🎈KNN 회귀모델
데이터 입력과 훈련 - 농어의 길이와 무게
### 농어 길이
perch_length= np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
### 농어 무게
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
🎈 농어의 길이로, 무게 예측하기
- 독립변수 : 길이
- 종속변수 : 무게(연속)
perch_length.shape, perch_weight.shape
🎈 산점도 그리기
import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight)
plt.xlabel("length")
plt.ylabel("weight")
plt.show()
해석
- 초반에는 곡선을 띄는 듯하다가, 중반부부터는 직선의 형태를 나타내고 있음
- 종속변수가 연속형 데이터이며, 선형 분포를 나타내기에 회귀모델을 사용함
🎈 훈련 및 테스트 데이터 분류하기
- 훈련 : 테스트 = 75 : 25로 구분
- 사용변수 : train_input, train_target, test_input, test_target
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length,
perch_weight,
test_size=0.25,
random_state=42)
print(f"{train_input.shape} : {train_target.shape}")
print(f"{test_input.shape} : {test_target.shape}")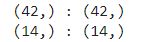
🎈 훈련 및 테스트의 독립변수를 2차원으로 만들기
### 훈련 독립변수 2차원 만들기
# -1 : 전체를 의미함
train_input = train_input.reshape(-1, 1)
### 테스트 독립변수 2차원 만들기
test_input = test_input.reshape(-1, 1)
print(f"{train_input.shape} / {test_input.shape}")
🎈 모델 훈련하기
from sklearn.neighbors import KNeighborsRegressor
### 모델(클래스 생성하기)
knr = KNeighborsRegressor()
### 모델 훈련시키기
knr.fit(train_input, train_target)
### 훈련 정확도 확인하기
train_r2 = knr.score(train_input, train_target)
### 검증 정확도 확인하기
test_r2 = knr.score(test_input, test_target)
print(f"훈련={train_r2} / 테스트={test_r2}")
해석
- 훈련 및 테스트 정확도는 매우 높게 나타난 성능 좋은 모델로 판단됨
- 그러나 과적합 여부를 확인한 결과, 훈련 정확도가 테스트 정확도보다 낮게 나타난 것으로 보아 과소 적합이 발생하고 있는 것으로 판단됨
- 이는 데이터의 갯수가 적거나, 튜닝이 필요한 경우로 이후 진행을 하고자 함
모델 평가하기 : 평균절대오차(MAE)
🎈 평균절대오차(MAE; Mean Absolute Error)
- 회귀에서 사용하는 평가방법
- 예측값과 실제값의 차이를 평균하여 계산한 값
- 즉, 사용된 이웃들과의 거리차를 평균한 값
- 라이브러리
from sklearn.metrics import mean_absolute_error
🎈 예측하기
- 5개 이웃의 평균 값이 나옴
test_pred = knr.predict(test_input)
test_pred
🎈 평가하기
- mean_absolute_error(실제 종속변수, 예측 종속변수)
mae = mean_absolute_error(test_target, test_pred)
mae
해석
- 해당 모델을 이용해서 예측을 할 경우에는
- 평균적으로 → 약 19.157g 정도의 차이(오차)가 있는 결과를 얻을 수 있음
- 즉, 예측결과는 약 19.157g 정도의 차이가 있다
하이퍼파라미터 튜닝
🎈 과소적합을 해소하기 위하여 튜닝을 진행해 보기
- 이웃의 갯수 → 기본값 사용
### KNN 모델의 이웃의 갯수(하이퍼파리미터)를 조정해보기
### 이웃의 갯수 -> 기본값 사용
knr.n_neighbors = 5
### 하이퍼파라미터 값 수정 후 재훈련 시켜서 검증해야 한다.
knr.fit(train_input, train_target)
### 훈련정확도 확인
train_r2 = knr.score(train_input, train_target)
### 테스트(검증) 정확도 확인
test_r2 = knr.score(test_input, test_target)
print(f"훈련={train_r2} / 테스트={test_r2}")
해석
- 과적합 여부 확인 결과 과소적합이 발생하여, 훈련모델로 적합하지 않음
- 과소적합 해소 필요
- 이웃의 갯수 조정
### KNN 모델의 이웃의 갯수(하이퍼파리미터)를 조정해보기
knr.n_neighbors = 3
### 하이퍼파라미터 값 수정 후 재훈련 시켜서 검증해야 한다.
knr.fit(train_input, train_target)
### 훈련정확도 확인
train_r2 = knr.score(train_input, train_target)
### 테스트(검증) 정확도 확인
test_r2 = knr.score(test_input, test_target)
print(f"훈련={train_r2} / 테스트={test_r2}")
해석
- 과소적합 해소를 위해 이웃의 갯수를 조정하여 하이퍼파라미터 튜닝을 진행한 결과
- 과소적합을 해소할 수 있었음
- 또한, 훈련 정확도와 테스트 정확도의 차이가 크지 않기에 과대적합도 일어나지 않았음
- 다만, 테스트 정확도는 다소 낮아진 반면 훈련정 확도가 높아졌음
- 이 모델은 과적합이 발생하지 않은 일반화된 모델로 사용가능
🎈 가장 적합한 이웃의 갯수 찾기(하이퍼파리미터 튜닝)
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 갯수 찾기
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2):
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
임의 값으로 예측하기
🎈 길이 50으로 무게 예측하기
pred = knr.predict([[50]])
pred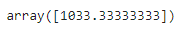
🎈 사용된 이웃의 인덱스 확인
dist, indexes = knr.kneighbors([[50]])
indexes
🎈 산점도 그리기 (이웃포함)
plt.scatter(train_input, train_target, c="blue", label="bream")
plt.scatter(50, pred[0], marker='^', c="green", label="pred")
plt.scatter(train_input[indexes], train_target[indexes], c="red", label="test")
plt.xlabel("length")
plt.ylabel("weight")
plt.legend()
plt.show()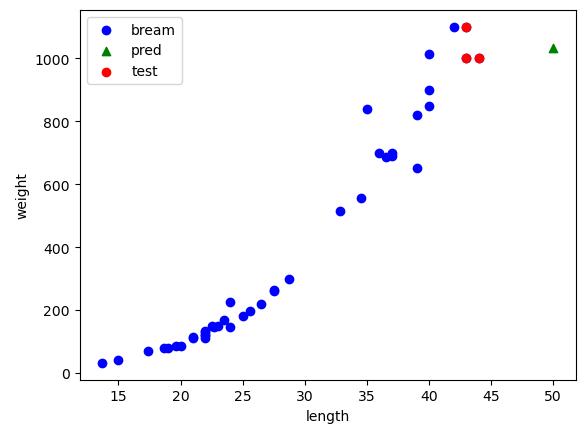
🎈 길이 100으로 무게 예측하기
pred = knr.predict([[100]])
pred
🎈 사용된 이웃의 인덱스 확인
dist, indexes = knr.kneighbors([[50]])
indexes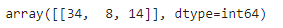
🎈 산점도 그리기 (이웃포함)
plt.scatter(train_input, train_target, c="blue", label="bream")
plt.scatter(100, pred[0], marker='^', c="green", label="pred")
plt.scatter(train_input[indexes], train_target[indexes], c="red", label="test")
plt.xlabel("length")
plt.ylabel("weight")
plt.legend()
plt.show()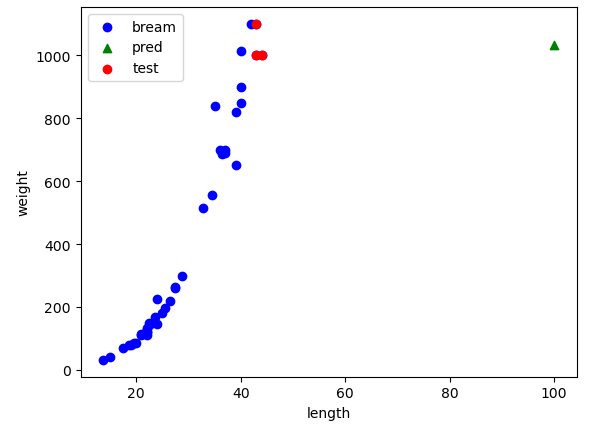
💧KNN의 한계
가장 가까운 이웃을 이용해서 예측을 수행하는 모델이기에, 예측하고자 하는 독립변수의 값이 기존 훈련데이터의 독립변수가 가지고 있는 범위를 벗어나는 경우에는 값이 항상 동일하게 나옴(가까운 거리의 이웃이 항상 동일해짐)
따라서, 다른 회귀모델을 사용해야 함.
🎈 회귀모델 종류
- 선형회귀모델(직선 한개), 다항회귀모델(곡선), 다중회귀모델(직선 여러개), 릿지, 라쏘 : 회귀에서만 사용
- 랜덤포레스트, 그레디언트부스트, 히스토그램그래디언트부스트, XGBoost, 기타 등등 : 회귀 또는 분류 모두 사용 가능
- 주로 많이 사용되는 회귀모델 : 릿지, 히스토그램그래디언트부스트, XGBoost
'Digital Boot > 인공지능' 카테고리의 다른 글
| [인공지능][ML] Machine Learning - 분류모델 / 앙상블모델 / 배깅 / 부스팅 / 랜덤포레스트 (0) | 2023.12.26 |
|---|---|
| [인공지능][ML] Machine Learning - 선형회귀모델 / 다항회귀모델 / 다중회귀모델 (0) | 2023.12.21 |
| [인공지능][ML] Machine Learning - 훈련 및 테스트 데이터 분류하기 / 정규화 (3) | 2023.12.20 |
| [인공지능][ML] Machine Learning - K최근접이웃모델 / KNN (5) | 2023.12.20 |
| [인공지능] Machine Learning - 개요 / 실습 (3) | 2023.12.19 |