMSprop(learning_rate=0.0001) model.compile(optimizer=rmsprop, loss="binary_crossentropy", metrics=["accuracy"]) - 콜백함수 정의하기
- 자동 저장 위치 및 파일명 : ./model/best_LSTM_model.h5
- 자동저장 및 자동 종료 콜백함수 정의하기
checkpoint_cb = keras.callbacks.ModelCheckpoint("./model/best_LSTM_model.h5") early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True) checkpoint_cb, early_stopping_cb - 모델 훈련시키기
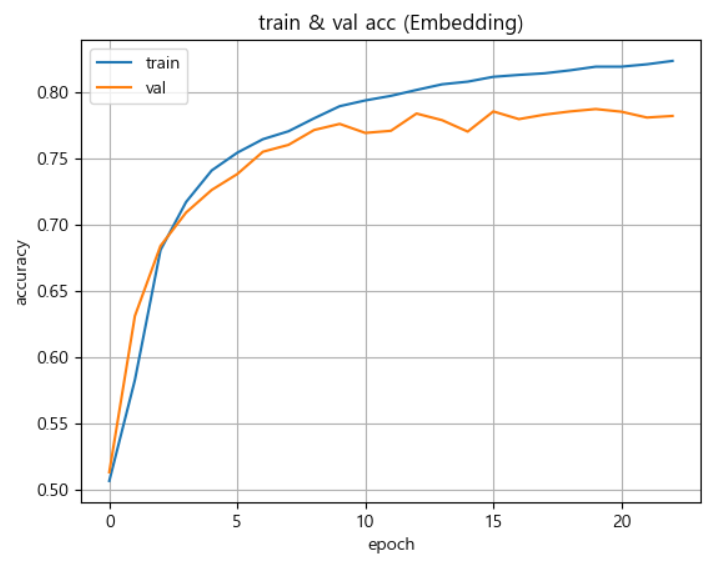
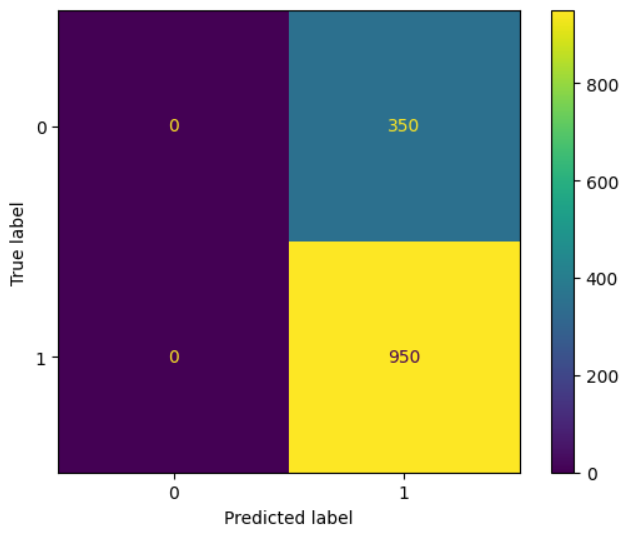
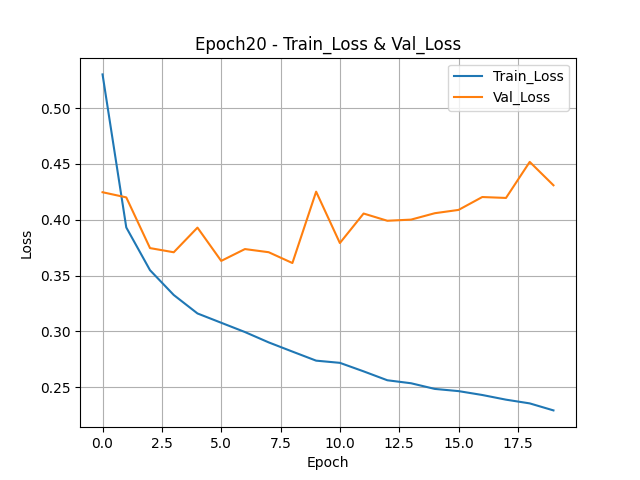
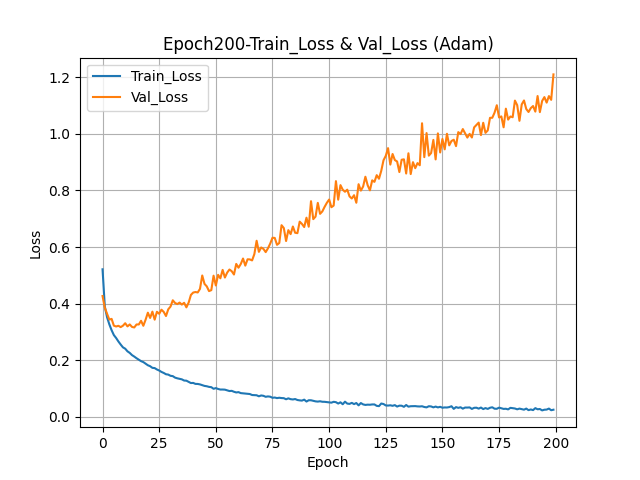
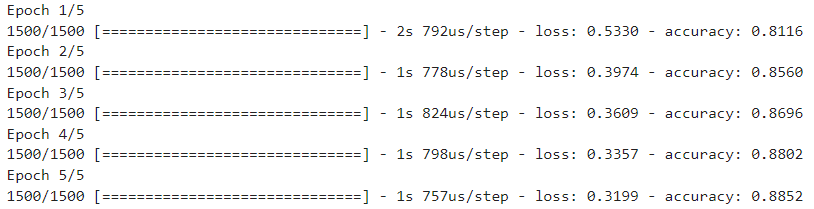
- 100번 반복, 배치사이즈 64, 검증 동시 진행model.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb]) - 훈련, 검증, 테스트 성능검증하기
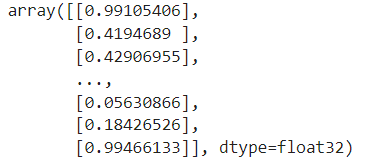
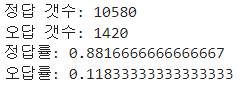
model.evaluate(train_seq, train_target) model.evaluate(val_seq, val_target) model.evaluate(test_seq, test_target)
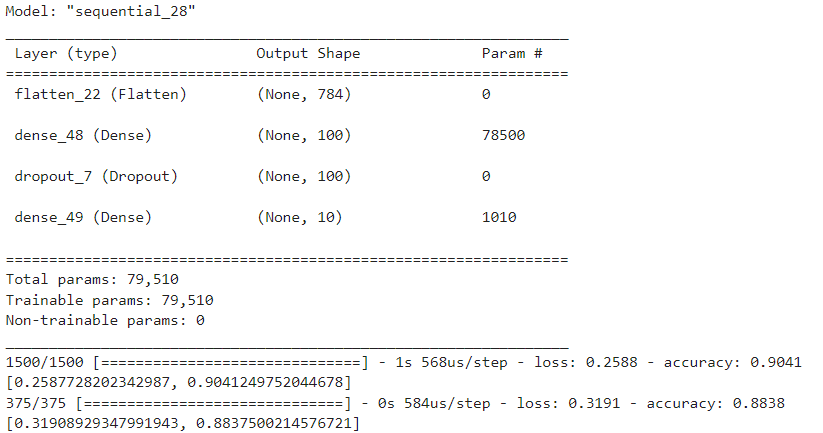
- LSTM 모델의 드롭아웃 속성(계층아님) 적용하기
- LSTM 모델(계층)에 드롭아웃 속성 적용, 30% 훈련에서 제외
- 나머지 모두 위와 동일하게 처리하여 훈련, 검증, 테스트 데이터에 대한 성능검증 진행
''' 모델 생성 ''' model = keras.Sequential() ''' 계층 생성 ''' model.add(keras.layers.Embedding(500, 16, input_length=100)) model.add(keras.layers.LSTM(8, dropout=0.3)) model.add(keras.layers.Dense(1, activation="sigmoid")) ''' 모델 설정 ''' rmsprop = keras.optimizers.RMSprop(learning_rate=0.0001) model.compile(optimizer=rmsprop, loss="binary_crossentropy", metrics=["accuracy"]) ''' 콜백함수 정의 ''' checkpoint_cb = keras.callbacks.ModelCheckpoint("./model/best_LSTM_model.h5") early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True) ''' 모델 훈련 ''' model.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb]) - 드롭아웃 속성 적용 시 훈련, 검증, 테스트 성능검증하기
model.evaluate(train_seq, train_target) model.evaluate(val_seq, val_target) model.evaluate(test_seq, test_target)
- LSTM 2개 연결하기
- LSTM 2개를 연결할 때는 연속해서 LSTM 계층을 추가해야함
- 첫번째 LSTM 계층의 속성에는 return_sequences=True 속성을 추가해 준다.
- 두번째 LSTM은 첫번째 LSTM의 훈련결과를 이어받아서 계속 훈련을 이어나간다.
''' 모델 생성 ''' model = keras.Sequential() ''' 계층 생성 ''' model.add(keras.layers.Embedding(500, 16, input_length=100)) model.add(keras.layers.LSTM(8, dropout=0.3, return_sequences=True)) model.add(keras.layers.LSTM(8, dropout=0.2)) model.add(keras.layers.Dense(1, activation="sigmoid")) ''' 모델 설정 ''' rmsprop = keras.optimizers.RMSprop(learning_rate=0.0001) model.compile(optimizer=rmsprop, loss="binary_crossentropy", metrics=["accuracy"]) ''' 콜백함수 정의 ''' checkpoint_cb = keras.callbacks.ModelCheckpoint("./model/best_LSTM_model.h5") early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True) ''' 모델 훈련 ''' model.fit(train_seq, train_target, epochs=100, batch_size=64, validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb]) - LSTM 2개 연결 시 훈련, 검증, 테스트 성능검증하기

게이트웨이 반복 순환신경망(GRU)
- GRU 모델
''' 모델 생성 '''
model = keras.Sequential()
''' 계층 생성 '''
model.add(keras.layers.Embedding(500, 16, input_length=100))
model.add(keras.layers.GRU(8))
model.add(keras.layers.Dense(1, activation="sigmoid"))
''' 모델 설정 '''
rmsprop = keras.optimizers.RMSprop(learning_rate=0.0001)
model.compile(optimizer=rmsprop,
loss="binary_crossentropy",
metrics=["accuracy"])
''' 콜백함수 정의 '''
checkpoint_cb = keras.callbacks.ModelCheckpoint("./model/best_LSTM_model.h5")
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
''' 모델 훈련 '''
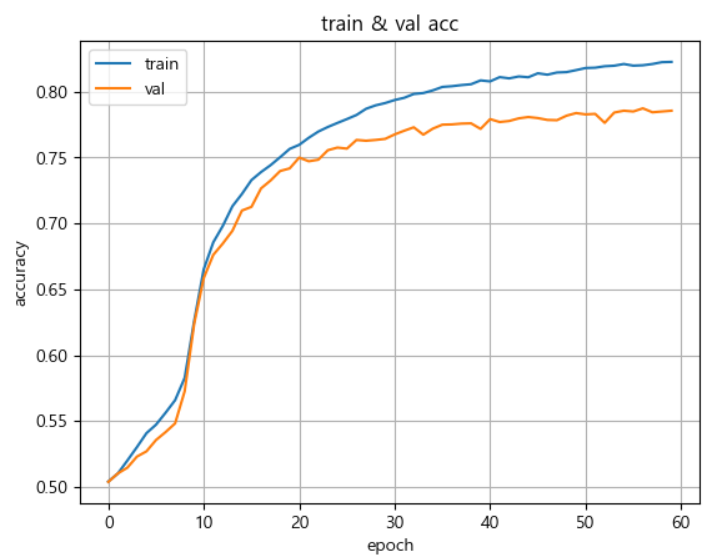
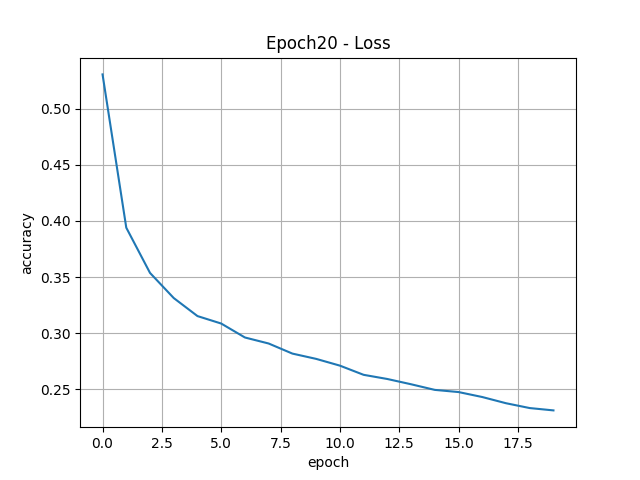
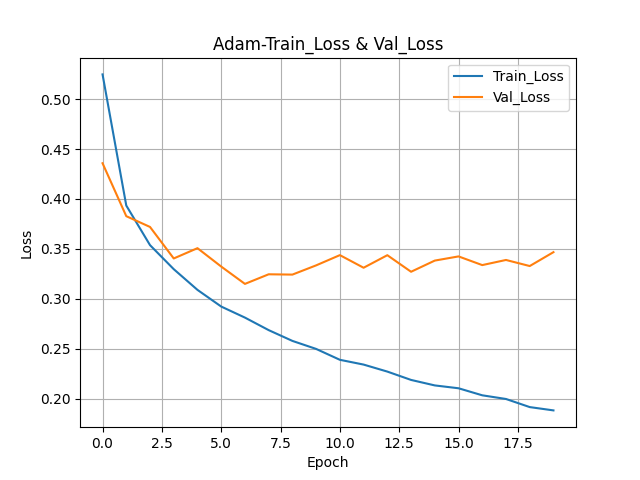
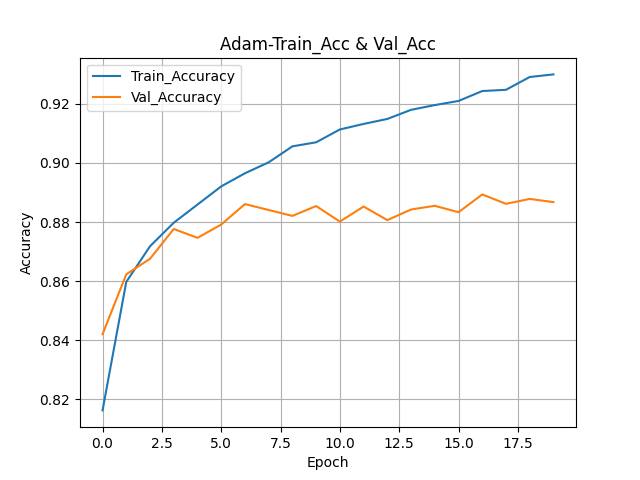
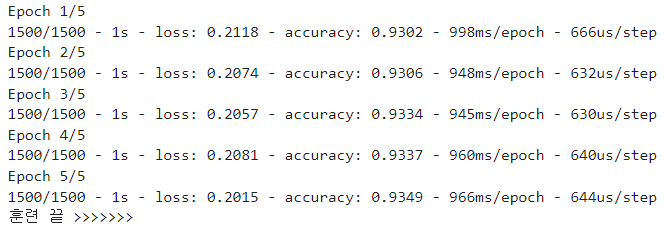
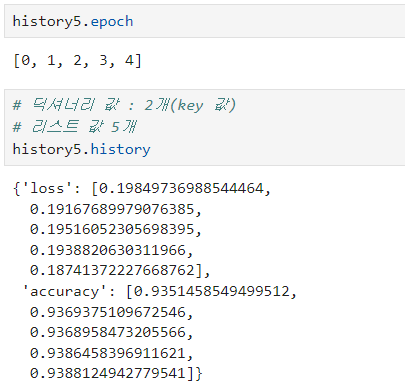
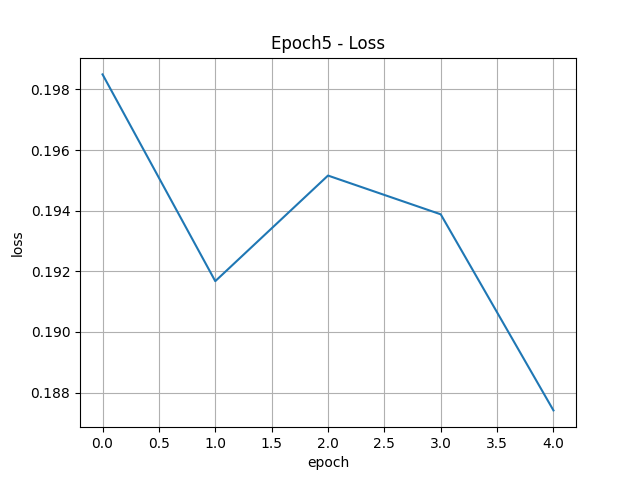
history = model.fit(train_seq, train_target,
epochs=100,
batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
- 훈련, 검증, 테스트 성능검증하기
model.evaluate(train_seq, train_target)
model.evaluate(val_seq, val_target)
model.evaluate(test_seq, test_target)
728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][DL] Deep Learning - 합성곱신경망(CNN) (1) | 2024.01.08 |
|---|---|
| [인공지능][DL] Deep Learning - RNN 응용 / 규칙기반 챗봇 (2) | 2024.01.08 |
| [인공지능][DL] Deep Learning - 심플 순환신경망(Simple RNN) (1) | 2024.01.05 |
| [인공지능][DL] Deep Learning - 퍼셉트론(Perceptron) 모델 (0) | 2024.01.05 |
| [인공지능][DL] Deep Learning 실습 - DNN 분류데이터 사용 (1) | 2024.01.05 |