728x90
반응형
신경망계층 추가방법
라이브러리
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
데이터 수집 및 정규화
📍 fashion_mnist 데이터를 이용해서 훈련 및 테스트에 대한 독립변수와 종속변수 읽어 들이기
→ 변수는 항상 사용하는 변수명으로 설정
📍 정규화하기
📍 훈련의 독립 및 종속변수를 이용해서 훈련 : 검증 = 8 : 2로 분류하기
- 데이터수집
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)
- 데이터 스케일링
'''
255로 나누는 이유는 이미지 데이터가 보통 0에서 255 사이의 픽셀 값으로 구성되어 있기 때문이다.
각 픽셀의 값이 0일 때는 최소값, 255일 때는 최대값이므로,
이 값을 0에서 1 사이의 범위로 매핑하기 위해 255로 나누어준다.
이렇게 하면 모든 픽셀 값이 0에서 1 사이의 실수 값으로 정규화된다.
'''
train_scaled_255 = train_input / 255.0
train_scaled_255[0]
test_scaled_255 = test_input / 255.0
test_scaled_255[0]
train_scaled_255.shape, test_scaled_255.shape
- 모델 훈련에 사용하기 위해 2차원으로 변환
train_scaled_2d = train_scaled_255.reshape(-1, 28*28)
test_scaled_2d = test_scaled_255.reshape(-1, 28*28)
- 훈련 : 검증 데이터로 분류하기(8:2)
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled_2d,
train_target,
test_size=0.2,
random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)
print(test_scaled_2d.shape, test_target.shape)
신경망 모델에 계층(layer) 추가하는 방법 3가지
1. 층을 먼저 만들고, 신경망 모델 생성 시 추가하기
''' 입력계층(Input layer) 생성하기 '''
dense1 = keras.layers.Dense(100, activation="sigmoid", input_shape=(784,))
''' 출력계층(Output layer) 생성하기 '''
dense2 = keras.layers.Dense(10, activation="softmax")
''' 신경망 모델 생성하기 '''
### 여러개를 넣어야 할 때 리스트[] 사용
model = keras.Sequential([dense1, dense2])
model''' 입력계층(Input layer) 생성하기 '''
dense1 = keras.layers.Dense(100, activation="sigmoid", input_shape=(784,))
''' 출력계층(Output layer) 생성하기 '''
dense2 = keras.layers.Dense(10, activation="softmax")
''' 신경망 모델 생성하기 '''
### 여러개를 넣어야 할 때 리스트[] 사용
model = keras.Sequential([dense1, dense2])
model''' 모델 계층 확인하기 '''
model.summary()
- Output Shape로 100개를 출력해냄
- 다음 계층(dense_1)이 100개를 입력 계층으로 받음
- 그리고 다시 시그모이드 함수를 이용해 10개로 출력해냄
- dense_1에서 훈련에 관여하고 있는 계층 78500개
- param이 0 이면 훈련에 영향을 미치고 있는 계층이 없다.
2. 신경망모델 생성 시 계층(layer)을 함께 추가
''' 모델 생성 및 계층 추가하기 '''
model = keras.Sequential([
keras.layers.Dense(100, activation="sigmoid",
input_shape=(784,), name = "Input-layer"),
keras.layers.Dense(10, activation="softmax", name = "Output-layer")],
name = "Model-2"
)model.summary()
3. 신경망 모델을 먼저 생성 후, 계층 추가하기
''' 신경망 모델 생성하기
- 일반적으로 사용되는 방식
- 위의 1, 2 방법으로 수행 후, 계층을 추가할 필요성이 있을 경우에도 사용됨'''
model = keras.Sequential()
''' 계층 생성 및 모델에 추가하기 '''
model.add(
keras.layers.Dense(100, activation="sigmoid", input_shape(784,), name="Input-Layer")
)
model.add(
keras.layers.Dense(10, activation="softmax", name="Output-Layer")
)model.summary()
모델 설정하기(compile)
''' 손실함수는 다중분류 사용 '''
model.compile(
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
모델 훈련하기(fit)
''' 반복횟수 10번 '''
model.fit(train_scaled, train_target, epochs=10)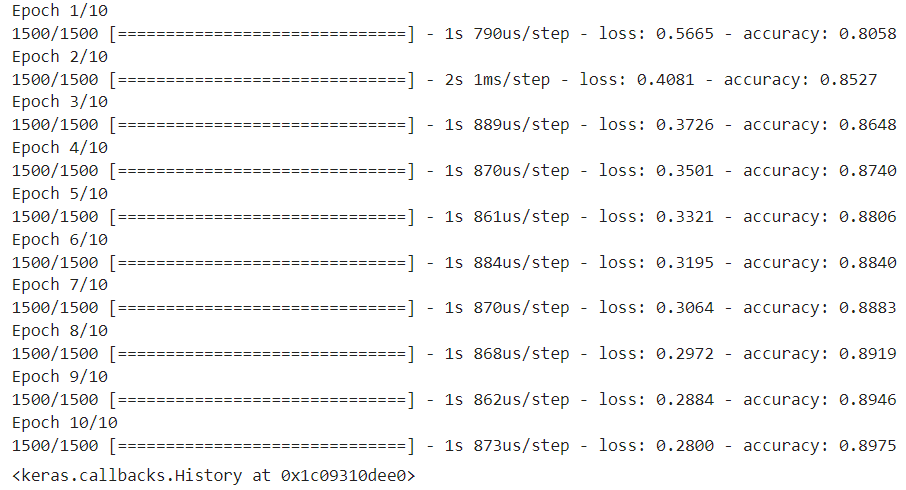
- 마지막에 가장 높은 값이 나오면 epochs를 증가시켜야 한다. 더 높은 정확도가 나올 수 있기 때문이다.
- 기본적으로 100번 정도 실행한다.
- 실행 중간에 가장 높은 값이 나오면 epochs는 그 시점의 횟수가 한계이므로 해당 횟수까지만 돌리면 된다.
모델 성능 평가하기(evaluate)
''' 성능평가하기(검증) '''
score = model.evaluate(val_scaled, val_target)
''' 손실율과 정확도 출력하기 '''
print(f"손실율 : {score[0]} / 정확도 : {score[1]}")
훈련 모델과 검증 모델을 비교해 봤을 때 정확도가 높은 편은 아니지만,
과소/과대에 해당하지 않고 일반화된 모델이라고 볼 수 있다.
신경망계층 성능향상방법
<성능 개선 방법>
1. 데이터 증가 시키기
2. 하이퍼파라미터 튜닝
→ 성능이 현저히 낮은 경우에는 튜닝 필요, 일반적으로 딥러닝에서는 디폴트 값을 사용해도 된다.
→ 반복 횟수 증가
→ 계층 추가 또는 제거(일반적으로 추가)
→ 이외 하이퍼파라미터들
1. 성능향상 - 은닉 계층(Hidden Layer) 추가
- 모델 생성하기
model = keras.Sequential()- 입력 계층 추가하기
- 전처리 계층으로 추가
- Flatten()
→ 차원축소 전처리 계층(1차원으로 축소)
→ 훈련에 영향을 미치지는 않음
→ 일반적으로 입력계층 다음에 추가하거나 입력계층으로 사용되기도 함
→ 이미지 데이터 처리 시에 주로 사용됨
model.add(
keras.layers.Flatten(input_shape=(28, 28))
)- 중간계층 = 은닉계층(hidden layer) 생성하기
- Dense() 계층은 모델 성능에 영향을 미침
- relu : 0보다 크면 1, 0보다 작으면 0
model.add(
keras.layers.Dense(100, activation="relu")
)- 출력 계층(Output Layer) 생성하기
model.add(
keras.layers.Dense(10, activation="softmax")
)- 모델에 추가된 계층 모두 확인하기
model.summary()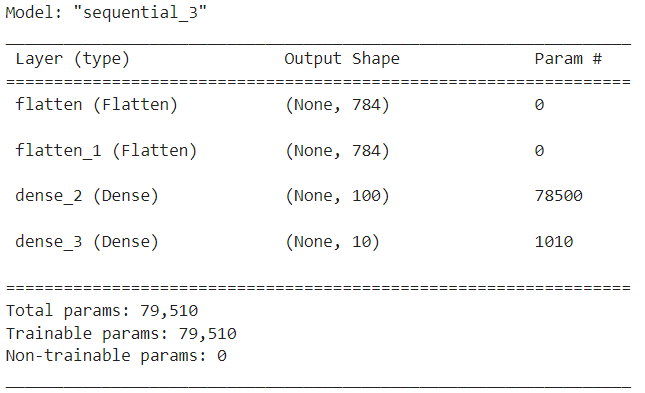
- 모델 설정하기(compile)
''' 손실함수는 다중분류 사용 '''
model.compile(
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
차원축소하지 않은 정규화된 데이터로 다시 생성
- 데이터 불러오기
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)- 데이터 정규화
train_scaled_255 = train_input / 255.0
train_scaled_255[0]
test_scaled_255 = test_input / 255.0
test_scaled_255[0]
train_scaled_255.shape, test_scaled_255.shape- 훈련 : 검증 데이터로 분류
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled_255,
train_target,
test_size=0.2,
random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)
print(test_scaled_255.shape, test_target.shape)- 모델 훈련하기(fit)
model.fit(train_scaled, train_target, epochs=100)
- 모델 성능 평가하기(evaluate)
''' 성능평가하기(검증) '''
score = model.evaluate(val_scaled, val_target)
''' 손실율과 정확도 출력하기 '''
print(f"손실율 : {score[0]} / 정확도 : {score[1]}")
2. 성능향상 - 옵티마이저(Optimizer)
- 모델 설정하기(compile)
- 옵티마이저(Optimizer)
→ 옵티마이저 설정 위치 : compile() 시에 설정함
→ 손실을 줄여나가기 위한 방법을 설정함
→ 손실을 줄여나가는 방법을 보통 "경사하강법"이라고 칭한다.
→ "경사하강법"을 이용한 여러 가지 방법들 중 하나를 선택하는 것이 옵티마이저 선택이다.
→ 옵티마이저 종류 : SGD(확률적 경사하강법), Adagrad, RMSProp, Adam이 있음
📍 SDG(확률적 경사하강법)
- 현재 위치에서 기울어진 방향을 찾을 때 지그재그 모양으로 탐색해 나가는 방법
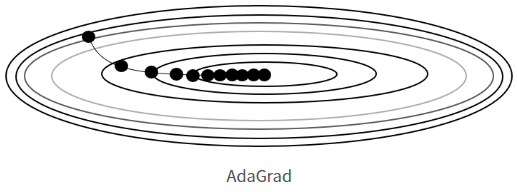
📍 Adagrad
- 학습률(보폭)을 적절하게 설정하기 위해 학습율 감소라는 기술을 사용
- 학습 진행 중에 학습률을 줄여가는 방법을 사용
- 처음에는 학습율을 크게 학습하다가, 점점 작게 학습한다는 의미
- 기울기가 유연함
📍 RMSProp
- Adagrad의 단점을 보완한 방법
- Adagrad는 학습량을 점점 작게 학습하기 때문에 학습량이 0이 되어 갱신(학습)되지 않는 시점이 발생할 수 있는 단점이 있음
- 이러한 단점을 보완하여 과거의 기울기 값을 반영하는 방식 사용
- 먼 과거의 기울기(경사) 값은 조금 반영하고, 최근 기울기(경사)를 많이 반영
- Optimizer의 기본값(default)으로 사용됨
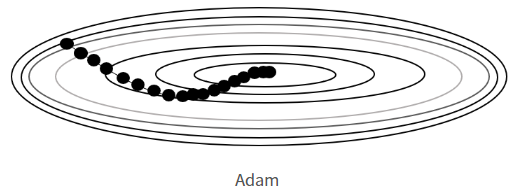
📍 Adam
- 공이 굴러가듯이 모멘텀(momentum → 관성)과 Adagrad를 융합한 방법
** 모멘텀 : 관성과 가속도를 적용하여 이동하던 방향으로 좀 더 유연하게 작동함
- 자주 사용되는 기법으로, 좋은 결과를 얻을 수 있는 방법으로 유명함
- 메모리 사용이 많은 단점이 있음(과거 데이터를 저장해 놓음)
어떤 걸 써야 하는지 정해져 있지 않음
가장 좋은 건 모멘텀을 적용한 adam
sgd는 가장 초기에 나왔기 때문에 많이 사용하기 않음.
기본값인 RMSProp을 사용하고 adam사용.
하이퍼파라미터 튜닝을 한다면 모두 다 사용해 보는 것을 추천

model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="sgd",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
- 모델 훈련하기(fit)
model.fit(train_scaled, train_target, epochs=10)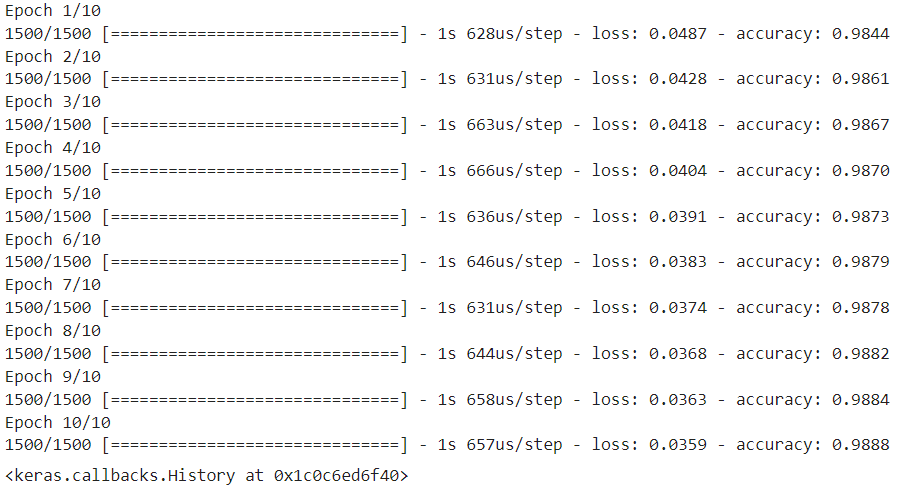
- 모델 성능 평가하기(evaluate)
''' 성능평가하기(검증) '''
score = model.evaluate(val_scaled, val_target)
''' 손실율과 정확도 출력하기 '''
print(f"손실율 : {score[0]} / 정확도 : {score[1]}")
옵티마이저에 학습률 적용하기
- 학습률을 적용하는 방법
- 사용되는 4개의 옵티마이저를 객체로 생성하여 learning_rate(학습률) 값을 설정할 수 있음
- 학습률 : 보폭이라고 생각하면 됨
- 학습률이 작을수록 보폭이 작다고 보면 됨
- 가장 손실이 적은 위치를 찾아서 움직이게 됨
- 이때 가장 손실이 적은 위치는 모델이 스스로 찾아서 움직이게 됨(사람이 관여하지 않음)
- 학습률의 기본값은 = 0.01을 사용(사용값의 범위 0.1 ~ 0.0001 정도) - 과적합을 해소하기 위한 튜닝방법으로 사용됨
- 과대적합이 일어난 경우 : 학습률을 크게
- 과소적합이 일어난 경우 : 학습률을 작게
- 과대/과소를 떠나서, 직접 값의 법위를 적용하여 튜닝을 수행한 후 가장 일반화 시점의 학습률 값을 찾는 것이 중요함 - 옵티마이저 객체 생성 및 모델 설정
''' 옵티마이저 객체 생성 '''
sgd = keras.optimizers.SGD(learning_rate=0.1)
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="sgd",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)- 모델 훈련하기
model.fit(train_scaled, train_target, epochs=50)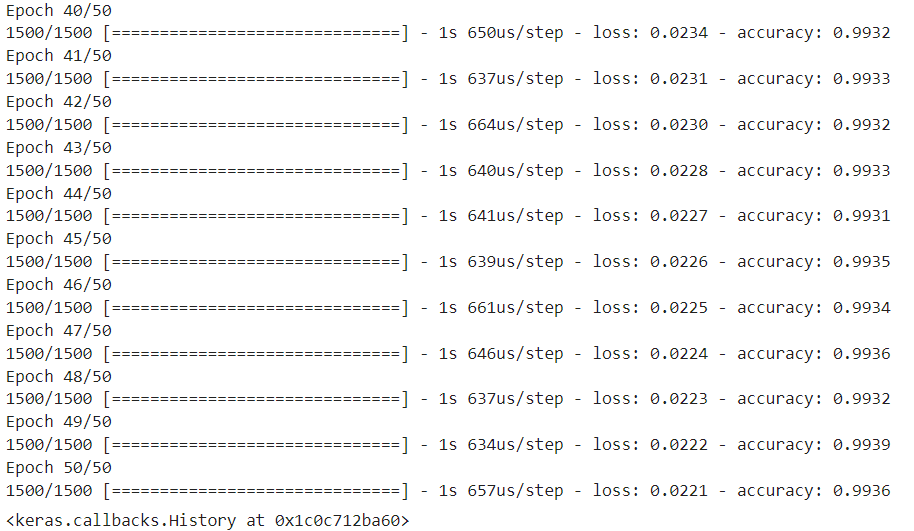
- 모델 성능 평가하기(evaluate)
''' 성능평가하기(검증) '''
score = model.evaluate(val_scaled, val_target)
''' 손실율과 정확도 출력하기 '''
print(f"손실율 : {score[0]} / 정확도 : {score[1]}")
모멘텀(Momentum) 직접 적용하기
- 모멘텀(Momentum)
- 기존의 방향(기울기)을 적용하여 관성을 적용시키는 방법
- 기본적으로 0.9 이상의 값을 적용시킴
- 보통 nesterov=True 속성과 함께 사용됨
→ nesterov=True : 모멘텀 방향보다 조금 더 앞서서 경사를 계산하는 방식(미리 체크)
- momentum 속성을 사용할 수 있는 옵티마이저 : SGD, RMSProp
''' 옵티마이저 객체 생성 '''
sgd = keras.optimizers.SGD(
momentum=0.9,
nesterov=True,
learning_rate=0.1
)
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="sgd",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)- 모델 훈련하기
model.fit(train_scaled, train_target, epochs=50)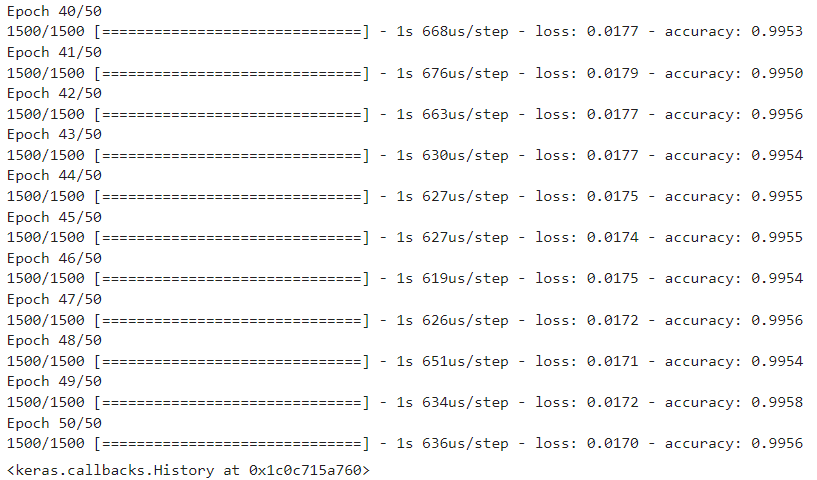
- 모델 성능 평가하기(evaluate)
''' 성능평가하기(검증) '''
score = model.evaluate(val_scaled, val_target)
''' 손실율과 정확도 출력하기 '''
print(f"손실율 : {score[0]} / 정확도 : {score[1]}")
adagrad
''' adagrad '''
adagrad = keras.optimizers.Adagrad()
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer=adagrad,
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' 또는 '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adagrad",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
RMSprod
''' RMSProd '''
rmsprop = keras.optimizers.RMSprop()
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer=rmsprop,
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' 또는 '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="rmsprop",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)Adam
''' Adam '''
adam = keras.optimizers.Adam()
''' 모델 설정(compile) '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer=adam,
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
''' 또는 '''
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adam",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
실습
[인공지능][DL] Deep Learning 실습 - 신경망계층 추가방법 및 성능향상방법
실습 - 1 1. 신경망 모델 생성 2. 계층 추가하기 - 1차원 전처리 계층 추가 - 은닉계층 추가, 활성화함수 relu 사용, 출력크기 100개 - 최종 출력계층 추가 3. 모델설정하기 - 옵티마이저는 adam 사용, 학
mzero.tistory.com
728x90
반응형
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][DL] Deep Learning - 심층신경망 훈련 및 성능향상 (1) | 2024.01.03 |
|---|---|
| [인공지능][DL] Deep Learning 실습 - 신경망계층 추가방법 및 성능향상방법 (1) | 2024.01.03 |
| [인공지능][DL] Deep Learning - Tensorflow / 인공신경망 (0) | 2023.12.29 |
| [인공지능][ML] Machine Learning - 모델 저장하기 및 불러오기 (0) | 2023.12.29 |
| [인공지능][ML] Machine Learning - 군집모델 / 군집분석 / 주성분분석(PCA) (0) | 2023.12.28 |