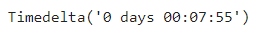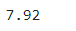728x90
반응형
데이터 처리 시각화 (2)
[Data Wrangling] 데이터 처리 시각화
데이터 처리 시각화 🍀 포항시 버스데이터 수집 가공 시각화 URL : 국가교통 데이터 오픈마켓 데이터 명 : 포항시 BIS 교통카드 사용내역 🍀 메타 정의서 샘플링 🍀 1 건 샘플링하기 여러개의 파
mzero.tistory.com
[Data Wrangling] 데이터 처리 시각화 (1) 글에 이어서 진행
전체 파일 통합하기
- 1건 샘플링 프로세스를 이용하여 전체 파일 통합하기
- 최종 통합 데이더프레임 이름 : df_bus_card_tot
from datetime import datetime
## 통합 시작 시간
start_date = datetime.today().strftime("%Y-%m-%d %H:%M:%S")
### 최종 통합 데이터프레임 이름 : df_bus_card_tot
df_bus_card_tot = pd.DataFrame()
### 0~79까지 폴더에 접근하기 위한 반복 수행
for i in range(0, 80, 1) :
file_path = f"./01_data/org/trfcard({i})/trfcard.csv"
df_bus_card_org = pd.read_csv(file_path)
# 갯수 잘 반복했는지 확인용
# print(i, " / ", len(df_bus_card_org))
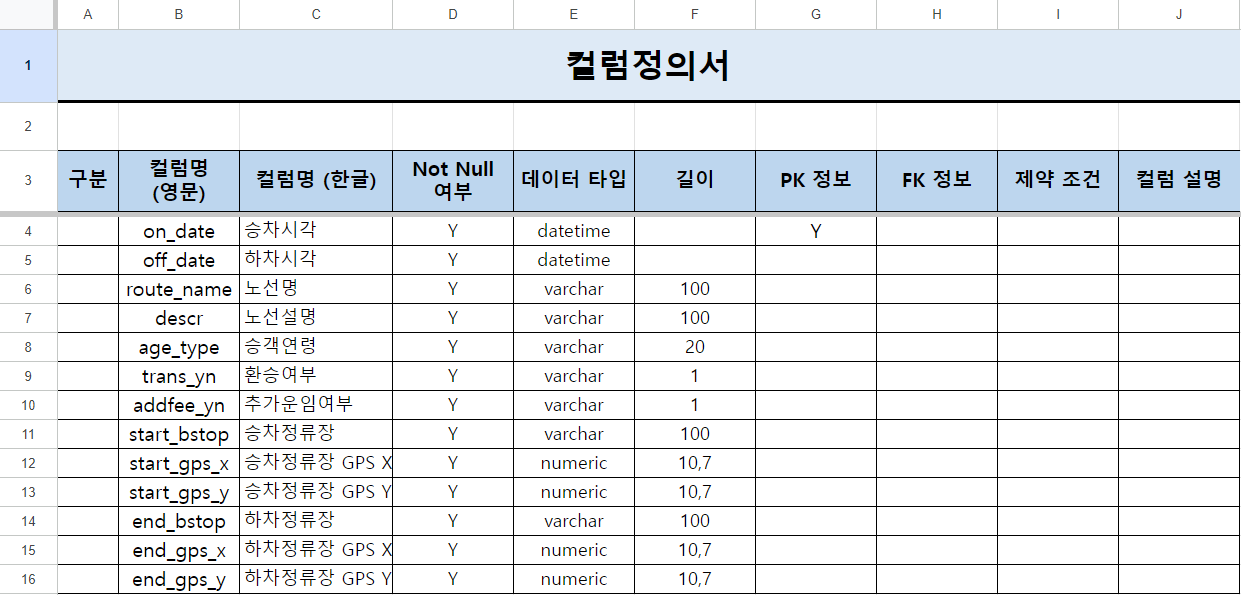
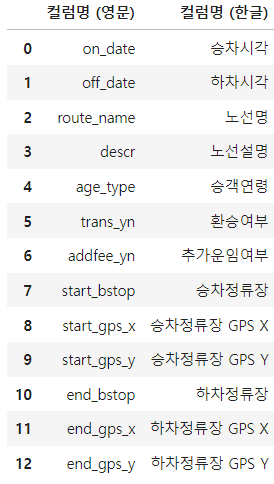
### 메타정의서의 영문명, 한글명 컬럼 읽어들이기
# - 데이터프레임 이름 : df_bus_cart_col_org
file_path = f'./01_data/org/trfcard({i})/trfcard_columns.xlsx'
df_bus_card_col_org = pd.read_excel(file_path,
header=2,
usecols="B:C")
# print(i, " / ", len(df_bus_card_col_org))
#방법 3
df_bus_card_col_new_dict = {}
for k, v in zip(df_bus_card_col_org.iloc[:, 0], df_bus_card_col_org.iloc[:, 1]):
df_bus_card_col_new_dict[k] = v
### 컬럼명 변경하기
# - inplace=True : 변경사항을 메모리에 반영하기
df_bus_card_org.rename(columns=df_bus_card_col_new_dict, inplace = True)
### 데이터프레임 복제하기
df_bus_card_kor = df_bus_card_org.copy()
### 1. 승차시각과 하차지각 데이터 타입을 문자열로 변환하기
# - astype() : 데이터 형변환 함수
df_bus_card_kor = df_bus_card_kor.astype({'승차시각':'str', '하차시각':'str'})
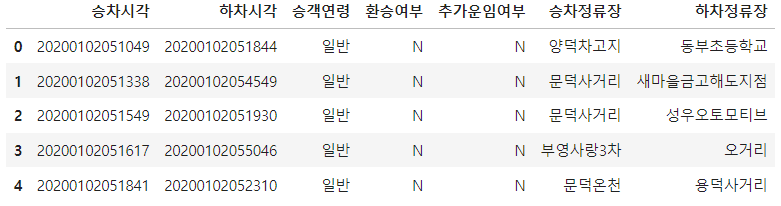
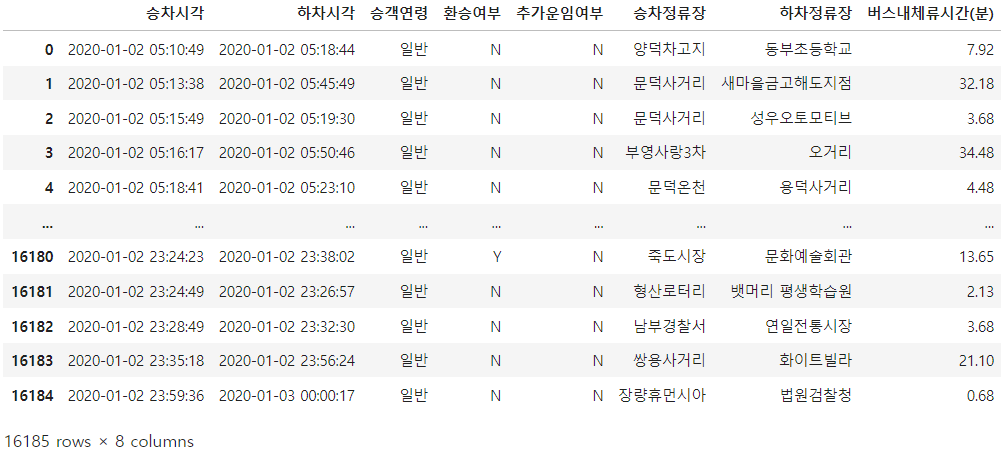
df_bus_card = df_bus_card_kor[["승차시각","하차시각","승객연령","환승여부",
"추가운임여부","승차정류장","하차정류장"]].copy()
### 3. 승차시각과 하차시각의 데이터타입을 날짜타입으로 변경하기(문자 타입만 datetime으로 변환가능하다.)
df_bus_card["승차시각"] = pd.to_datetime(df_bus_card_kor.loc[:,"승차시각"])
df_bus_card["하차시각"] = pd.to_datetime(df_bus_card_kor.loc[:,"하차시각"])
### 체류시간(분) 계산 및 컬럼 생성
df_bus_card["버스내체류시간(분)"] = round((df_bus_card["하차시각"] - \
df_bus_card["승차시각"]).dt.total_seconds()/60, 2)
### 5. 기준년도, 기준월, 기준일, 기준시간, 기준시간(분), 컬럼 생성하기
# - 기준년도
df_bus_card["기준년도"] = df_bus_card["승차시각"].dt.year
# - 기준월
df_bus_card["기준월"] = df_bus_card["승차시각"].dt.month
# - 기준일
df_bus_card["기준일"] = df_bus_card["승차시각"].dt.day
# - 기준시간
df_bus_card["기준시간"] = df_bus_card["승차시각"].dt.hour
# - 기준시간(분)
df_bus_card["기준시간(분)"] = df_bus_card["승차시각"].dt.minute
#print(f"{i} / {len(df_bus_card)}")
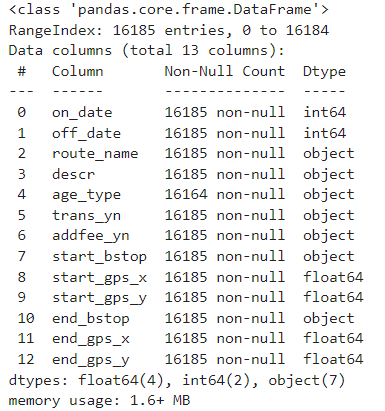
df_bus_card_tot = pd.concat([df_bus_card_tot, df_bus_card], axis=0, ignore_index=True)
## 통합 종료 시간
end_date = datetime.today().strftime("%Y-%m-%d %H:%M:%S")
print(f"전체 실행 시간 ==> {start_date} ~ {end_date}")
print(f" df_bus_card_tot ==> {len(df_bus_card_tot)}")
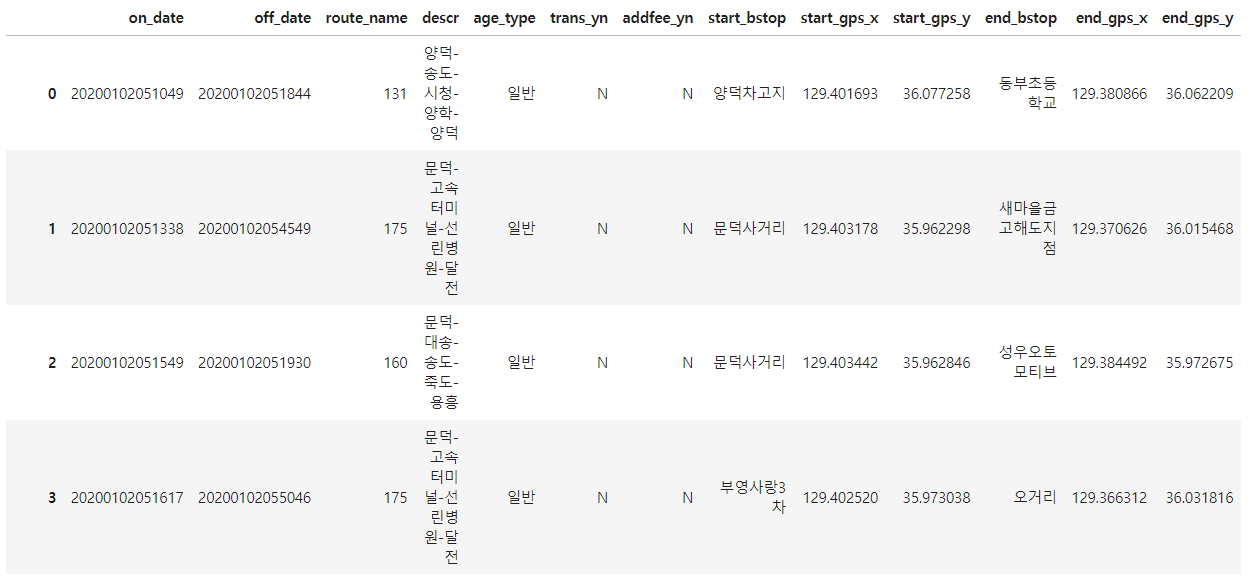
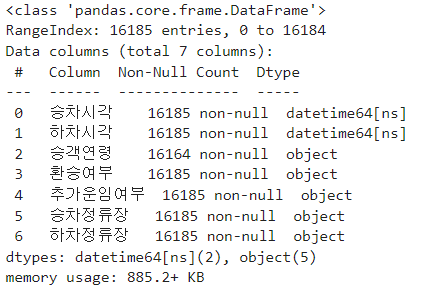
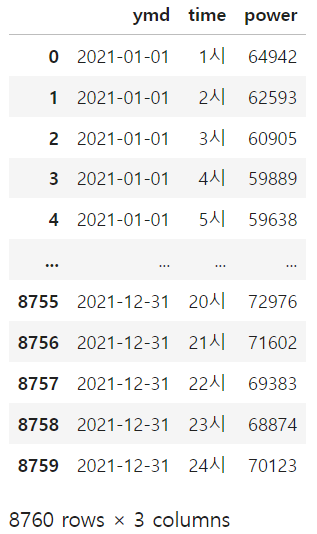
df_bus_card_tot
통합 데이터프레임 저장시키기
- 저장 파일 위치 : all 폴더
- 저장 파일 명 : 데이터프레임 변수명과 동일
- 확장자 : csv
save_path = "./01_data/all/df_bus_card_tot.csv"
df_bus_card_tot.to_csv(save_path, index = False)

728x90
반응형
'Digital Boot > Database' 카테고리의 다른 글
| [데이터수집][Crawling] 웹 크롤링을 이용한 영화 데이터수집 (1) | 2023.12.04 |
|---|---|
| [Data Wrangling] 데이터 전처리 시각화 - 히트맵 / 막대그래프 / histplot / 선그래프 (1) | 2023.11.30 |
| [Data Wrangling] 데이터 처리 시각화 (1) (1) | 2023.11.29 |
| [Data Wrangling] 데이터베이스 프로그램 실습 (1) | 2023.11.29 |
| [Data Wrangling] 데이터베이스 프로그램 (2) | 2023.11.29 |