728x90
반응형
심층신경망_훈련
지난 수업 복습하기
- 새로운 모델 생성 : model20 변수명 사용
- epoch 20번 반복 수행
- 프로그래스바가 보이도록 훈련시 출력하기
- 손실 및 정확도 곡선 각각 그리기
- 함수 설정
def model_fn(a_layer = None): model = keras.Sequential() model.add(keras.layers.Flatten(input_shape=(28, 28))) model.add(keras.layers.Dense(100, activation='relu')) ''' 추가할 은닉계층이 있는 경우만 실행 ''' if a_layer : model.add(a_layer) model.add(keras.layers.Dense(10, activation='softmax')) return model
- 함수 호출
model20 = model_fn()
- 모델 설정
model20.compile(loss = "sparse_categorical_crossentropy", metrics="accuracy")
- 모델 훈련
history20 = model20.fit(train_scaled, train_target, epochs=20)
- 시각화
''' 손실률 ''' plt.title("Epoch20 - Loss") plt.plot(history20.epoch, history20.history["loss"]) plt.xlabel("epoch") plt.ylabel("accuracy") plt.grid() plt.savefig("./saveFig/Epoch20-Loss.png") plt.show() ''' 정확도 ''' plt.title("Epoch20 - Accuracy") plt.plot(history20.epoch, history20.history["accuracy"]) plt.xlabel("epoch") plt.ylabel("accuracy") plt.grid() plt.savefig("./saveFig/Epoch20-Accuracy.png") plt.show()

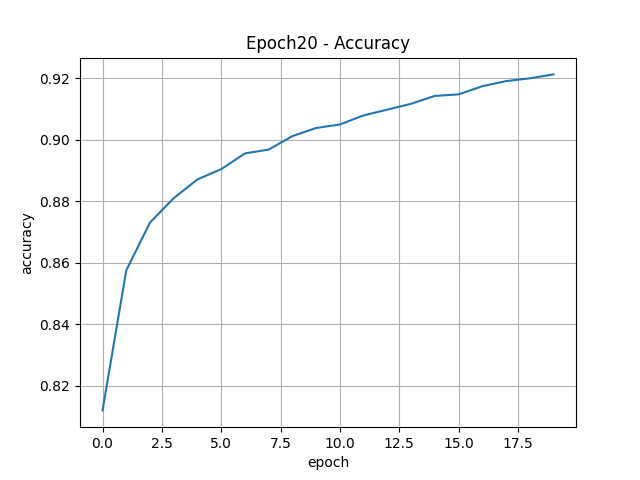
- 훈련에 대한 손실 및 정확도 곡선을 하나의 그래프로 그리기
plt.figure(figsize=(12, 6)) # 손실률 그래프 plt.plot(history20.epoch, history20.history["loss"]) # 정확도 그래프 plt.plot(history20.epoch, history20.history["accuracy"]) plt.xlabel("Epoch") plt.ylabel("Loss & Accuracy") plt.grid() # 범례 추가 plt.legend(['Loss', 'Accuracy']) # 제목 설정 plt.title("Epoch20 - Loss and Accuracy") # 그래프 저장 plt.savefig("./saveFig/Epoch20-Loss-Accuracy.png") plt.show()

훈련 및 검증에 대한 손실 및 정확도 모두 표현하기
- 함수 호출
model = model_fn()
- 모델 설정
model.compile(loss = "sparse_categorical_crossentropy", metrics="accuracy")
- 모델 훈련
''' - validation_data : 검증 데이터를 이용해서 성능평가를 동시에 수행함 ''' history = model.fit(train_scaled, train_target, epochs=20, verbose=1, validation_data=(val_scaled, val_target))
- history에서 가져올수 있는 값 확인
history.history.keys()

훈련에 대한 loss와 검증에 대한 loss 비교하는데 유용
- 시각화 - 손실곡선
''' - 훈련과 검증에 대한 손실(loss) 곡선 그리기 ''' # 훈련 손실률 그래프 plt.plot(history.epoch, history.history["loss"]) # 검증 손실률 그래프 plt.plot(history.epoch, history.history["val_loss"]) plt.xlabel("Epoch") plt.ylabel("Loss") plt.grid() # 범례 추가 plt.legend(['Train_Loss', 'Val_Loss']) # 제목 설정 plt.title("Epoch20 - Train_Loss & Val_Loss") # 그래프 저장 plt.savefig("./saveFig/Train-Loss-Val-Loss.png") plt.show()

- 딥러닝은 손실률을 기준으로 판단한다.
- 훈련 곡선이 검증 곡선 보다 밑에 있어야 과소적합이 일어나지 않는다.
- Epoch가 2인 시점에 두 곡선이 가장 가까우면서 그 이후로 과대적합이 발생하고 있다.
- 시각화 - 정확도 곡선
''' - 훈련과 검증에 대한 정확도(accuracy) 곡선 그리기 ''' # 훈련 정확도 그래프 plt.plot(history.epoch, history.history["accuracy"]) # 검증 정확도 그래프 plt.plot(history.epoch, history.history["val_accuracy"]) plt.xlabel("Epoch") plt.ylabel("Accuracy") plt.grid() # 범례 추가 plt.legend(['Train_Accuracy', 'Val_Accuracy']) # 제목 설정 plt.title("Epoch20 - Train_Acc & Val_Acc") # 그래프 저장 plt.savefig("./saveFig/Train-Acc-Val-Acc.png") plt.show()

- 손실이 과대적합이 일어나면 정확도 또한 과대적합이 일어날 가능성이 높다.
- Epoch가 2인 시점부터 시작하여 과대적합이 일어나고 있다.
훈련 및 검증에 대한 손실 및 정확도 표현하여 과적합 여부 확인하기
- model 변수명으로 신규 모델 만들기
- 옵티마이저 adam 사용
- 훈련 및 검증 동시에 훈련시킨 후 손실 및 검증 곡선 그려서 과적합 여부 확인하기
- 함수 호출하기
model = model_fn()
- 모델 설정
model.compile( ### 옵티마이저 정의 : 손실을 줄여나가는 방법 optimizer="adam", ### 손실함수 : 종속변수의 형태에 따라 결정 됨 loss="sparse_categorical_crossentropy", ### 훈련 시 출력할 값 : 정확도 출력 metrics="accuracy" )
- 모델 훈련
history = model.fit(train_scaled, train_target, epochs=20, verbose=1, validation_data=(val_scaled, val_target))
- 시각화 - 손실곡선 & 정확도 곡선
# 훈련 정확도 그래프 plt.plot(history.epoch, history.history["accuracy"]) # 검증 정확도 그래프 plt.plot(history.epoch, history.history["val_accuracy"]) plt.xlabel("Epoch") plt.ylabel("Accuracy") plt.grid() # 범례 추가 plt.legend(['Train_Accuracy', 'Val_Accuracy']) # 제목 설정 plt.title("Adam-Train_Acc & Val_Acc") # 그래프 저장 plt.savefig("./saveFig/Adam-Train-Acc-Val-Acc.png") plt.show()

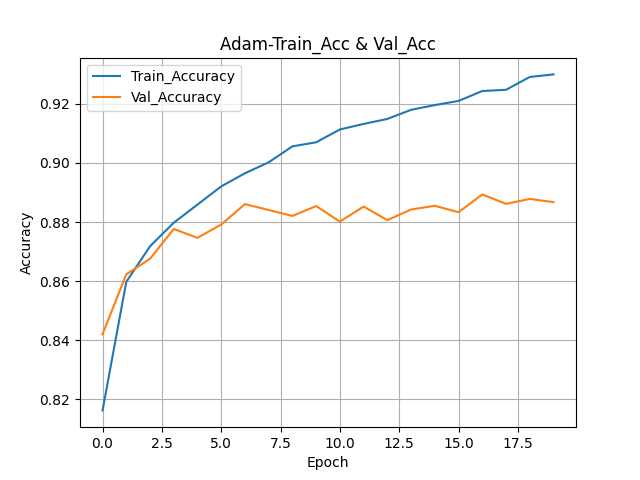
Epoch 3인 시점에서 두 곡선이 가장 가깝다.
그 이후로는 과대적합이 일어나고 있다.
- Epoch 200번으로 설정하여 모델 훈련 및 시각화
history = model.fit(train_scaled, train_target, epochs=200, verbose=1, validation_data=(val_scaled, val_target))
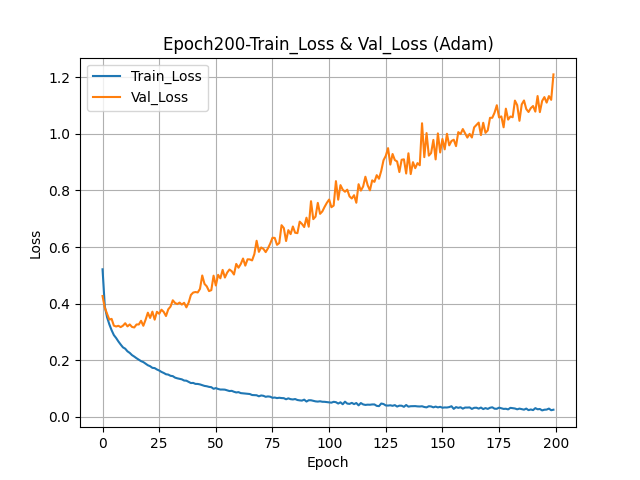
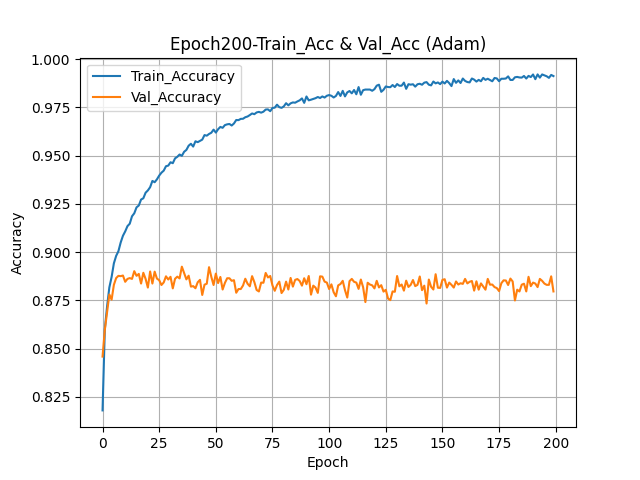
심층신경망_성능 규제
📍성능 규제
- 성능(과적합 여부 포함)을 높이기 위한 방법
- 보통 전처리 계층을 사용하게 된다.
- 전처리 계층은 훈련에 영향을 미치지 않음
성능 규제 방법 - 드롭 아웃(Dropout())
📍드롭아웃(Dropout)
- 훈련 과정 중 일부 특성들을 랜덤하게 제외 시켜서 과대적합을 해소하는 방법
- 딥러닝에서 자주 사용되는 전처리 계층으로 성능 개선에 효율적으로 사용됨
📍사용방법
- 계층의 중간에 은닉층(hidden layer)으로 추가하여 사용됨
- 훈련에 관여하지 않음 → 데이터에 대한 전처리라고 보면 됨
- 모델 생성
''' Dropout(0.3) : 사용되는 특성 30% 정도를 제외하기 ''' dropout_layer = keras.layers.Dropout(0.3) model = model_fn(dropout_layer) model.summary()
- 모델 설정
model.compile( ### 옵티마이저 정의 : 손실을 줄여나가는 방법 optimizer="adam", ### 손실함수 : 종속변수의 형태에 따라 결정 됨 loss="sparse_categorical_crossentropy", ### 훈련 시 출력할 값 : 정확도 출력 metrics="accuracy" )
- 모델 훈련
history = model.fit(train_scaled, train_target, epochs=20, verbose=1, validation_data=(val_scaled, val_target))
- 시각화 - 손실곡선 & 정확도 곡선
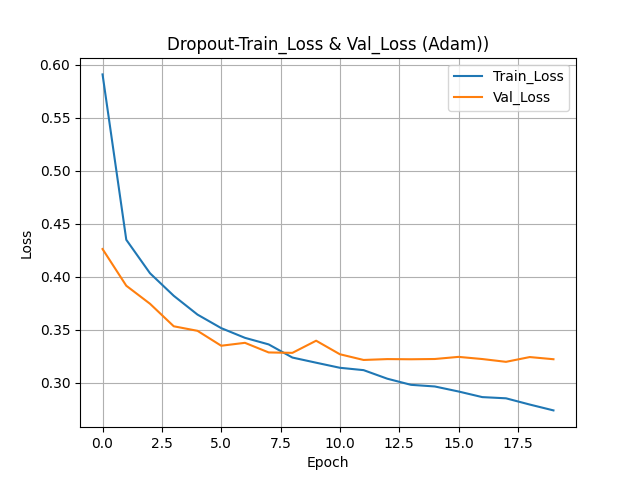

더보기
강사님 그래프 설명
손실률은 훈련 곡선이 아래 있어야 함
Epoch 8 시점에서 두 곡선이 가까움
Epoch 7.5를 기점으로 과대적합이 점점 일어나고 있음 > Epoch 8까지가 적당
훈련 곡선이 검증 곡선 위에 있으면 과소적합이 일어남
정확도는 훈련 곡선이 위에 있어야 함
Epoch 10을 기준으로 왼쪽은 과소적합 오른쪽은 과대적합
손실률이 Epoch 8 시점에서 가장 좋게 나타나면 정확도 Epoch 8 시점을 비교해 본다
손실률과 정확도를 비교하여 적절한 Epoch를 찾아내고 그 시점까지로 다시 훈련시킨다.
Epoch 14회 정도 돌리면 가장 적절한 횟수를 찾을 수 있을 것 같다
모델 저장 및 복원하기
📍모델 저장하는 방법
- 가중치만 저장하기
→ 모델이 훈련하면서 찾아낸 가중치 값들만 저장하기
→ 모델 자체가 저장되지는 않는다
→ 모델 신규생성 > 저장된 가중치 불러와서 반영 > 예측 진행
→ 별도로 훈련(fit)은 하지 않아도 된다
- 모델 자체 저장하기
→ 저장된 모델을 불러와서 > 예측 진행
가중치 저장 및 불러들이기
- 가중치 저장하기
''' 저장시 사용되는 확장자는 보통 h5를 사용한다 ''' model.save_weights("./model/model_weight.h5") - 저장된 가중치 불러들이기
''' 1. 모델 생성 ''' model_weight = model_fn(keras.layers.Dropout(0.3)) model_weight.summary() ''' 2. 가중치 적용하기 ''' model_weight.load_weights("./model/model_weight.h5") ''' 이후 부터는 바로 예측으로 사용 '''
모델 자체를 저장 및 불러들이기
- 모델 자체 저장하기
model.save("./model/model_all.h5")
- 모델 자체 불러들이기
model_all = keras.models.load_model("./model/model_all.h5") model_all.summary() ''' 이후 부터는 바로 예측으로 사용 ''' - 예측하기
pred_data = model_all.predict(val_scaled) pred_data[0]
- 종속변수가 10개 이므로 10개의 값이 들어있어야 함
- 마지막 출력 값 또한 10개 - 예측 확인하기
import numpy as np np.argmax(pred_data[0]), val_target[0]
''' 예측 결과의 모든 행에 대해서 가장 높은 값을 가지는 열의 인덱스 위치 추출 ''' val_pred = np.argmax(pred_data, axis=1) val_pred
- 정답갯수, 오답갯수, 정답률, 오답률 출력
''' 방법 1 ''' # 정답 갯수 correct_count = np.sum(val_pred == val_target) # correct_count = len(val_pred[val_pred == val_target]) # 오답 갯수 incorrect_count = np.sum(val_pred != val_target) # incorrect_count = len(val_pred[val_pred != val_target]) # 정답률 accuracy = correct_count / len(val_target) # 오답률 error_rate = incorrect_count / len(val_target) # 결과 출력 print("정답 갯수:", correct_count) print("오답 갯수:", incorrect_count) print("정답률:", accuracy) print("오답률:", error_rate) ''' 방법 2 ''' correct_count = 0 incorrect_count = 0 for i, j in zip(val_pred, val_target): if i == j: correct_count += 1 elif i != j : incorrect_count +=1 print(f"정답 : {correct_count}") print(f"오답 : {incorrect_count}") print(f"정답률 : {correct_count / len(val_target)}") print(f"오답률 : {incorrect_count / len(val_target)}")
심층신경망_성능 향상
성능 향상 - 콜백(Callback) 함수
📍 콜백함수(Callback Function)
- 모델 훈련 중에 특정 작업(함수)를 호출할 수 있는 기능
- 훈련(fit)시에 지정하는 함수를 호출하는 방식
- 훈련 중에 발생시키는 "이벤트"라고 생각하면 된다
- 별도의 계층은 아니며, 속성(매개변수)으로 정의된다.
📍 콜백함수 종류
- ModelCheckpoint()
: epoch 마다 모델을 저장하는 방식
: 단, 앞에서 실행된 훈련 성능보다 높아진 경우에만 저장됨
- EarlyStopping()
: 훈련이 더이상 좋아지지 않으면 훈련(fit)을 종료시키는 방식
: 일반적으로 ModelCheckpoint()와 함께 사용
ModelCheckPoint 콜백 함수
- 모델 생성하기
model = model_fn(keras.layers.Dropout(0.3)) - 모델 설정하기
model.compile( ### 옵티마이저 정의 : 손실을 줄여나가는 방법 optimizer="adam", ### 손실함수 : 종속변수의 형태에 따라 결정 됨 loss="sparse_categorical_crossentropy", ### 훈련 시 출력할 값 : 정확도 출력 metrics="accuracy" ) - 콜백함수 생성하기
- 훈련(fit) 전에 생성
- save_best_only = True
: 이전에 수행한 검증 손실률보다 좋을 떄 마다 훈련모델 자동 저장 시키기
: 훈련이 종료되면, 가장 좋은 모델만 저장되어 있다.
- save_best_only = False
: epoch마다 훈련모델 자동 저장 시키기
- 저장된 모델은 모델 자체가 저장되는 방식으로 추후 불러들인 후 바로 예측으로 사용 가능
checkpoint_cb = keras.callbacks.ModelCheckpoint( "./model/best_model.h5", save_best_only = True ) - 모델 훈련하기
- fit()함수 내에 콜백함수 매개변수에 정의
history = model.fit( train_scaled, train_target, epochs=10, verbose=1, validation_data=(val_scaled, val_target), ### 콜백함수에 대한 매개변수 : 리스트 타입으로 정의 callbacks=[checkpoint_cb] ) - 콜백함수를 통해 저장된 모델 불러들이기
model_cp_cb = keras.models.load_model("./model/best_model.h5") model_cp_cb.summary() model_cp_cb.evaluate(val_scaled, val_target)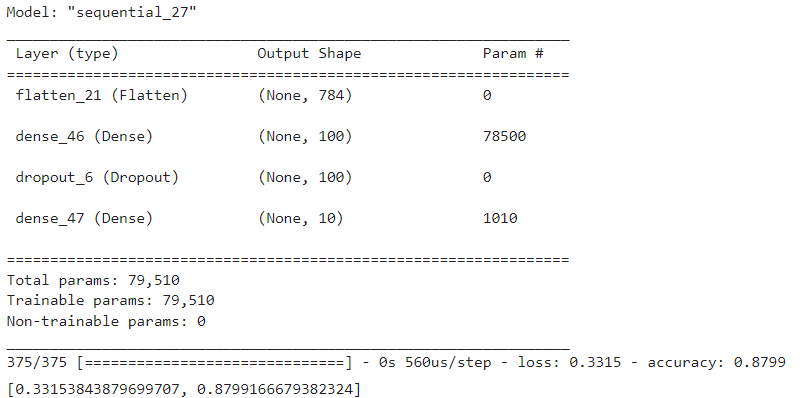
EarlyStopping 콜백 함수
- 모델 생성하기 (이전과 동일)
- 모델 설정하기 (이전과 동일)
- 콜백함수 생성하기
- patience=2
: 더 이상 좋아지지 않는 epoch의 갯수 지정
: 가장 좋은 시점의 epoch 이후 2번 더 수행 후 그래도 좋아지지 않으면 종료시킨다는 의미
- restore_best_weights=True : 가장 낮은 검증 손실을 나타낸 모델의 하이퍼파라미터로 모델을 업데이트 시킴
''' ModelCheckpoint() ''' checkpoint_cb = keras.callbacks.ModelCheckpoint( "./model/best_model.h5", save_best_only = True ) ''' EarlyStopping() ''' early_stopping_cb = keras.callbacks.EarlyStopping( patience=2, restore_best_weights=True ) - 모델 훈련시키기
- fit()함수 내에 콜백함수 매개변수에 정의
history = model.fit( train_scaled, train_target, epochs=100, verbose=1, validation_data=(val_scaled, val_target), ### 콜백함수에 대한 매개변수 : 리스트 타입으로 정의 callbacks=[checkpoint_cb, early_stopping_cb] )
Epoch 4 에서 종료. 여기서 -2 한 Epoch 2가 가장 최적화 된 모델로 저장되어 있음 - 콜백함수를 통해 저장된 모델 불러들이기
model_f = keras.models.load_model("./model/best_model.h5") model_f.summary() print(model_f.evaluate(train_scaled, train_target)) print(model_f.evaluate(val_scaled, val_target))
728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][DL] Deep Learning - 퍼셉트론(Perceptron) 모델 (0) | 2024.01.05 |
|---|---|
| [인공지능][DL] Deep Learning 실습 - DNN 분류데이터 사용 (1) | 2024.01.05 |
| [인공지능][DL] Deep Learning - 심층신경망 훈련 및 성능향상 (1) | 2024.01.03 |
| [인공지능][DL] Deep Learning 실습 - 신경망계층 추가방법 및 성능향상방법 (1) | 2024.01.03 |
| [인공지능][DL] Deep Learning - 신경망계층 추가방법 및 성능향상방법 (1) | 2024.01.03 |