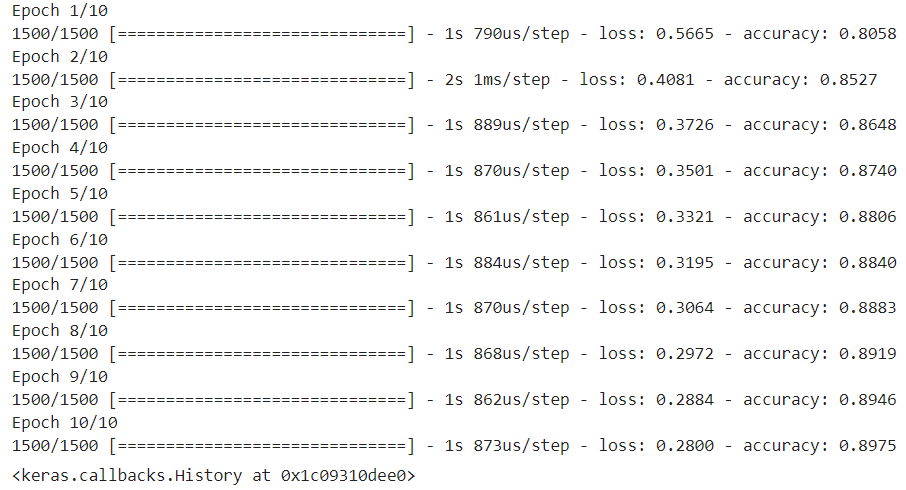
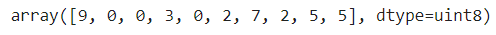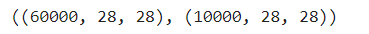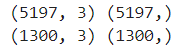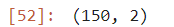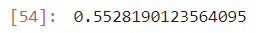1. 신경망 모델 생성 2. 계층 추가하기 - 1차원 전처리 계층 추가 - 은닉계층 추가, 활성화함수 relu 사용, 출력크기 100개 - 최종 출력계층 추가 3. 모델설정하기 - 옵티마이저는 adam 사용, 학습률 0.1 사용 4. 훈련시키기 - 훈련횟수 : 50 5. 성능 평가하기
''' 1. 신경망 모델 생성 '''
model = keras.Sequential()
''' 2. 계층 추가하기
- 1차원 전처리 계층 추가
- 은닉계층 추가, 활성화함수 relu 사용, 출력크기 100개
- 최종 출력계층 추가
'''
model.add(
keras.layers.Flatten(input_shape=(28, 28))
)
model.add(
keras.layers.Dense(100, activation="relu")
)
model.add(
keras.layers.Dense(10, activation="softmax")
)
''' 3. 모델설정하기
- 옵티마이저는 adam 사용, 학습률 0.1 사용
'''
adam = keras.optimizers.Adam(
learning_rate=0.1
)
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics="accuracy"
)
<실습> - 옵티마이저에 적용할 학습기법(sgd, adagrad, rmsprop, adam) 중에 가장 좋은 성능을 나타내는 옵티마이저 학습기법 확인하기 - 훈련횟수 : 50회 - 학습률은 기본값 사용 - 은닉계층 relu 사용 - 성능 평가결과를 이용해서 손실율이 가장 낮을 때의 학습방법, 정확도가 가장 높을 때의 학습방법을 각각 출력하기
작성한 코드
''' 1. 신경망 모델 생성 '''
model = keras.Sequential()
''' 2. 계층 추가하기 '''
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
opt = ["sgd", "adagrad", "rmsprop", "adam"]
best_loss_optimizer = None
best_accuracy_optimizer = None
best_loss = float('inf') # 초기값을 무한대로 설정
best_accuracy = 0.0
for i in opt:
if i == "sgd":
optimizer = keras.optimizers.SGD()
elif i == "adagrad":
optimizer = keras.optimizers.Adagrad()
elif i == "rmsprop":
optimizer = keras.optimizers.RMSprop()
else:
optimizer = keras.optimizers.Adam()
print(f"-------------------옵티마이저 {i} 시작-------------------")
model.compile(
optimizer=optimizer,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
model.fit(train_scaled, train_target, epochs=50)
loss, accuracy = model.evaluate(val_scaled, val_target)
print(f"손실율 : {loss} / 정확도 : {accuracy}")
print(f"-------------------옵티마이저 {i} 종료-------------------")
# 가장 좋은 성능인지 확인
if loss < best_loss:
best_loss = loss
best_loss_optimizer = i
if accuracy > best_accuracy:
best_accuracy = accuracy
best_accuracy_optimizer = i
print("손실율이 가장 낮을 때의 학습방법:", best_loss_optimizer)
print("정확도가 가장 높을 때의 학습방법:", best_accuracy_optimizer)
강사님 코드
### 옵티마이저 학습방법 및 반복횟수를 받아서 처리할 함수 정의
def getBestEval(opt, epoch) :
''' 모델 생성 '''
model = keras.Sequential()
''' 레이어계층 생성 및 모델에 추가하기 '''
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
''' 모델 설정하기 '''
model.compile(optimizer = opt,
loss="sparse_categorical_crossentropy",
metrics="accuracy")
''' 모델 훈련시키기 '''
model.fit(train_scaled, train_target, epochs=epoch)
''' 성능평가 '''
score = model.evaluate(val_scaled, val_target)
''' 성능결과 반환하기 '''
return score
''' 함수 호출하기 '''
''' 옵티마이저를 리스트로 정의하기 '''
optimizers = ["sgd", "adagrad", "rmsprop", "adam"]
''' 최고 정확도를 담을 변수 정의 '''
best_acc = 0.0
''' 최고 정확도일 때의 학습방법을 담을 변수 정의 '''
best_acc_opt = ""
''' 최저 손실율를 담을 변수 정의 '''
best_loss = 1.0
''' 최저 손실율일 때의 학습방법을 담을 변수 정의 '''
best_loss_opt = ""
''' 옵티마이저의 학습방법을 반복하여 성능 확인하기 '''
for opt in optimizers :
print(f"--------------------------{opt}--------------------------")
''' 함수 호출 '''
epoch=10
rs_score = getBestEval(opt, epoch)
''' 가장 높은 정확도와 이 때 학습방법 저장하기 '''
if best_acc < rs_score[1] :
best_acc = rs_score[1]
best_acc_opt = opt
''' 가장 낮은 손실율과 이때 학습방법 저장하기 '''
if best_loss < rs_score[0] :
best_loss = rs_score[0]
best_loss_opt = opt
print()
print('전체 실행 종료 >>>>>>>>>>>>>>>')
print(f"best_acc_opt : {best_acc_opt} / best_acc : {best_acc}")
print(f"best_loss_opt : {best_loss_opt} / best_loss : {best_loss}")
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
데이터 수집 및 정규화
📍 fashion_mnist 데이터를 이용해서 훈련 및 테스트에 대한 독립변수와 종속변수 읽어 들이기 → 변수는 항상 사용하는 변수명으로 설정 📍 정규화하기 📍 훈련의 독립 및 종속변수를 이용해서 훈련 : 검증 = 8 : 2로 분류하기
'''
255로 나누는 이유는 이미지 데이터가 보통 0에서 255 사이의 픽셀 값으로 구성되어 있기 때문이다.
각 픽셀의 값이 0일 때는 최소값, 255일 때는 최대값이므로,
이 값을 0에서 1 사이의 범위로 매핑하기 위해 255로 나누어준다.
이렇게 하면 모든 픽셀 값이 0에서 1 사이의 실수 값으로 정규화된다.
'''
train_scaled_255 = train_input / 255.0
train_scaled_255[0]
test_scaled_255 = test_input / 255.0
test_scaled_255[0]
train_scaled_255.shape, test_scaled_255.shape
''' 입력계층(Input layer) 생성하기 '''
dense1 = keras.layers.Dense(100, activation="sigmoid", input_shape=(784,))
''' 출력계층(Output layer) 생성하기 '''
dense2 = keras.layers.Dense(10, activation="softmax")
''' 신경망 모델 생성하기 '''
### 여러개를 넣어야 할 때 리스트[] 사용
model = keras.Sequential([dense1, dense2])
model
''' 입력계층(Input layer) 생성하기 '''
dense1 = keras.layers.Dense(100, activation="sigmoid", input_shape=(784,))
''' 출력계층(Output layer) 생성하기 '''
dense2 = keras.layers.Dense(10, activation="softmax")
''' 신경망 모델 생성하기 '''
### 여러개를 넣어야 할 때 리스트[] 사용
model = keras.Sequential([dense1, dense2])
model
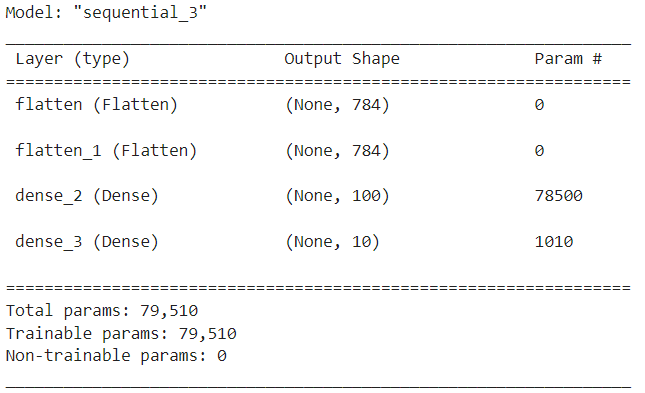
''' 모델 계층 확인하기 '''
model.summary()
- Output Shape로 100개를 출력해냄 - 다음 계층(dense_1)이 100개를 입력 계층으로 받음 - 그리고 다시 시그모이드 함수를 이용해 10개로 출력해냄 - dense_1에서 훈련에 관여하고 있는 계층 78500개 - param이 0 이면 훈련에 영향을 미치고 있는 계층이 없다.
2. 신경망모델 생성 시 계층(layer)을 함께 추가
''' 모델 생성 및 계층 추가하기 '''
model = keras.Sequential([
keras.layers.Dense(100, activation="sigmoid",
input_shape=(784,), name = "Input-layer"),
keras.layers.Dense(10, activation="softmax", name = "Output-layer")],
name = "Model-2"
)
model.summary()
3. 신경망 모델을 먼저 생성 후, 계층 추가하기
''' 신경망 모델 생성하기
- 일반적으로 사용되는 방식
- 위의 1, 2 방법으로 수행 후, 계층을 추가할 필요성이 있을 경우에도 사용됨'''
model = keras.Sequential()
''' 계층 생성 및 모델에 추가하기 '''
model.add(
keras.layers.Dense(100, activation="sigmoid", input_shape(784,), name="Input-Layer")
)
model.add(
keras.layers.Dense(10, activation="softmax", name="Output-Layer")
)
model.summary()
모델 설정하기(compile)
''' 손실함수는 다중분류 사용 '''
model.compile(
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
옵티마이저(Optimizer) →옵티마이저 설정 위치 : compile() 시에 설정함 →손실을 줄여나가기 위한 방법을 설정함 →손실을 줄여나가는 방법을 보통 "경사하강법"이라고 칭한다. →"경사하강법"을 이용한 여러 가지 방법들 중 하나를 선택하는 것이 옵티마이저 선택이다. →옵티마이저 종류 : SGD(확률적 경사하강법), Adagrad, RMSProp, Adam이 있음
📍 SDG(확률적 경사하강법) - 현재 위치에서 기울어진 방향을 찾을 때 지그재그 모양으로 탐색해 나가는 방법 📍 Adagrad - 학습률(보폭)을 적절하게 설정하기 위해 학습율 감소라는 기술을 사용 - 학습 진행 중에 학습률을 줄여가는 방법을 사용 - 처음에는 학습율을 크게 학습하다가, 점점 작게 학습한다는 의미 - 기울기가 유연함
📍 RMSProp - Adagrad의 단점을 보완한 방법 - Adagrad는 학습량을 점점 작게 학습하기 때문에 학습량이 0이 되어 갱신(학습)되지 않는 시점이 발생할 수 있는 단점이 있음 - 이러한 단점을 보완하여 과거의 기울기 값을 반영하는 방식 사용 - 먼 과거의 기울기(경사) 값은 조금 반영하고, 최근 기울기(경사)를 많이 반영 - Optimizer의 기본값(default)으로 사용됨
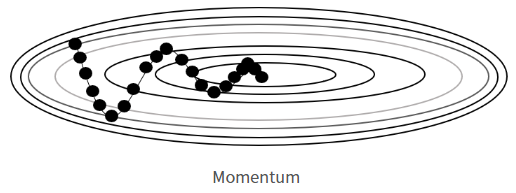
📍 Adam - 공이 굴러가듯이 모멘텀(momentum→관성)과 Adagrad를 융합한 방법 ** 모멘텀 : 관성과 가속도를 적용하여 이동하던 방향으로 좀 더 유연하게 작동함 - 자주 사용되는 기법으로, 좋은 결과를 얻을 수 있는 방법으로 유명함 - 메모리 사용이 많은 단점이 있음(과거 데이터를 저장해 놓음)
어떤 걸 써야 하는지 정해져 있지 않음 가장 좋은 건 모멘텀을 적용한 adam sgd는 가장 초기에 나왔기 때문에 많이 사용하기 않음. 기본값인RMSProp을 사용하고 adam사용. 하이퍼파라미터 튜닝을 한다면 모두 다 사용해 보는 것을 추천
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="sgd",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
학습률을 적용하는 방법 - 사용되는 4개의 옵티마이저를 객체로 생성하여 learning_rate(학습률) 값을 설정할 수 있음 - 학습률 : 보폭이라고 생각하면 됨 - 학습률이 작을수록 보폭이 작다고 보면 됨 - 가장 손실이 적은 위치를 찾아서 움직이게 됨 - 이때 가장 손실이 적은 위치는 모델이 스스로 찾아서 움직이게 됨(사람이 관여하지 않음) - 학습률의 기본값은 = 0.01을 사용(사용값의 범위 0.1 ~ 0.0001 정도)
과적합을 해소하기 위한 튜닝방법으로 사용됨 - 과대적합이 일어난 경우 : 학습률을 크게 - 과소적합이 일어난 경우 : 학습률을 작게 - 과대/과소를 떠나서, 직접 값의 법위를 적용하여 튜닝을 수행한 후 가장 일반화 시점의 학습률 값을 찾는 것이 중요함
옵티마이저 객체 생성 및 모델 설정
''' 옵티마이저 객체 생성 '''
sgd = keras.optimizers.SGD(learning_rate=0.1)
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="sgd",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
모멘텀(Momentum) - 기존의 방향(기울기)을 적용하여 관성을 적용시키는 방법 - 기본적으로 0.9 이상의 값을 적용시킴 - 보통 nesterov=True 속성과 함께 사용됨 →nesterov=True : 모멘텀 방향보다 조금 더 앞서서 경사를 계산하는 방식(미리 체크) - momentum 속성을 사용할 수 있는 옵티마이저 : SGD, RMSProp
''' 옵티마이저 객체 생성 '''
sgd = keras.optimizers.SGD(
momentum=0.9,
nesterov=True,
learning_rate=0.1
)
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="sgd",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' adagrad '''
adagrad = keras.optimizers.Adagrad()
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer=adagrad,
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' 또는 '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adagrad",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
RMSprod
''' RMSProd '''
rmsprop = keras.optimizers.RMSprop()
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer=rmsprop,
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' 또는 '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="rmsprop",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
Adam
''' Adam '''
adam = keras.optimizers.Adam()
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer=adam,
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' 또는 '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adam",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
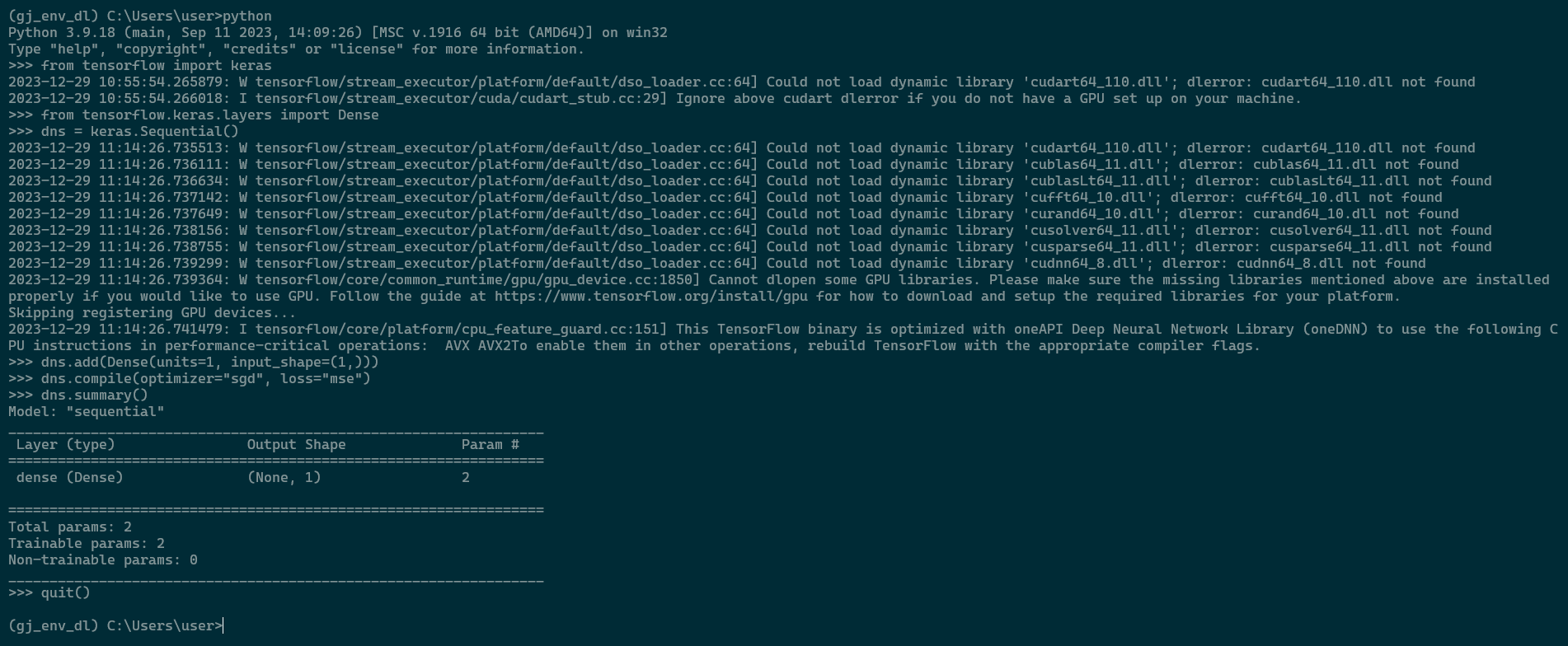
1. conda 업데이트 > conda update -n base conda 2. pip 업데이트 > python -m pip install --upgrade pip 3. 가상환경 생성하기 > conda create -n gj_env_ python=3.9 4. 가상환경으로 들어가기(활성화시키기) > conda activate gj_env_dl 5. 외부 에디터에서 가상환경 연결(kernel) 하기 위하여 jupyter 설치하기 > pip install jupyter notebook 6. 커널 생성하기 (base root 가상환경에서 진행) > python -m ipykernel install --user --name gj_env_dl --display-name gj_env_dl_kernel 7. 커널 생성 목록 확인하기 > jupyter kernelspec list 8. 기본 패키지 설치하기( gj_env_dl에서 진행) > pip install ipython jupyter matplotlib pandas xlrd seaborn scikit-learn > pip install openpyxl > pip install folium (지도 시각화) > pip install plotly (시각화) > pip install xgboost (머신러닝 앙상블 분류모델) > pip install nltk (자연어처리) > pip install wordcloud > pip install JPype1 > pip install konlpy (/anaconda3/envs/gj_env_dl/Lib/site-packages/konlpy/jvm.py에서 별(*) 표시 삭제) 9. 딥러닝 - 텐서플로우 설치하기( 텐서플로우 설치 후 numpy 설치하면 충돌 난다. 텐서플로우의 numpy가 따로 있다.) > pip install tensorflow==2.8.2 10. 딥러닝 - 모델 시각화 라이브러리 > conda install -c conda-forge pydot graphviz
Tensorflow 정상적으로 설치되었는지 확인
> python >>> from tensorflow import keras >>> from tensorflow.keras.layers import Dense >>> dns = keras.Sequential() >>> dns.add(Dense(units=1, input_shape(1,))) >>> dns.compile(optimizer="sgd", loss="mse") >>> dns.summary()
인공신경망 훈련 모델 맛보기
🏓라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
🏓랜덤 고정값 설정
''' 실행 결과를 동일하게 하기 위한 처리(완전 동일하지 않을 수도 있음) '''
tf.keras.utils.set_random_seed(42)
''' 연산 고정 '''
tf.config.experimental.enable_op_determinism()
데이터 수집
'''
- keras에서 제공해주는 이미지 데이터셋 사용
- MNIST 패션 이미지
- 이미지 데이터는 픽셀 데이터로 이루어져 있다.
'''
# 튜플(독립변수 종속변수) 안에 튜플(훈련데이터, 테스트데이터) 안에 array
(train_input, train_target), (test_train, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_train.shape, test_target.shape)
''' 이미지 1개에 대한 데이터 추출
- 각 데이터는 픽셀값(색상값)
- 픽셀값(색상값)은 0 ~ 255 (총 256개의 값드로 구성되어 있음)
'''
train_input[0]
훈련데이터 10개만 이용해서 데이터를 이미지로 시각화하기
''' 서브플롯 사용 : 이미지 10개를 하나로 시각화 '''
fig, axs = plt.subplots(1, 10, figsize=(10, 10))
''' 훈련데이터 10개에 대한 처리 '''
for i in range(10) :
''' 픽셀데이터를 이미지로 시각화 : imshow() '''
axs[i].imshow(train_input[i], cmap="gray_r")
''' x, y 좌표계 숨기기 '''
axs[i].axis("off")
plt.show()
''' 종속변수 10개 추출해서 매핑된 값 확인해보기 '''
train_target[:10]
딥러닝에서 사용되는 숫자들의 범위 → 일반적으로 딥러닝에서는 숫자의 범위를 16 ~ 512 또는 32 ~ 512로 사용한다. → 높이와 너비를 나타내는 숫자가 있는 경우에는 3x3 또는 5x5를 주로 사용한다.
모델에는 여러개의 계층(layer)이 사용될 수 있다.
첫번째 계층 → 입력 계층(Input layer)이라고 칭한다. → 입력 계층에는 input_shape()가 정의된다. → input_shape()에는 독립변수의 열갯수를 정의한다 → 모델에서 한개의 계층만 사용되는 경우에는 입력 계층이 곧, 출력 계층의 역할까지 수행한다. >> 이 경우에는 출력 크기는 종속변수의 범주 갯수를 정의한다.
중간 계층 → 은닉 계층(Hidden layer)이라고 칭한다. → 은닉 계층은 여러개 사용된다. → 은닉 계층의 출력 크기(갯수)는 일정하지 않다. → 출력 크기(갯수)는 사람이 정한다. → 출력 크기(갯수)는 다음 은닉계층이 입력 크기(갯수)로 받아서 훈련을 이어가는 방식이다.
마지막 계층 → 출력 계층(Output layer)이라고 칭한다. → 출력 계층에 사용되는 출력 크기는 종속변수의 범주 갯수를 정의한다.
units : 특정 계층에서의 출력의 크기(갯수), 결과갯수 → 딥러닝 모델에는 계층이 여러개 사용될 수 있으며, 마지막 계층에는 units의 갯수는 종속변수 범주의 갯수를 사용한다. → 중간에 사용되는 계층을 은닉계층(hidden layer)이라고 칭하며, 중간에 사용되는 계층 간에는 출력 크기를 넘겨받아서 사용된다. → 중간 계층의 출력 크기에 따라서 성능에 영향을 미칠 수도 있기 때문에 하이퍼파라미터 튜닝을 진행하는 경우도 있다. → 하이퍼파라미터 튜닝은 값을 바꾸면서 여러번 시도하는 방식을 따른다.
kernel_initializer : 가중치를 초기화하는 방법을 지정 → 가중치 : 손실을 최소화하기 위해서 모델이 훈련을 반복하는 과정에서 스스로 조정하는 값을 의미함 → 가중치 초기화 방법 : uniform, normal 방법이 있음 * uniform : 균일 분포 방법 * normal : 가우시안 분포(정규 분포) 방법
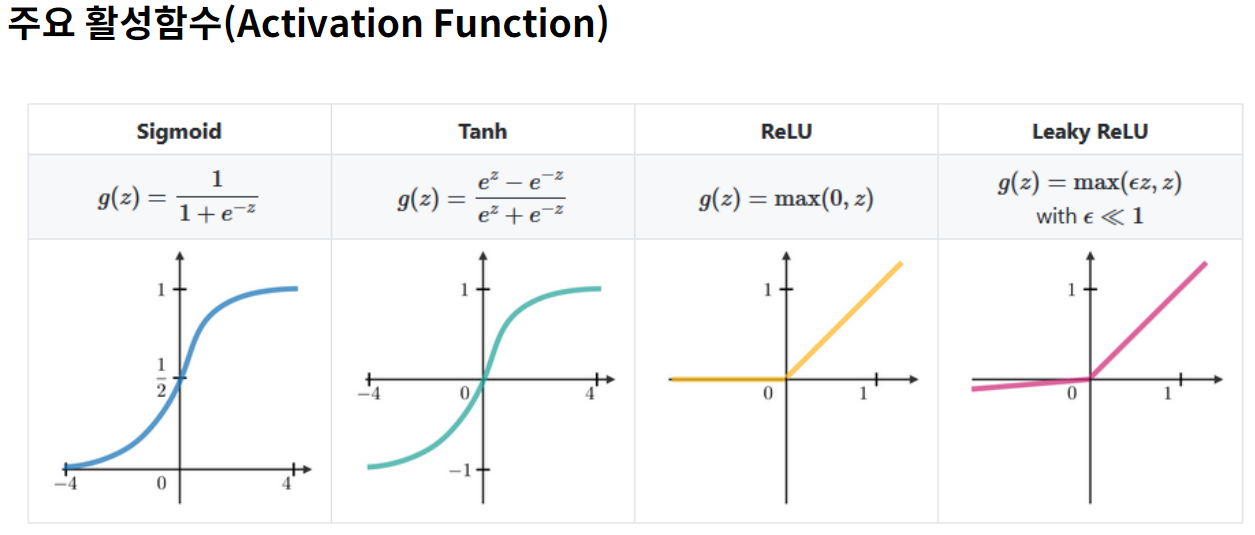
activation : 활성화 함수라고 칭한다. → 훈련 시 입력된 특성(뉴런)의 크기를 어떤 형태의 크기로 변환할지를 결정하는 방법 정의 → 출력계층(Output Layer)에는 해당 종속변수의 특성에 따라 결정됨 >> 선형형태인 회귀분석의 경우 linear 사용 >> 범주형태의 분류분석인 경우 Sigmoid, Softmax, ReLU, Tanh, Leaky ReLU 등 사용 > 이진분류 : Sigmoid, ReLU, Tanh, Leaky ReLU > 다중분류 : Softmax → 입력계층 또는 은닉계층에는 Sigmoid, Softmax, ReLU, Tanh, Leaky ReLU 등이 사용됨
loss → 손실을 줄이기 위해 사용되는 함수 정의 → 손실함수에는 categorical_crossentropy, binary_crossentropy, sparse_categorical_crossentropy 가 있음
categorical_crossentropy : 다중분류 손실함수 → 종속변수의 데이터 값이 원-핫인코딩된 형태로 되어있는 경우 사용 → 예시 데이터 : [[0, 1, 0], [0, 0, 1], [0, 1, 0], ...]
sparse_categorical_crossentropy : 다중분류 손실함수 → 종속변수의 데이터 값이 숫자값으로 3개 이상으로 되어있는 경우 사용 → 예시 데이터 : [0, 1, 2, 3, 4, ... ]
binary_crossentropy : 이진분류 손실함수 → 종속변수의 데이터 값이 숫자값으로 2개 정의되어 있는 경우 → 예시 데이터 : [0, 1, 1, 0, 0, 1, ... ]
model.compile(
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
💡categorical_crossentropy와 관련한 원-핫 인코딩 예제
import numpy as np
from tensorflow.keras.utils import to_categorical
### 임의 데이터 생성
# - randint() : 랜덤하게 정수값을 생성하는 함수
# --> 첫번째 인자 : 범주의 범위(0~2까지로 3개의 범주를 의미함)
# --> 두번째 인자 : 몇 개의 랜덤한 범주값을 만들지에 대한 값(10개 생성)
labels = np.random.randint(3, size=(10,))
labels
### 원-핫 인코딩(One-Hot Encoding) 하기
# - to_categorical() : 각각의 값을 범주의 갯수만큼의 리스트로 데이터 생성
# : 리스트 내 데이터에서 1이 있는 곳의 인덱스 위치값은 실제 labels의 값과 동일
# - num_classes : unique한 범주의 갯수 정의
one_hot_labels = to_categorical(labels, num_classes=3)
labels, one_hot_labels.shape, one_hot_labels
🏓 4. 모델 훈련시키기
''' epochs : 훈련 반복 횟수(손실함수의 손실률을 계속 줄여나가면서 반복함) '''
# model.fit(train_scaled, train_target, epochs=100)
# 정확도가 거의 유사하다면 손실률이 작은 것을 선택한다.
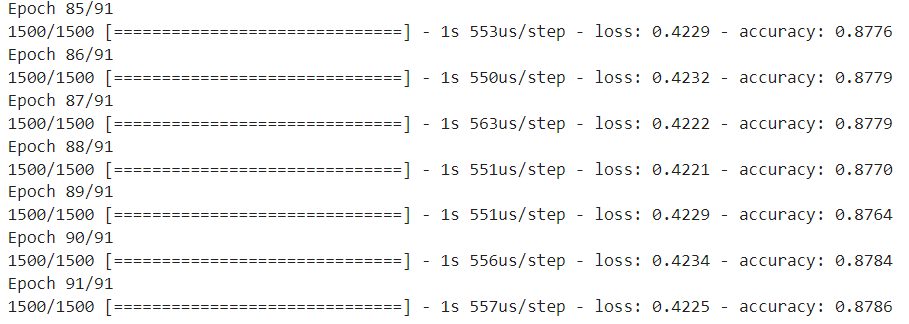
# 91번 loss: 0.4116 - accuracy: 0.8772 와 98번 loss: 0.4140 - accuracy: 0.8774를 비교했을 때 91번 선택
model.fit(train_scaled, train_target, epochs=91)
import joblib
'''
훈련모델 저장하기
- 파일 확장자는 자유롭게
'''
joblib.dump(rf, "./model/rf_model_joblib.md")
''' 모델 파일 불러들이기 '''
joblib_model = joblib.load("./model/rf_model_joblib.md")
joblib_model
joblib_model.predict(test_input)
pickle 방식
import pickle
'''
훈련모델 저장하기
- wb : w는 쓰기, b는 바이너리 => 바이너리 형태로 쓰기
'''
with open("./model/rf_model_pickle.md", "wb") as fw :
pickle.dump(rf, fw)
'''
모델 파일 불러오기
- rb : r는 읽기, b는 바이너리 => 바이너리 형태의 파일 내용 읽기
'''
with open ("./model/rf_model_pickle.md", "rb") as f :
load_pickle_model = pickle.load(f)
load_pickle_model
군집할 갯수는 종속변수의 범주의 갯수와 동일함(이미 종속변수를 알고 있는 경우도 있고, 아닌 경우도 있음)
군집의 갯수를 이미 알고 있는 경우에는 직접 갯수 정의, 모르는 경우에는 하이퍼파라미터 튜닝을 통해 적절한 갯수 선정
🖍️작동방식
데이터들을 이용해서 무작위로 K개의 클러스터 중심을 정함
각 샘플에서 가장 가까운 클러스터 중심을 찾아서 해당 클러스터의 샘플로 지정
특정 클러스터에 속한 "샘플들의 평균값"으로 클러스터 중심을 변경
클러스터 중심에 변화가 없을 때까지 2번 ~ 3번을 반복 수행하게 되는 모델임
사용할 라이브러리
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix
''' KMeans 군집 모델 '''
from sklearn.cluster import KMeans
사용할 데이터 셋 - 와인데이터
'''
- 데이터 불러오기 : 변수명 data
- 독립변수와 종속변수로 나누기 : 변수명은 X, y
'''
data = pd.read_csv("./data/08_wine.csv")
X = data.iloc[:,:-1]
y = data["class"]
X.shape, y.shape
from sklearn.cluster import KMeans
'''
군집분석 평가 방법 : 실루엣 score로 평가함
- 값의 범위 : -1 ~ 1 사이의 값
- -1에 가까울 경우 : 군집 분류가 잘 안된 경우
- 0에 가까울 경우 : 이도 저도 아닌 상태()
- 1에 가까울 경우 : 군집이 잘 된 경우
'''
from sklearn.metrics import silhouette_score
''' Iris(붓꽃) 데이터셋 라이브러리 '''
from sklearn.datasets import load_iris
import seaborn as sns
Iris 데이터 읽어들이기
iris = load_iris()
iris
특성 설명
- sepal length : 꽃받침 길이 - sepal width : 꽃받침 너비 - petal length : 꽃잎 길이 - petal width : 꽃잎 너비
분석 주제 - 4가지 독립변수 특성을 이용하여 붓꽃의 품종 종류별로 군집(클러스터) 분류하기
독립변수와 종속변수 데이터 추출하기
'''
독립변수명 : X
종속변수명 : y
'''
X = iris.data
y = iris.target
X.shape, y.shape
군집 모델 생성 / 훈련 및 예측
'''
- 군집분류에서는 별도로 훈련과 검증데이터로 분류하기 않고, 전체 데이터를 사용하여 군집합니다.
'''
'''
* 군집모델 생성하기
- 군집 갯수 지정
- n_init : 초기 중심점 설정 횟수는 10으로 설정
- 랜덤 규칙 : 42번
'''
kmeans_model = KMeans(n_clusters=3, n_init=10, random_state=42)
kmeans_model
'''
- 모델 훈련 및 군집하기(예측)
- 군집분석에서는 훈련과 동시에 예측이 수행 됨
'''
kmeans_labels = kmeans_model.fit_predict(X)
print(kmeans_labels)
print(y)
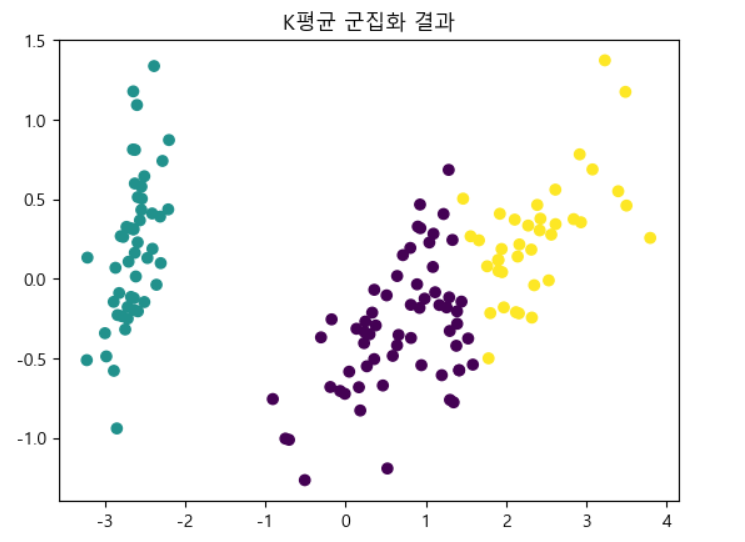
군집결과 시각화하기
주성분분석(PCA)을 통해 시각화하기
주성분분석(PCA) → 훈련에 사용된 특성들 중에 특징을 가장 잘 나타낼 수 있는 특성을 추출하는 방식 → 특성을 추출하여 특성을 축소시키는 방식으로 "차원축소"라고 칭한다. → 주요 성분의 특성만을 사용하기 때문에 빠른 성능을 나타냄
''' 데이터 처리 '''
import pandas as pd
''' 데이터 분류 '''
from sklearn.model_selection import train_test_split
''' 하이퍼파라미터 튜닝 '''
from sklearn.model_selection import GridSearchCV
''' 사용할 분류모델들 '''
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import HistGradientBoostingClassifier
from xgboost import XGBClassifier
''' 데이터 스케일링 : 정규화 '''
from sklearn.preprocessing import StandardScaler
''' 평가 '''
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
''' 오차행렬(혼동행렬) '''
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
데이터 셋
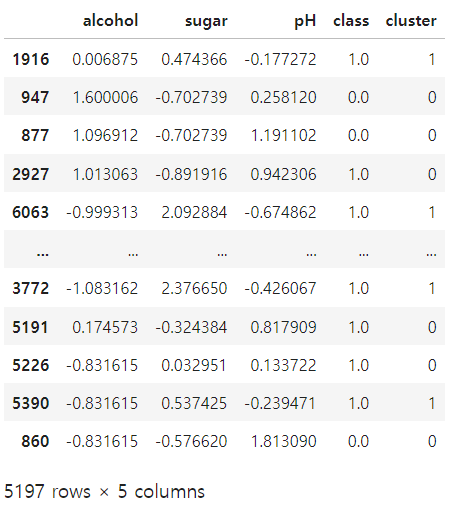
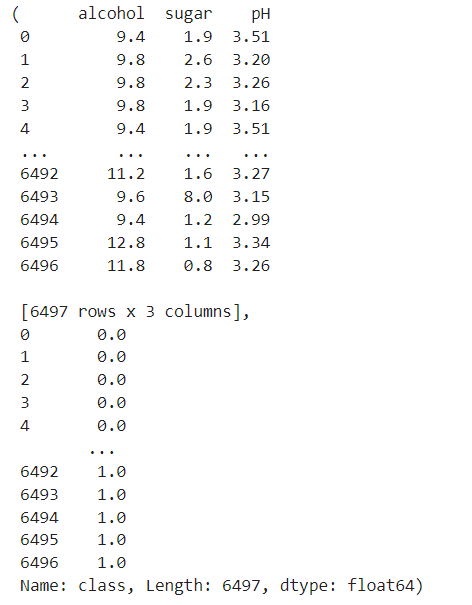
data = pd.read_csv("./data/08_wine.csv")
data.info()
data.describe()
데이터프레임에서 독립변수와 종속변수로 데이터 분리하기
'''
사용할 변수
- 독립변수 : X
- 종속변수 : y
'''
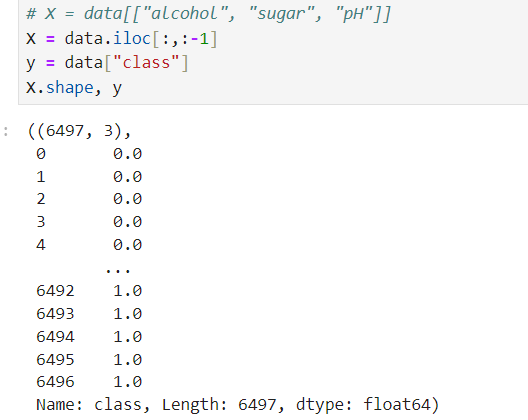
# X = data[["alcohol", "sugar", "pH"]]
X = data.iloc[:,:-1]
y = data["class"]
X, y
정규화
'''
사용할 변수
- 독립변수 정규화 : X_scaled
'''
ss = StandardScaler()
ss.fit(X)
X_scaled = ss.transform(X)
X_scaled
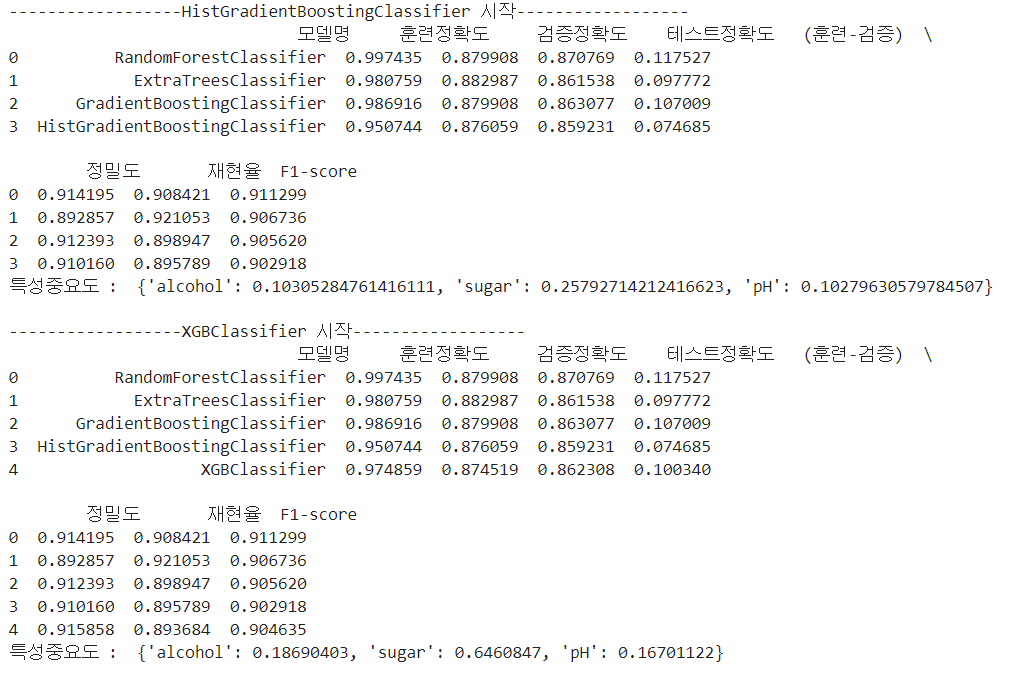
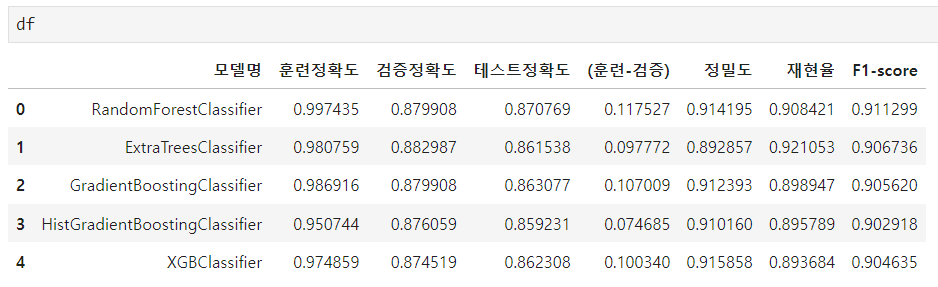
''' 모델 이름을 리스트 변수에 담기 '''
model_name = [rf_model.__class__.__name__,
et_model.__class__.__name__,
gd_model.__class__.__name__,
hg_model.__class__.__name__,
xgb_model.__class__.__name__]
model_name
GridSearchCV를 위한 하이퍼파라미터 매개변수 정의
n_estimators() - 트리의 갯수를 의미함 - 트리의 갯수를 늘리게 되면 모델의 복잡성이 증가됨 - 과적합을 방지하고 더 좋은 성능을 낼 수 있음 - 설정값 : 제한은 없으나, 50, 100 ~ 1000 사이의 값을 주로 사용 - rf, xt, gb, xgb에서 사용가능 - hg에서는 max_iter() 함수를 사용함
max_depth() - 각 트리의 최대 깊이를 의미함(root 노드는 제외) - 트리의 최대 깊이가 길어질 수록 모델의 복잡성이 증가함 - 설정값 : 제한 없음, 주로 None ~ 50 사이의 값이 주로 사용됨 - 모든 모델 사용가능
min_samples_split() - 노드를 분할하기 위한 최소한의 갯수를 의미함 - 설정값: 제한없음, 2 ~ 10 사이의 값이 주로 사용됨 - rf, xt, gb 모델만 사용가능
min_samples_leaf() - 리프 노드 (결정노드)의 최소한의 샘플 수를 의미함 - 설정값 : 제한없음, 1 ~ 10 사이의 값이 주로 사용됨 - rf, xt, gb, hg 모델 사용가능 - xgb 모델은 min_child_weight() 함수 사용