데이터 분석 기법의 이해
1. 데이터 처리 과정
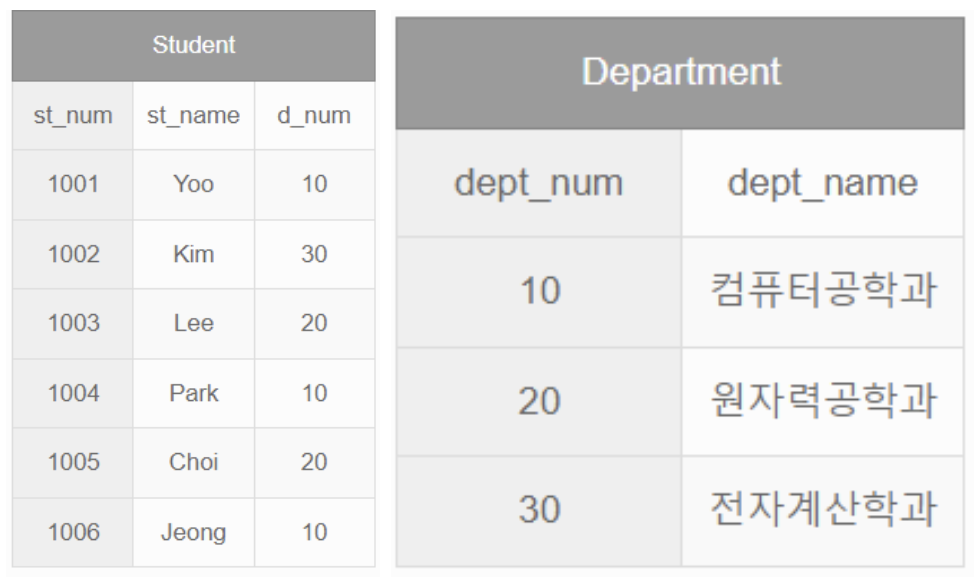
# 데이터 분석을 위해서는 데이터 웨어하우스(DW)나 데이터 마트(DM)을 통해 분석 데이터를 구성
# 신규데이터나 DW에 없는 데이터는 기존 운영시스템(Legacy)에서 직접 가져오거나 운영데이터저장소(ODS)에서 정제된 데이터를 가져와서 DW의 데이터에 결합하여 사용
2. 시각화 기법
# 가장 낮은 수준의 분석이지만 잘 사용하면 복잡한 분석보다 더 효율적이며 대용량 데이터를 다룰 때와 탐색적 분석을 할 때 시각화는 필수
3. 공간분석
# 공간적 차원과 관련된 속성들을 시각화하는 분석으로 지도 뒤에 관련된 속성들을 생성하고 크기모양, 선 굵기 등을 구분하여 인사이트를 얻음
3. 탐색적 자료분석(EDA)
# 다양한 차원과 값을 조합해 가며 특이점이나 의미있는 사실을 도출하고 분석의 최종목적을 달성해 가는 과정
# EDA의 4가지 주제: 저항성 강조, 잔차 계산, 자료변수의 재표현, 그래프를 통한 현시성
4. 통계분석
# 어떤 현상을 종합적으로 한눈에 알아보기 쉽게 일정한 체계에 따라 숫자와 표, 그림의 형태로 나타내는 것
5. 데이터 마이닝
# 대용량의 자료로부터 정보를 요약하고 미래에 대한 예측을 목표로 자료에 존재하는 관계, 패턴, 규칙 등을 탐색하고 이를 모형화함으로써 이전에 알지 못한 유용한 지식을 추출하는 분석 방법
# 방법론: 기계학습(인공신경망, 의사결정나무, 클러스터링, SVM), 패턴인식(연관규칙, 장바구니분석) 등
R소개
1. R의 탄생
# R은 오픈 소스 프로그램으로 통계/데이터 마이닝과 그래프를 위한 언어이다.
# 다양한 최신 통계분석과 마이닝 기능을 제공하며, 5000개에 이르는 패키지가 수시로 업데이트 된다.
2. 변수 다루기
# R에서는 변수명만 선언한 값을 할당하면 자료형태를 스스로 인식하고 선언함
# 화면에 프린트하고자 할 때, print()를 사용해도 되지만 변숫값만 표현해도 내용을 출력함
# 변수에 값을 할당할 때는 대입연산자(<-, <<-, =, ->, ->>)를 사용할 수 있으나 <-를 추천함
# 메모리에 불필요한 변수가 있는지 확인하기 위해서는 Is()를 활용하고 삭제는 rm()을 활용함
3. 기본적인 통계량 계산
# 평균: mean()
# 표준편차: sd()
# 공분산: cov()
# 중앙값: median()
# 분산: var()
# 상관계수: cor()
4. 외부 파일 입력과 출력
# 고정자리 변수 파일: read.fwf("파일명", width=c(w1, w2,...))
# 구분자 변수 파일: read.table("파일명", sep="구분자")
# csv 파일 읽기: read.csv("파일명", header=T) ***1행이 변수인 경우: header=T
# csv 파일 출력: write.csv(데이터 프레임, "파일명")
데이터 구조와 데이터 프레임
1. 데이터 구조의 정의
| 특징 |
벡터 |
리스트 |
데이터프레임 |
| 원소자료형 |
동질적 |
이질적 |
이질적 |
| 원소를 위치로 인덱싱 |
가능 |
가능 |
가능 |
| 인덱싱으로 여러 개 원소로 구성된 하위 데이터 생성 |
가능 |
가능 |
가능 |
| 원소들에 이름 부여 |
가능 |
가능 |
가능 |
2. 문자열 다루기
| 문자열 길이 |
nchar("문자열") |
| 벡터의 길이 |
length(vec) |
| 문자열 연결하기 |
paste("단어", "문장", scalar) |
| 하위 문자열 추출하기 |
substr("문자열", 시작번호, 끝번호) |
| 구분자로 문자열 추출하기 |
strsplit("문자열", 구분자) |
| 문자열 대체하기 |
sub("대상문자열", "변경문자열", s)
gsub("대상문자열", "변경문자열", s) |
3. 날짜 다루기
# 문자열 → 날짜 : as.Date("2014-12-25")
as.Date("12/25/2014", format="%m/%d/%y")
# 날짜 → 문자열 : format(Sys.Date(), format = "%m/%d/%Y")
# format 인자값
| R 표현 |
표시 형태 |
R 표현 |
표시 형태 |
| %b |
축약된 월 이름("Jan") |
%B |
전체 월 이름("January") |
| %d |
두 자리 숫자로 된 일("31") |
%m |
두 자리 숫자로 된 월("12") |
| %y |
두 자리 숫자로 된 년("14") |
%Y |
네 자리 숫자로 된 년("2014") |
데이터 변경 및 요약
1. 데이터 마트
-데이터 웨어하우스와 사용자 사이의 중간층에 위치한 것으로, 하나의 주제 또는 하나의 부서 중심의 데이터 웨어하우스라고 할 수 있음
2. 요약변수와 파생변수
| |
요약변수 |
파생변수 |
| 정의 |
-수집된 정보를 분석에 맞게 종합한 변수로 데이터 마트에서 가장 기본적인 변수
-많은 모델이 공통으로 사용할 수 있어 재활용성 높음 |
-사용자(분석가)가 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여한 변수
-매우 주관적일 수 있으므로 논리적 타당성을 갖출 필요가 있음 |
| 예시 |
기간별 구매 금액, 횟수, 여부 / 위클리 쇼퍼 / 상품별 구매 금액, 횟수, 여부 / 상품별 구매 순서 / 유통 채널별 구매 금액 / 단어 빈도 / 초기 행동변수 / 트랜드 변수 / 결측값과 이상값 처리 / 연속형 변수의 구간화 |
근무시간 구매지수 / 주 구매 매장 변수 / 주 활동 지역변수 / 주 구매 상품 변수 / 구매상품 다양성 변수 / 선호하는 가격대 변수 /시즌 선호 고객 변수 / 라이프 스테이지 변수 / 라이프스타일 변수 / 휴면가망 변수 / 최대가치 변수 / 최적 통화시간 등 |
3. reshape 패키지
-2개의 핵심적인 함수로 구성
# melt(): 쉬운 casting을 위해 데이터를 적당한 형태로 만들어주는 함수
# cast(): 데이터를 원하는 형태로 계산 또는 변형시켜 주는 함수
-변수를 조합해 변수명을 만들고 변수들을 시간, 상품의 차원에 결합해 다양한 요약변수와 파생변수를 쉽게 생성하여 데이터 마트를 구성할 수 있게 해주는 패키지임
4. sqldf 패키지
-R에서 sql 명령어를 사용 가능하게 해주는 패키지로 SAS의 proc sql과 같은 기능
-head([df]) → sqldf("select * from [df] limit 6")
-subset([df], [col] %in% c("BF", "HF")) → sqldf("select * from [df] where [col] in('BF', 'HF')")
-merge([df1],[df2]) → sqldf("select * from [df1], [df2]")
5. plyr 패키지
-apply 함수를 기반으로 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
-split-apply-combine 방식으로 데이터를 분리하고 처리한 다음, 당시 결합하는 등 필수적인 데이터 처리 기능 제공
6. data.table
-R에서 가장 많이 사용하는 데이터 핸들링 패키지 중 하나로 대용량 데이터의 탐색, 연산, 병합에 유용
-기존 data.frame 방식보다 월등히 빠른 속도
-특정 column을 key 값으로 색인을 지정한 후 데이터 처리
-빠른 grouping과 ordering, 짧은 문장 지원 측면에서 데이터프레임 보다 유용함
데이터 가공
1. 변수의 구간화
-신용평가모형, 고객 세분화 등의 시스템으로 모형을 제공하기 위해서 각 변수들을 구간화하여 점수를 적용하는 방식 활용
-변수의 구간화를 위한 rule이 존재함 (※ 10진수 단위로 구간화하고, 구간을 5개로 나누는 것이 보통이며, 7개 이상의 구간을 잘 만들지 않음)
2. 변수 구간화의 방법
-Binning: 연속형 변수를 범주형 변수로 변환하기 위해 50개 이하의 구간에 동일한 수 의 데이터를 할당하여 의미를 파악하면서 구간을 축소하는 방법
-의사결정나무: 모형을 통해 연속형 범수를 범주형 변수로 변환하는 방법
기초 분석 및 데이터 관리
1. 결측값 처리
-변수에 데이터가 비어 있는 경우
# NA, ., 99999999, Unknown, Not Answer 등으로 표현
-단순 대치법(Single Imputation)
# Complets Analysis: 결측값의 레코드를 삭제
# 평균대치법: 관측 및 실험을 통해 얻어진 데이터의 평균으로 대치
▶ 비조건부 평균 대치법: 관측 데이터의 평균으로 대치
▶ 조건부 평균 대치법: 회귀분석을 통해 데이터를 대치
# 단순 확률 대치법: 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보안한 방법으로 Hot-Deck 방법, Nearest Neighbor 방법이 있음
-다중 대치법(Multiple Imputation)
# 단순 대치법을 m번 실시하여, m개의 가상적 자료를 만들어 대치하는 방법
2. R의 결측값 처리 관련 함수
-complete.cases(): 데이터 내 레코드에 결측값이 있으면 FALSE, 없으면 TRUE 반환
-is.na(): 결측값이 NA인지의 여부를 TRUE/FALSE로 반환
-DMwR 패키지
# centralInputation(): NA 값을 가운데 값(Central Value)으로 대치 (숫자-중위수, Factor-최빈)
# knnImputation(): NA 값을 k최근 이웃 분류 알고리즘을 사용하여 대치 (k개 주변 이웃까지의 거리를 고려하여 가중 평균한 값을 사용)
-Amelia 패키지
# amelia(): time-series-cross-sectional data set(여러 국가에서 매년 측정된 자료)에서 활용
3. 이상값 처리
-이상값
# 의도하지 않은 현상으로 입력된 값 or 의도된 극단값 → 활용할 수 있음
# 잘못 입력된 값 or 의도하지 않은 현상으로 입력된 값이지만 분석 목적에 부합되지 않는 값 → Bad Data이므로 제거
-이상값의 인식
# ESD(Extreme Studentized Deviation): 평균으로부터 3 표준편차 떨어진 값
# 기하평균 - 2.5 * 표준편차 < data < 기하평균 + 2.5 * 표준편차
# Q1 - 1.5 *IQR < data < Q3 + 1.5 * IQR을 벗어나는 데이터 (IQR = Q3 - Q1)
-이상값의 처리
# 절단(Trimming): 이상값이 포함된 레코드를 삭제
# 조정(Winsorizing): 이상값을 상한 또는 하한값으로 조정
통계분석의 이해
1. 통계
| 통계 |
특정집단을 대상으로 수행한 조사나 실험을 통해 나온 결과에 대한 요약된 형태의 표현 |
| 통계자료의 획득 방법 |
총 조사(Census)와 표본조사(Sampling) |
| 표본 추출 방법 |
단순랜덤추출(Simple Random Sampling), 계통추출법(Systematic Sampling),
집락추출법(Cluster Sampling), 층화추출법(Stratified Random Sampling) |
| 자료의 측정 방법 |
명목척도, 순서척도, 구간척도, 비율척도 |
2. 통계분석
| 기술통계(Descriptive statistic) |
평균, 표준편차, 중위수, 최빈값, 그래프 |
| 통계적 추론(Statistical inference) |
모수추정, 가설검정, 예측 |
3. 확률 및 확률 분포
| 확률변수(Random Variable) |
특정 값이 나타날 가능성이 확률적으로 주어지는 변수 |
| 이산형 확률분포(Discrete Distribution) |
베르누이분포, 이항분포, 기하분포, 다항분포, 포아송분포 |
| 연속형 확률분포(Continuous Distribution) |
균일분포, 정규분포, 지수분포, t분포, f분포, x^2분포 |
4. 추정 및 가설검정
| 추정 |
표본으로부터 미지의 모수를 추측하는 것 |
점추정
(Point Estimation) |
'모수가 특정한 값일 것'이라고 추정하는 것
평균, 표준편차, 중앙값 등을 추정
점추정 조건: 불편성(Unbiasedness), 효율성(Efficiency), 일치성(Consistency), 충족성(Sufficient) |
구간추정
(Interval Estimation) |
점추정을 보완하기 위해 모수가 특정 구간에 있을 것이라고 추정하는 것. 모분산을 알거나 대표본의 경우 표준정규분포 활용, 모분산을 모르거나 소표본의 경우 t분포 활용 |
-가설검정: 모집단에 대한 가설을 설정한 뒤, 그 가설을 채택여부를 결정하는 방법
# 귀무가설(Null Hypothesis, H0) vs 대립가설(Alternative Hypothesis, H1)
# 1종 오류(Type 1 Error): 귀무가설 H0가 옳은데도 귀무가설을 기각하게 되는 오류
# 2종 오류(Type 2 Error): 귀무가설 H0가 옳지 않은데도 귀무가설을 채택하게 되는 오류
| |
가설검정결과 |
| H0가 사실이라고 판정 |
H0가 사실이 아니라고 판정 |
| 정확한 사실 |
H0가 사실임 |
옳은 결정 |
제 1종 오류( α ) |
| H0가 사실이 아님 |
제 2종 오류( β ) |
옳은 결정 |
# 1종 오류의 크기를 0.1, 0.05, 0.01로 고정시키고 2종 오류가 최소가 되도록 기각역을 설정
5. 비모수 검정
-비모수 검정: 모집단의 분포에 대한 아무 제약을 가하지 않고 검정을 실시
-가설 설정 방법: '분포의 형태가 동일하다', '분포의 형태가 동일하지 않다'라는 식으로 가설을 설정
-검정 방법: 순위나 두 관측값 차이의 부호를 이해 검정
# 예: 부호검정(Sign Test), 윌콕슨의 순위합 검정(Wilcoxon's Rank Sum Test), 윌콕슨의 부호 순위 검정(Wilcoxon's Signed Rank Test), 맨-휘트니의 U검정(Mann–Whitney U Test), 스피어만의 순위상관계수(Spearman's rank correlation analysis)
기초 통계 분석
1. 기술 통계
-기술 통계(Descriptive Statistic): 자료의 특성을 표, 그림, 통계량 등을 사용해 쉽게 파악할 수 있도록 정리/요약하는 것
# 통계량에 의한 자료 정리
▶중심 위치의 측도: 평균, 중앙값, 최빈값
▶산포의 측도: 분산, 표준편차, 범위, 사분위수범위, 변동계수, 표준오차
▶분포의 형태: 왜도, 첨도
# 그래프를 통한 자료 정리
▶범주형 자료: 막대그래프, 파이차트, 모자이크 플랏 등
▶연속형 자료: 히스토그램, 줄기-잎 그림, 상자그림
2. 인과관계의 이해
-용어
# 용어
▶종속변수(반응변수, y), 독립변수(설명변수, x), 산점도(Scatter Plot)
▶산점도에서 확인할 수 있는 것
두 변수 사이의 선형관계가 성립하는가?
두 변수 사이의 함수관계가 성립하는가?
이상값의 존재 여부와 몇 개의 집단으로 구분되는지를 확인
# 공분산(Covariance)
▶두 변수 간의 상관 정도를 상관계수를 통해 확인할 수 있음
▶ (Cov(X, Y) = E[(Xᵢ - μₓ) (Yᵢ - μᵧ)]
3. 상관분석(Correlation Analysis)
-정의와 특성
# 상관분석: 두 변수간의 관계를 상관계수를 이용하여 알아보는 분석 방법
# 상관계수가 1에 가까울수록 강한 양의 상관관계, 상관계수가 -1에 가까울수록 강한 음이 상관관계를 가짐
# 상관계수가 0인 경우 데이터 간의 상관이 없음
-유형
| 구분 |
피어슨 |
스피어만 |
| 개념 |
등간척도 이상으로 측정된 두 변수의 상관관계 측정 |
순서, 서열 척도인 두 변수들 간의 상관관계를 측정 |
| 특징 |
연속형 변수, 정규성 가정 |
순서형 변수, 비모수적 방법 |
| 상관계수 |
적률상관계수 r |
순위상관계수 p |
| R코드 |
cor(x, y, method=c("person", "kendall", "spearman")) |
회귀분석
1. 회귀분석의 개요
-정의
# 하나 또는 그 이상의 독립 변수들이 종속 변수에 미치는 영향을 추정할 수 있는 통계 기법
# 독립 변수가 1개: 단순선형회귀분석, 독립 변수가 2개 이상: 다중선형회귀분석
# 최소제곱법: 측정값을 기초로 제곱합을 만들고 그것의 최소인 값을 구하여 처리하는 방법, 잔차제곱합이 가장 작은 선을 선택
-회귀분석의 검정
# 회귀식(모형)에 대한 검증: F-검증
# 회귀계수들에 대한 검증: T-검증
# 모형의 설명력은 결정계수(R^2)로 알 수 있으며 구하는 식은 R^2=회귀제곱합/전체제곱합=SSR/SST
# 단순회귀분석의 결정계수는 상관계수 값의 제곱과 같음
-선형회귀분석
#가정
| 선형성 |
입력변수와 출력변수의 관계가 선형 |
| 독립성 |
잔차와 독립변인은 관련이 없음 |
| 등분산성 |
독립변인의 모든 값에 대한 오차들의 분산이 일정 |
| 비상관성 |
관측치들의 잔차들끼리 상관이 없어야 함 |
| 정상성(정규성) |
잔차항이 정규분포를 이뤄야 함 |
# 다중선형회귀분석의 다중공선성(Multicolinearity)
▶다중회귀분석에서 설명변수들 사이에 강한 선형관계가 존재하면 회귀계수의 정확한 추정이 곤란
# 다중공선성 검사 방법
▶분산팽창요인(VIF): 10보다 크면 심각한 문제
▶상태지수: 10 이상이면 문제가 있다고 보고, 30보다 크면 심각, 선형관계가 강한 변수는 제거
-회귀분석의 종류: 단순회귀, 다중회귀, 로지스틱회귀, 다항회귀, 곡선회귀, 비선형회귀
-변수선택법(Variable Selection)
# 모든 가능한 조합: 모든 가능한 독립변수들의 조합에 대한 회귀모형을 분석해 가장 적합한 모형 선택
전진선택법
(Forward Selection) |
절편만 있는 상수모형으로부터 시작해 중요하다고 생각되는 설명변수부터 차례로 모형에 추가
→ 이해 쉬움, 많은 변수에서 활용가능, 변수 값의 작은 변동에 결과가 달라져 안정성이 부족 |
후진제거법
(Backward Selection) |
독립변수 후보 모두를 포함한 모형에서 가장 적은 영향을 주는 변수부터 하나씩 제거
→ 전체 변수들의 정보를 이용 가능, 변수가 많은 경우 활용이 어려움, 안정성 부족 |
단계별방법
(Stepwise Method) |
전진선택법에 의해 변수를 추가하면서 새롭게 추가된 변수에 기인해 기존 변수가 그 중요도가 약화되면 해당 변수를 제거하는 등 단계별로 추가 또는 삭제되는 변수를 검토해 더 이상 없을때 중단 |
시계열 분석
1. 시계열 자료
-개요
# 시계열 자료(Time Series): 시간의 흐름에 따라 관찰된 값들
# 시계열 데이터의 분석 목적: 미래의 값을 예측, 특성 파악(경향, 주기, 계절성, 불규칙성 등)
-정상성 (3가지를 모두 만족)
# 평균이 일정(모든 시점에서 일정한 평균을 가짐)
# 분산도 일정
# 공분산도 특정시점에서 t, s에 의존하지 않고 일정
-시계열 모형
# 자기회귀모형(AR, Autoregressive Model): p 시점 전의 자료가 현재 자료에 영향을 주는 모형
# 이동평균모형(MA, Moving Average Model): 같은 시점의 백색잡음과 바로 전 시점의 백색잡음의 결합으로 이뤄진 모형
#자기회귀누적이동평균모형(ARIMA(p,d,q))
▶d(차분) = 0 이면 정상성 만족, p=0 이면 d번 차분한 MA(q) 모델, q=0이면 d번 차분한 AR(p) 모델
-분해 시계열
# 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
▶추세요인(Trend Factor): 형태가 오르거나 또는 내리는 추세, 선형, 이차식, 지수형태
▶계절요인(Seasonal Factor): 요일, 월, 사분기 별로 변화하여 고정된 주기에 따라 자료가 변화
▶순환요인(Cyclical Factor): 명백한 경제적, 자연적 이유 없이 알려지지 않은 주기로 자료가 변화
▶불규칙요인(Irregular Factor): 위 세 가지의 요인으로 설명할 수 없는 회귀분석에서 오차에 해당하는 요인
다차원 척도법과 주성분분석
1. 다차원 척도법
-정의 및 목적
# 군집분석과 같이 개체들을 대상으로 변수들을 측정한 후, 개체들 사이의 유사성/비유사성을 측정하여 개체들을 2차원 또는 3차원 공간 상에서 점으로 표현하는 분석방법
# 목적: 개체들의 비유사성을 이용하여 2차원 공간상에 점으로 표시하고 개체들 사이의 집단화를 시각적으로 표현
-방법
# 개체들의 거리 계산은 유클리드 거리행렬을 활용
# d(x, y) = √(x₂ - x₁)² + (y₂ - y₁)²
# STRESS: 개체들을 공간상에 표현하기 위한 방법으로 STRESS나 S-STRESS를 부적합도 기준으로 사용
▶최적모형의 적합은 부적합도를 최소로 하는 방법으로 일정 수준 이하로 될 때까지 반복해서 수행
-종류
계량적 MDS
(Metric MDS) |
-데이터가 구간척도나 비율척도인 경우 활용(전통적인 다차원척도법)
-N개의 케이스에 대해 p개의 특성변수가 있는 경우, 각 개체들 간의 유클리드 거리행렬을 계산하고 개체들 간의 비유사성 S(거리제곱 행렬의 선형함수)를 공간상에 표현 |
비계량적 MDS
(Nonmetric MDS) |
-데이터가 순서척도인 경우 활용
-개체들 간의 거리가 순서로 주어진 경우에는 순서척도를 거리의 속성과 같도록 변환(Monotone Transformation)하여 거리를 생성한 후 적용 |
2. 주성분분석
-정의 및 목적
# 상관관계가 있는 변수들을 결합해 상관관계가 없는 변수로 분산을 극대화하는 분석으로, 선형결합으로 변수를 축약, 축소하는 기법
# 목적: 여러 변수들을 소수의 주성분으로 축소하여 데이터를 쉽게 이해하고 관리. 주성분분석을 통해 차원을 축소하여 군집분석에서 군집화 결과와 연산 속도 개선, 회귀분석에서 다중 공선성을 최소화
-주성분분석 vs 요인분석
# 요인분석(Factor Analysis): 등간척도(혹은 비율척도)로 두 개 이상의 변수들에게 잠재되어 있는 공통 인자를 찾아내는 기법
# 공통점: 모두 데이터를 축소하는데 활용, 몇 개의 새로운 변수들로 축소
| 차이점 |
생성된 변수의 수와 이름 |
생성된 변수들 간의 관계 |
목표변수와의 관계 |
| 요인분석 |
몇 개로 지정할 수 없으나, 이름을 붙일 수 있음 |
생성된 변수들이 기본적으로 대등한 관계 |
목표변수를 고려하지 않고 주어진 변수들간 비슷한 성격들을 묶음 |
| 주성분분석 |
제 1주성분, 제 2주성분을 생성(보통 2개), 이름은 제 1주성붙과 같이 정해짐 |
제 1주성분, 제 2주성분 순으로 중요함 |
목표변수를 고려하여 주성분 변수 생성 |
-주성분의 선택법
# 누적기여율(Cumulative Proportion)이 85% 이상이면 주성분의 수로 결정할 수 있음
# Screen Plot에서 고윳값(Eigen Value)이 수평을 유지하기 전 단계로 주성분의 수를 선택
데이터 마이닝의 개요
1. 데이터 마이닝
-개요
# 정의: 대용량 데이터에서 의미 있는 패턴을 파악하거나 예측하여 의사결정에 활용하는 방법
# 통계분석과 차이점: 가설이나 가정에 따른 분석, 검증을 하는 통계분석과 달리 데이터마이닝은 다양한 수리 알고리즘을 이용해 데이터베이스의 데이터로부터 의미있는 정보를 추출
# 활용분야: 분류, 예측, 군집화, 시각화 등
# 방법론: 의사결정나무, 로지스틱 회귀분석, 최근접 이웃법, 군집분석, 연관규칙 분석 등
-분석 방법
| 지도학습 |
비지도 학습 |
-의사결정나무(Decision Tree)
-인공신경망(Artificial Neural Network)
-로지스틱 회귀분석(Logistic Regression)
-최근접 이웃법(k-Nearest Neighbor)
-사례기반 추론(Case-Based Reasoning) |
-OLAP(On-Line Analytic Processing)
-연관 규칙 분석(Association Rule Analysis)
-군집분석(k-Means Clustering)
-SOM(Self Organizing Map) |
-데이터 마이닝 추진단계
| 1. 목적설정 |
데이터 마이닝을 위한 명확한 목적 설정 |
| 2. 데이터 준비 |
모델링을 위한 다양한 데이터을 준비, 데이터 정제를 통해 품질을 보장 |
| 3. 데이터 가공 |
목적변수 정의, 모델링을 위한 데이터 형식으로 가공 |
| 4. 기법 적용 |
데이터 마이닝 기법을 적용하여 정보를 추출 |
| 5. 검증 |
마이닝으로 추출한 결과를 검정하고 업무에 적용해 기대효과를 전파 |
-데이터 분할
# 구축용(Training Data): 50%의 데이터를 모델링을 위한 훈련용으로 활용
# 검증용(Validation Data): 30%의 데이터를 구축된 모형의 과대/과소 추정의 판정 목적으로 활용
# 시험용(Test Data): 20%의 데이터를 테스트 데이터나 과거 데이터로 활용하여 모델의 성능 평가에 활용
분류분석
1. 분류분석과 예측분석
-개요
| 공통점 |
레코드의 특정 속성의 값을 미리 알아 맞히는 것 |
| 차이점 |
분류는 레코드의 범주형 속성의 값을 알아 맞히는 것
예측을 레코드의 연속형 속성의 값을 알아 맞히는 것 |
| 분류의 예 |
학생들의 국어, 영어 등 점수를 통해 내신등급을 예측
카드회사에서 회원들의 가입 정보를 통해 1년 후 신용등급을 예측 |
| 예측의 예 |
학생들의 여러 가지 정보를 입력해 수능점수를 예측
카드회사에서 회원들의 가입정보를 통해 연 매출액을 예측 |
| 분류 모델링 |
신용평가모형, 사기방지모형, 이탈모형, 고객세분화 |
| 분류기법 |
로지스틱 회귀분석
의사결정나무, CART
나이브 베이즈 분류
인공신경망
서포트 벡터 머신
K 최근접 이웃
규칙기반의 분류와 사례기반추론 |
2. 의사결정나무
-정의와 특징
# 분류 함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법으로, 의사결정 문제를 시각화해 의사결정이 이뤄지는 시점과 성과를 한눈에 볼 수 있게 함
# 주어진 입력값에 대해 출력값을 예측하는 모형으로 분류나무와 회귀나무 모형이 있음
# 특징
▶계산 결과가 의사결정나무에 직접 나타나게 돼 분석이 간편함
▶분류 정확도가 좋음
▶계산이 복잡하지 않아 대용량 데이터에서도 빠르게 만들 수 있음
▶비정상 잡음 데이터에 대해서도 민감함 없이 분류
▶한 변수와 상관성이 높은 다른 불필요한 변수가 있어도 크게 영향받지 않음
-활용
# 세분화(Segmentation): 데이터를 비슷한 특성을 갖는 몇 개의 그룹으로 분할해 그룹별 특성을 발견
# 분류(Classification): 관측개체를 여러 예측변수들에 근거해 목표변수의 범주를 몇개의 등급으로 분류하고자 하는 경우
# 예측(Prediction): 자료에서 규칙을 찾아내고 이를 이용해 미래의 사건을 예측하고자 하는 경우
# 차원축소 및 변수선택(Reduction, Variable Selection): 매우 많은 수의 예측변수 중 목표변수에 영향을 미치는 변수들을 골라내고자 하는 경우
# 교호작용효과의 파악(Interaction Effect Identification): 여러 개의 예측변수들을 결합해 목표 변수에 작용하여 파악하고자 하는 경우
# 범주의 병합 또는 연속형 변수의 이산화(Binning): 범주형 목표변수의 범주를 소수의 몇 개로 병합하거나 연속형 목표변수를 몇 개의 등급으로 이산화 하고자 하는 경우
-의사결정나무의 분석 과정
# 분석 단계: 성장 → 가지치기 → 타당성 평가 → 해석 및 예측
# 가지치기(Pruning): 너무 큰 나무 모형은 자료를 과대적합하고 너무 작은 나무 모형은 과소적합 할 위험이 있어 마디에 속한 자료가 일정 수 이하일 경우, 분할을 정지하고 가지치기 실시
# 불순도에 따른 분할 측도: 카이제곱 통계량, 지니지수, 엔트로피 지수
-의사결정나무 분석의 종류
# CART(Classification and RegressionTree)
▶목적변수가 범주형인 경우 지니지수, 연속형인 경우 분산을 이용해 이진분리를 사용
▶개별 입력변수뿐만 아니라 입력변수들의 선형결합들 중 최적의 분리를 찾을 수 있음
# C4.5와 C5.0
▶다지분리(Multiple Split)가 가능하고 범주형 입력 변수의 범주 수만큼 분리 가능
▶불순도의 측도로 엔트로피 지수 사용
# CHAID(Chi-Square Automatic Interaction Detection)
▶가지치기를 하지 않고 적당한 크기에서 나무모형의 성장을 중지하며 입력변수가 반드시 범주형 변수여야 함
▶불순도의 측도로 카이제곱 통계량 사용
3. 앙상블 기법
-개요
# 주어진 자료로부터 여러 개의 예측모형들을 만든 후 조합하여 하나의 최종예측모형을 만드는 방법
# 다중 모델 조합(Combining Multiple Models), Classifier Combination 방법이 있음
# 학습 방법의 불안전성을 해결하기 위해 고안된 기법
# 가장 불안정성을 가지는 기법은 의사결정나무, 가장 안정성을 가지는 기법은 1-Nearest Neighbor
-기법의 종류
배깅
(Bagging: Bootstrap
Aggregating) |
-여러 개의 붓스트랩 자료를 생성하고 각 붓스트랩 자료의 예측모형 결과를 결합하여 결과를 선정
-배깅은 훈련자료를 모집단으로 생각하고 평균 예측모형을 구한 것과 같아 분산을 줄이고 예측력을 향상시킬 수 있음 |
부스팅
(Boosting) |
-예측력이 약한 모형(Weak Learner)들을 결합하여 강한 예측모형을 만드는 방법
-훈련 오차를 빨리 그리고 쉽게 줄일 수 있고, 예측오차의 향상으로 배깅에 비해 뛰어난 예측력을 보임 |
랜덤 포레스트
(Random Forest) |
-의사결정나무의 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법
-이론적 설명이나 해석이 어렵다는 단점이 있지만 예측력이 매우 높은 장점이 있음
-입력변수가 많은 경우 더 좋은 예측력을 보임 |
4. 성과분석
-오분류표를 통한 모델 평가
| |
Condition |
|
| Positive |
Negative |
| Prediction |
Positive |
True Positive / TP |
False Positive / FP |
정밀도(Precision)
TP/(TP+FP) |
| Negative |
False Negative / FN |
True Negative /TN |
|
| |
민감도(Sensitivity)
재현율(Recall)
=TP/(TP + FN) |
특이도(Specificity)
TN/(TN + FP) |
|
# F1 Score = 2 * {(정밀도 * 재현율) / (정밀도 + 재현율)}
-ROC(Receiver Operation Characteristic)
# 민감도와 1-특이도를 활용하여 모형을 평가
# AUROC(ROC 커브 밑부분의 넓이): 1이 될수록 좋음
5. 인공신경망
-신경망의 연구
# 인공신경망은 뇌를 기반으로 한 추론 모델
# 1943년 매컬럭과 피츠: 인간의 뇌를 수많은 신경세포가 연결된 하나의 디지털 네트워크 모형으로 간주하고 신경세포의 신호처리 과정을 모형화하여 단순 패턴분류 모형을 개발
# 헵(Hebb): 신경세포(뉴런) 사이의 연결강도(Weight)를 조정하여 학습규칙 개발
# 로젠블럿(Rosenblatt, 1955): 퍼셉트론(Perceptron)이라는 인공 세포 개발, 비선형성의 한계점 발생
# 홉필드, 러멜하트, 맥클랜드: 역전파 알고리즘(Backpropagation)을 활용하여 비선형성을 극복한 다계층 퍼셉트론으로 새로운 인공신경망 모형 등장
-뉴런
# 인공신경망은 뉴런이라는 아주 단순하지만 복잡하게 연결된 프로세스로 이루어져 있음
# 뉴런은 가중치가 있는 링크들로 연결되어 있으며, 뉴런은 여러 개의 입력신호를 받아 하나의 출력신호를 생성
# 뉴런은 전이함수, 즉 활성화함수(Activation Function)를 사용
▶뉴런은 입력 신호의 가중치 합을 계산하여 임계값과 비교
▶가중치 합이 임계값보다 작으면 뉴런의 출력은 -1, 같거나 크면 +1을 출력함
6. 로지스틱 회귀분석
-개요
# 반응변수가 범주형이 경우에 적용되는 회귀분석모형
# 새로운 설명변수(또는 예측변수)가 주어질 때 반응변수의 각 범주(또는 집단)에 속할 확률이 얼마인지를 추정(예측모형)하여, 추정 확률을 기준치에 따라 분류하는 목적(분류모형)으로 활용
# 이때 모형의 적합을 통해 추정된 확률을 사후확률이라고 함
# exp(β₁)의 의미는 나머지 변수(x₁, x₂, ..., xₖ)가 주어질 때, x₁이 한 단위 증가할 때마다 성공(Y=1)의 오즈가 몇 배 증가하는지를 나타내는 값
군집분석
1. 군집분석
-개요
# 각 객체(대상)의 유사성을 측정하여 유사성이 높은 대상 집단을 분류하고, 군집에 속한 객체들의 유사성과 서로 다른 군집에 속한 객체 간의 상이성을 규명하는 분석방법
# 특성에 따라 고객을 여러 개의 배타적인 집단으로 나누는 것으로 군집의 개수, 구조에 대한 가정 없이 데이터로부터 거리 기준으로 군집화 유도
-특징
# 비지도학습법에 해당하여 타깃변수(종속변수)의 정의가 없이 학습이 가능
# 데이터를 분석의 목적에 따라 적절한 군집으로 분석자가 정의 가능
# 요인분석과의 차이: 유사한 변수를 함께 묶어주는 목적이 아니라 각 데이터(객체)를 묶어 줌
# 판별분석과의 차이: 판별분석은 사전에 집단이 나누어져 있어야 하고 군집분석은 집단이 없는 상태에서 집단을 구분
-거리 측정 방법
# 연속형 변수: 유클리드 거리, 표준화 거리, 마할라노비스 거리, 체비셔프 거리, 맨해튼 거리, 캔버라 거리, 민코우스키 거리 등
# 범주형 변수: 자카드 거리 등
-계층적 군집분석
# n개의 군집으로 시작해 점차 군집의 개수를 줄여나가는 방법
| 최단연결법 |
-n*n 거리행렬에서 거리가 가장 가까운 데이터를 묶어서 군집을 형성
-군집과 군집 또는 데이터와의 거리를 계산시 최단거리를 거리로 계산하여 거리행렬 수정
-수정된 거리행렬에서 거리가 가까운 데이터 또는 군집을 새로운 군집으로 형성 |
| 최장연결법 |
-군집과 군집 또는 데이터와의 거리를 계산시 최장거리를 거리로 계산하여 거리행렬 수정 |
| 평균연결법 |
-군집과 군집 또는 데이터와의 거리를 계산시 평균거리를 거리로 계산하여 거리행렬 수정 |
| 와드연결법 |
-군집 내 편차들의 제곱합을 고려한 방법으로 군집 간 정보의 손실을 최소화하기 위해 군집화를 진행 |
-비계층적 군집분석
# n개의 개체를 k개의 군집으로 나눌 수 있는 모든 가능한 방법을 점검해 최적화한 군집을 형성하는 것
# K-평균 군집분석(K-Means Clustering)
# 프로세스
▶ 원하는 군집의 개수와 초기 값(seed)들을 정해 seed 중심으로 군집을 형성
▶각 데이터를 거리가 가장 가까운 seed가 있는 군집으로 분류
▶각 군집의 seed 값을 다시 계산
▶모든 개체가 군집으로 할당될 때까지 위 과정들을 반복
# 장점과 단점
| 장점 |
단점 |
| 주어진 데이터의 내부구조에 대한 사정정보 없이 의미있는 자료구조를 찾을 수 있음 |
가중치와 거리 정의가 어려움 |
| 다양한 형태의 데이터에 적용이 가능함 |
초기 군집 수를 결정하기 어려움 |
| 분석방법 적용이 용이함 |
사전에 주어진 목적이 없으므로 결과 해석이 어려움 |
-혼합 분포 군집(Mixture Distribution Clustering)
# 모형 기반(Model-Based)의 군집 방법이며, 데이터가 k개의 모수적 모형(흔히 정규분포 또는 다변량 정규분포를 가정함)의 가중합으로 표현되는 모집단 모형으로부터 나왔다는 가정하에서 가중치를 자료로부터 추정하는 방법을 사용
# k개의 각 모형은 군집을 의미하며 , 각 데이터는 추정된 k개의 모형 중 어느 모형으로부터 나왔을 확률이 높은지에 따라 군집의 분류가 이루어짐
# 흔히 혼합모형에서의 모수와 가중치의 추정(최대가능도추정)에는 EM 알고리즘이 사용
# 혼합 분포 군집 모형의 특징
▶K-평균 군집의 절차와 유사하지만 확률분포를 도입하여 군집을 수행
▶군집을 몇 개의 모수로 표현할 수 있으며, 서로 다른 크기나 모양의 군집을 찾을 수 있음
▶EM 알고리즘을 이용한 모수 추정에서 데이터가 커지면 수렴에 시간이 걸림
▶군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려움
▶K-평균 군집과 같이 이상치 자료에 민감하므로 사전에 조치가 필요
-SOM(Self-Organizing Map)
# SOM(자기조직화지도) 알고리즘은 코호넨에 의해 제시, 개발되었으면 코호넨 맵이라고도 알려져 있음
# SOM은 비지도 신경망으로 고차원의 데이터를 이해하기 쉬운 저 차원의 뉴런으로 정렬하여 지도의 형태로 형상화, 이러한 형상화는 입력 변수의 위치 관계를 그대로 보존한다는 특징이 있음. 다시 말해 실제 공간의 입력 변수가 가까이 있으면, 지도 상에도 가까운 위치에 있게 됨
# SOM의 특징
▶고차원의 데이터를 저차원의 지도 형태로 형상화하기 때문에 시각적으로 이해가 쉬움
▶입력 변수의 위치 관계를 그대로 보존하기 때문에 실제 데이터가 유사하면 지도상에서 가깝게 표현되며, 이런 특징 때문에 패턴 발견, 이미지 분석 등에서 뛰어난 성능을 보임
▶역전파 알고리즘 등을 이용하는 인공신경망과 달리 단 하나의 전방 패스(Feed-Forward Flow)를 사용함으로써 속도가 매우 빠르므로 실시간 학습처를 할 수 있는 모형임
연관분석
1. 연관분석
-개요
# 기업의 데이터베이스에서 상품의 구매, 서비스 등 일련의 거래 또는 사건들 간의 규칙을 발견하기 위한 분석. 흔히 장바구니 분석, 순차분석 등이 있음
# 장바구니 분석: 장바구니에 무엇이 같이 들어 있는지에 대해 분석.
ex) 주말을 위해 목요일에 기저귀를 사러 온 30대 직장인 고객은 맥주도 함께 사감
# 순차 분석: 구매 이력을 분석해서 A 품목을 산 후 추가 B 품목을 사는지를 분석
ex) 휴대폰을 새로 구매한 고객은 한 달 내에 휴대폰 케이스를 구매
-형태
# 조건과 반응의 형태(if-then)
-측도
지지도
(Support) |
전체 거래 중 항목 A와 항목 B를 동시에 포함하는 거래의 비율로 정의
지지도 = A와 B가 동시에 포함된 거래 수 / 전채 거래 수 |
신뢰도
(Confidence) |
항목 A를 포함한 거래 중에서 항목 A와 항목 B가 같이 포함 될 확률. 연관성의 정도를 파악할 수 있음
신뢰도 = A와 B가 동시에 포함 된 거래 수 / A를 포함하는 거래 수 |
향상도
(Lift) |
A가 주어지지 않았을 때의 품목 B의 확률에 비해 A가 주어졌을 때의 품목 B의 확률의 증가 비율
연관규칙 A → B는 품목 A와 품목 B의 구매가 서로 관련이 없는 경우에 향상도가 1이 됨
향상도 = A와 B가 동시에 포함 된 거래 수 / (A를 포함하는 거래 수 * B를 포함하는 거래 수) |
-특징
#장점과 단점
| 장점 |
단점 |
탐색적인 기법
조건 반응으로 표현되는 연관성분석 결과를 쉽게 이해 할 수 있음 |
상당한 수의 계산과정
품목 수가 증가하면 분석에 필요한 계산은 기하급수적으로 늘어남 |
강력한 비목적성 분석기법
분석 방향이나 목적이 특별히 없는 경우 목적 변수가 없으므로 유용하게 활용 됨 |
적절한 품목의 결정
너무 세분화한 품목을 갖고 연관석 규칙을 찾으면 수많은 연관성 규칙들이 발견되겠지만, 실제 발생 비율 면에서 의미 없는 분석이 될 수도 있음 |
사용이 편리한 분석 데이터의 형태
거래 내용에 대한 데이터를 변환 없이 그 자체로 이용 |
품목의 비율차이
사용 될 모든 품목들 자체가 전체자료에서 동일한 빈도를 갖는 경우, 연관성 분석은 가장 좋은 결과를 얻음. 그러나 거래량이 적은 품목은 당연히 포함된 거래 수가 적을 것이고 규칙 발견 과정 중에서 제외되기 쉬움 |
계산의 용이성
분석을 위한 계산이 상당히 간단 |
|
-평가기준 적용 시 주의점
# 두 항목의 신뢰도가 높다고 해서 꼭 두 항목이 높은 연관관계가 있는 것은 아님(지지도를 함께 고려)
▶만일 두 항목의 신뢰도가 높게 나왔어도 전체 항목 중 두 항목의 동시 구매율인 지지도가 낮게 나온다면 두 항목 간 연관성을 신뢰하기에는 부족한 점이 있음
▶즉, 구매율 자체가 낮은 항목이기에 일반적인 상관관계로 보기엔 어려움
# 지지도와 신뢰도가 모두 높게 나왔더라도 꼭 두 항목이 높은 연관관계가 있는 것은 아님(향상도를 함께 고려)
▶일반적으로 빈번하게 구매되는 항목들에 대해서는 지지도와 신뢰도가 높게 나올 수 있음
# A, B 두 항목의 신뢰도(Confidence(A→B))가 높게 나왔을 때, 전체거래에서 B의 자체 구매율 보다 A의 자체 구매율이 더 높아야 의미 있는 정보임
-Apriori 알고리즘
# 어떤 항목 집합이 빈발한다면, 그 항목 집합의 모든 부분 집합도 빈발