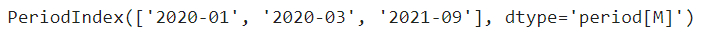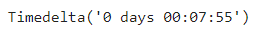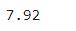from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index(request) :
return HttpResponse("<u>firstapp의 index 페이지!!</u>")
urls.py
from django.contrib import admin
from django.urls import path
from firstapp import views as firstapp_view
urlpatterns = [
### http://127.0.0.1:8000/index
path('index/', firstapp_view.index),
path('admin/', admin.site.urls),
]
Web Site 만들기_html
views.py
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index(request) :
return HttpResponse("<u>firstapp의 index 페이지!!</u>")
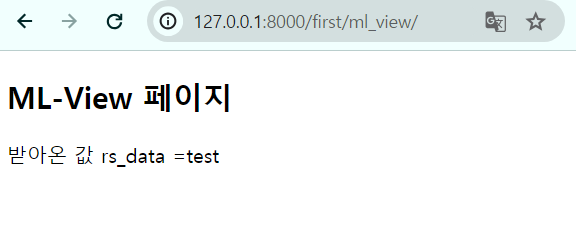
### http://127.0.0.1:8000/index_html
def indexHtml(request) :
return render(
request,
"firstapp/index.html",
{} # 어떤값을 줄건지 딕셔너리에 넣기
)
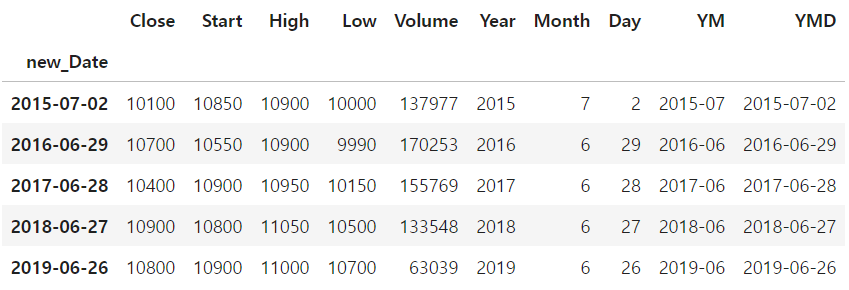
new_Date 컬럼의 데이터를 이용해서, 0000-00(년-월) 단위로 추출하여, YM 컬럼 생성하기
''' 년-월 단위로 추출해서 YM 컬럼 생성하기 '''
df["YM"] = df["new_Date"].dt.to_period(freq="M")
''' 년-월-일 단위로 추출해서 YMD 컬럼 생성하기 '''
df["YMD"] = df["new_Date"].dt.to_period(freq="D")
new_Date 컬럼을 인덱스로 지정하기
df.set_index("new_Date", inplace=True)
df 데이터프레임의 0번째 행의 값을 추출
'''
df["2015-07-02"]
>> 이건 불가능 !! 인덱스가 RangeIndex가 아니면 직접 접근이 안되기 때문에 오류 발생
>> loc 또는 iloc를 사용해야함
'''
df_0 = df.iloc[0]
df_1 = df.loc["2015-07-02"]
df_0, df_1
인덱스 2016-06-29 ~ 2018-06-27까지의 행 조회하기
df.loc["2016-06-29":"2018-06-27"]
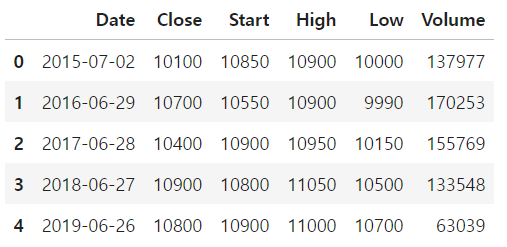
df 변수로 csv 파일 새로 불러들이고, new_Date 컬럼 생성 - Date 컬럼을 날짜 타입으로 변환해서 사용
# - 훈련 독립변수
train_input = fish_data[ : 35]
# - 훈련 종속변수
train_target = fish_target[ : 35]
print(len(train_input), len(train_target))
🧤 테스트 데이터(test)
# - 훈련 독립변수
test_input = fish_data[35 : ]
# - 훈련 종속변수
test_target = fish_target[35 : ]
print(len(test_input), len(test_target))
모델 생성하기
from sklearn.neighbors import KNeighborsClassifier
🧤모델(클래스) 생성
이웃의 갯수는 기본값 사용
kn = KNeighborsClassifier()
kn
🧤 모델 훈련 시키기
훈련데이터 적용
kn.fit(train_input, train_target)
🧤 훈련 정확도 확인하기
# - 훈련 데이터 사용
train_score = kn.score(train_input, train_target)
### 검증하기
# - 테스트 데이터 사용
test_score = kn.score(test_input, test_target)
train_score, test_score
해석 - 훈련 정확도가 1 이기 때문에 과대적합이 발생하였으며, 검증 정확도가 0으로 나타났음
- 따라서, 이 훈련 모델은 튜닝을 통해 성능 향상을 시켜야 할 필요성이 있음
원인분석 - 데이터 분류시 : 35개의 도미값으로만 훈련을 시켰기 때문에 발생한 문제
- 즉, 검증데이터가 0이 나왔다는 것은, 또는 매우 낮은 정확도가 나온 경우데이터에 편향이 발생하였을 가능성이 있다고 의심해 본다.
-샘플링 편향: 특정 데이터에 집중되어 데이터가 구성되어 훈련이 이루어진 경우 발생하는 현상 -샘플링 편향해소방법 : 훈련 / 검증 / 테스트 데이터 구성시에 잘 섞어야 한다. (셔플)
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 갯수 찾기
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2):
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
과대적합이 보통 0.1 이상의 차이를 보이면 정확도의 차이가 많이난다고 의심해 볼 수 있음
모델 선정 기준
과소적합이 일어나지 않으면서, 훈련 정확도가 1이 아니고 훈련과 검증의 차이가 0.1 이내인 경우
선정된 모델을 "일반화 모델"이라고 칭한다.
다만, 추가로 선정 기준 중에 평가기준이 있음
가장 바람직한 결과는 훈련 > 검증> 테스트
(훈련 > 검증 < 테스트인 경우도 있음)
🧤 하이퍼파라미터 튜닝
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 갯수 찾기
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2):
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
- 예측 결과는 빙어로 확인되었으나, 시각적으로 확인하였을 때는 도미에 더 가까운 것으로 확인 됨 - 실제 이웃을 확인한 결과 빙어쪽 이웃을 모두 사용하고 있음 - 이런 현상이 발생한 원인 : 스케일(x축과 y축의 단위)이 다르기 때문에 나타나는 현상 → "스케일이 다르다" 라고 표현 한다.
-해소 방법 : 데이터 정규화 전처리를 수행해야 함
🧤 정규화 하기
현재까지 수행 순서
1. 데이터 수집 2. 독립변수 2차원과 종속변수 1차원 데이터로 취합 3. 훈련, 검증, 테스트 데이터로 섞으면서 분리 4. 훈련, 검증, 테스트 데이터 중에 독립변수에 대해서만 정규화 전처리 수행 5. 훈련모델 생성 6. 모델 훈련 시키기 7. 훈련 및 검증 정확도 확인 8. 하이퍼파라미터 튜닝 9. 예측
❗결측치 처리 방법 1. 결측치가 있는 부분의 데이터를 사용할지 / 말지 결정 2. 사용 안한다면 컬럼과 행 주엥 어느 부분을 제거할지 결정 3. 사용한다면 어떻게 대체할지 결정
❗ 대체 방법 3.1. 결측치가 있는 해당 컬럼의 평균으로 모두 대체 3.2. 범주형 데이터인 경우에는 범주의 비율대비로 대체 3.3. 숫자값인 경우 모두 0으로 대체 3.4. 결측데이터가 속한 주변 컬럼들의 데이터 유형과 유사한 데이터들의 평균으로 대체 3.5. 결측치가 있는 컬럼의 직전/직후 데이터의 평균으로 대체
결측 데이터 현황 확인 - 컬럼별 결측 현황 - sum(0) : 0의 의미는 각 열의 행단위를 의미
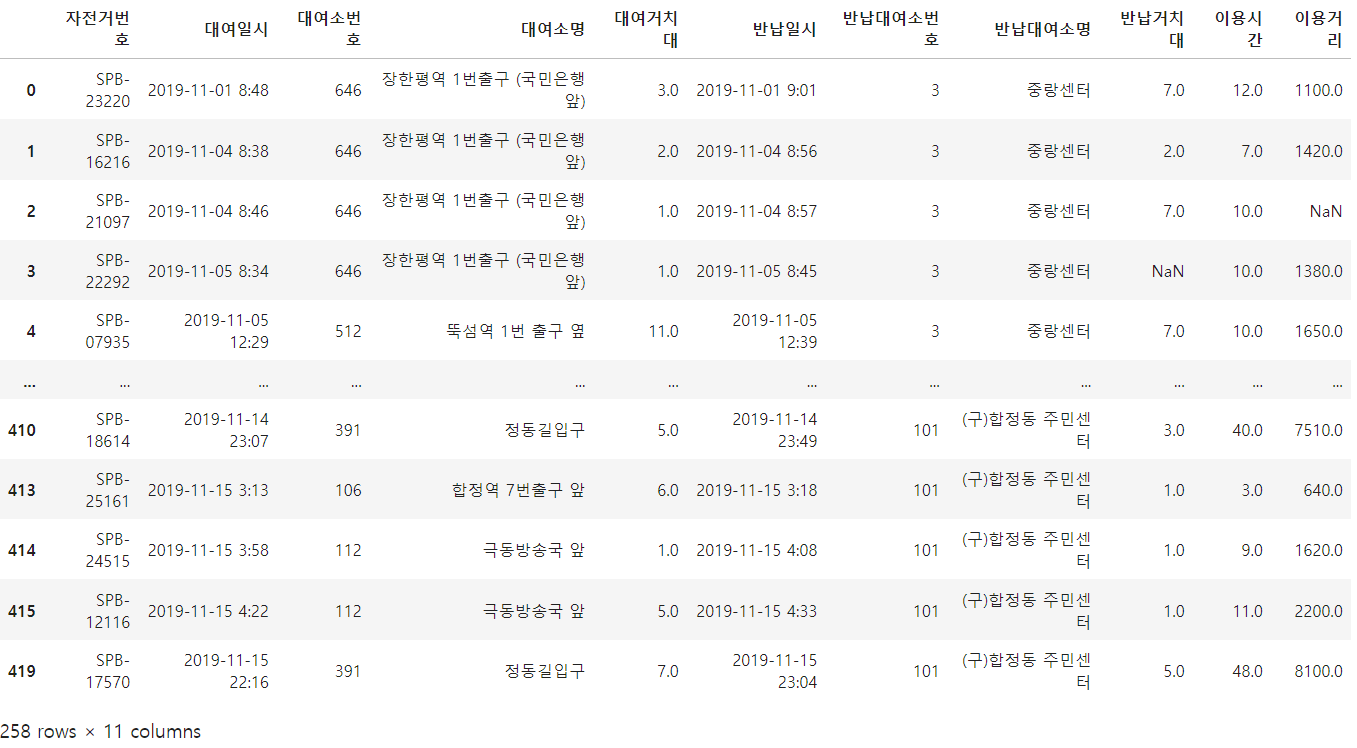
중복데이터 삭제 - 중복 데이터는 사용할지 말지만 결정하면 된다. - 전체 행 420개에서 중복 행162개 삭제 > 258 행 남음
df.drop_duplicates(["이용거리"])
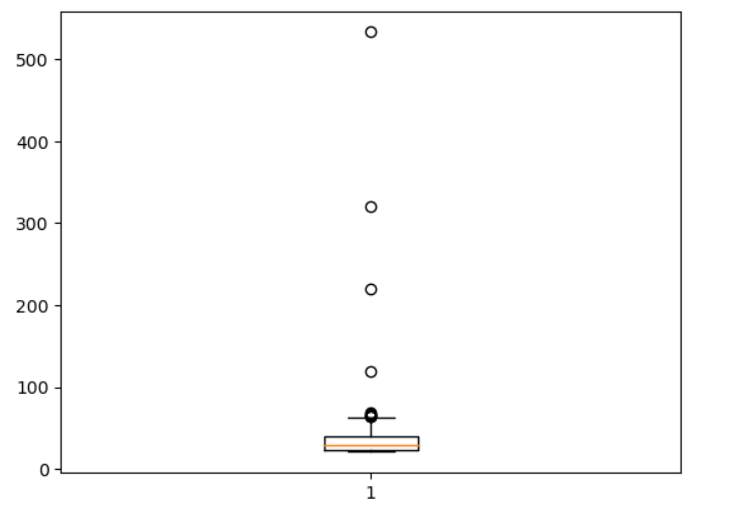
🍒 이상데이터 처리
이상 데이터 처리 순서 1. 결측치 처리가 선행되어야 한다. - 결측치도 데이터로 인식되기 때문이다. 2. 이상데이터에는 범주형, 숫자형 데이터 처리 방식이 다르다. - 일반적으로 이상데이터는 숫자형 데이터 처리를 주로 한다. 3. 이상 데이터 확인은 시각화(boxplot)를 통해서 확인한다. 4. 실제 처리는 계산에 의해 처리된다.
결측치를 처리한 이유가 명확해야 한다. - 2월 결측치의 경우 2월이 28일 밖에 없어서 나머지 일에는 결측치가 나왔고 타당한 이유이기에 처리가 가능하다. - 3월 결측치의 경우 타당한 이유가 없이 결측치를 처리 할 수 없다. 이럴땐 데이터 제공자 측에 왜 데이터가 없는지 확인하고 타당한 이유 생성해야한다. 만약 버스시스템 오류로 인한 확인 불가라는 답변이 온다면 이유가 생성 됐다면 결측치를 0으로 처리하고 타당한 이유 작성하면 된다. - 0 으로 처리하지 않고 3월의 전체 평균을 삽입하거나 비어있는 값 전의 값과 후의 값의 평균을 넣거나 데이터를 아예 삭제하는 방법이 있다.
모든 결측치(NaN)는 0으로 대체하기
df_pivot = df_pivot.fillna(0)
df_pivot
히트맵(heatmap) 시각화
🐳 기준일 및 기준일자별 버스 이용량 시각화 분석
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준월 및 기준일자별 버스 이용량 분석")
### 히트맵 그리기 : 히트맵은 seaborn 라이브러리에 존재한다
# - annot : False는 집계값 숨기기, True는 집계값 보이기
# - fmt : ".0f"는 소숫점 0자리까지 보이기
# - cmap : colormap, 컬러 색상그룹
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap="rocket_r")
### 그래프 출력
plt.show()
그래프 해석 - 1월 ~ 3월까지의 이용량을 분석한 결과 1월에 가장 많은 이용량을 나타내고 있으며, 2월에서 3월로 가면서 이용량이 점진적으로 줄어들고 있는 것으로 확인된다. - 1월 이용량이 가장 많은 이유는 포항시의 특성상 외부에서 관광객의 유입에 따라, 버스를 이용하는 사람들이 많을 것으로 예상된다. - 이에 따라, 포항시 관광객에 대한 데이터를 수집하여 해당 년월에 대한 데이터를 비교 분석해볼 필요성이 있다.
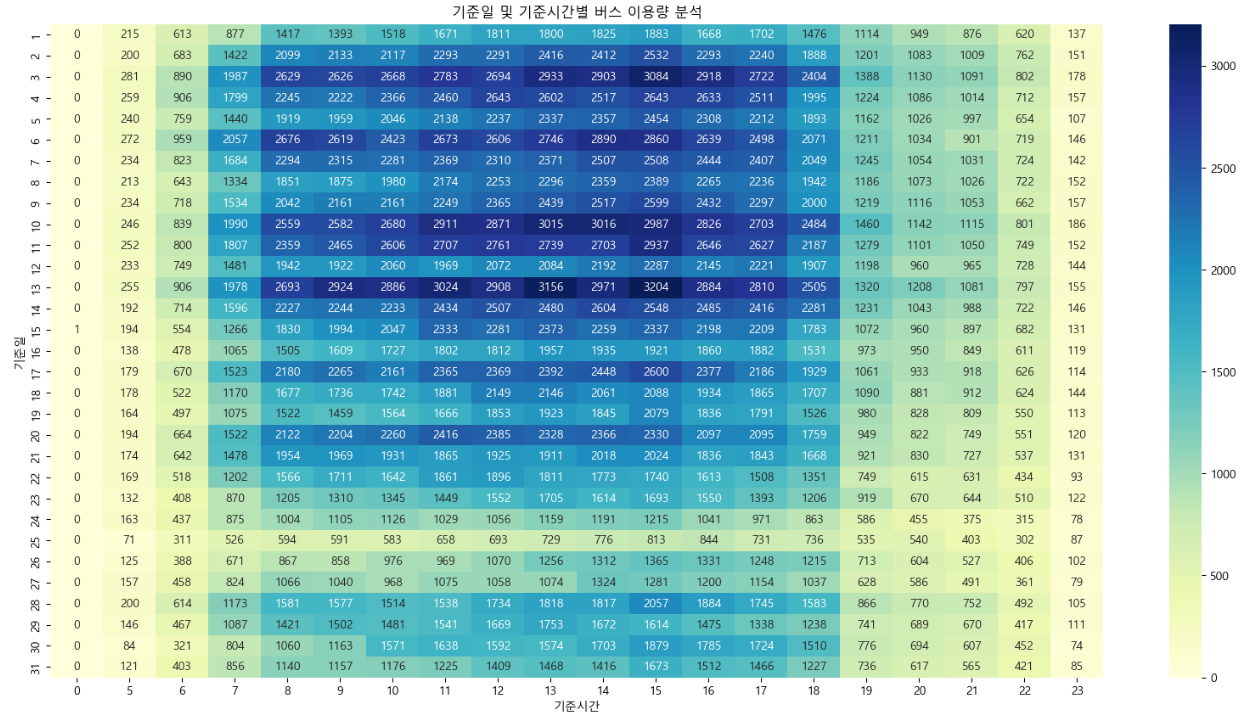
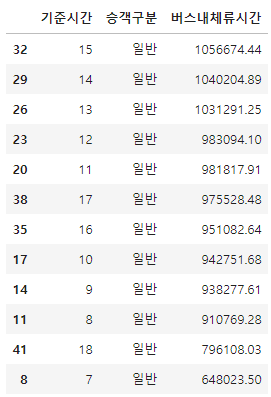
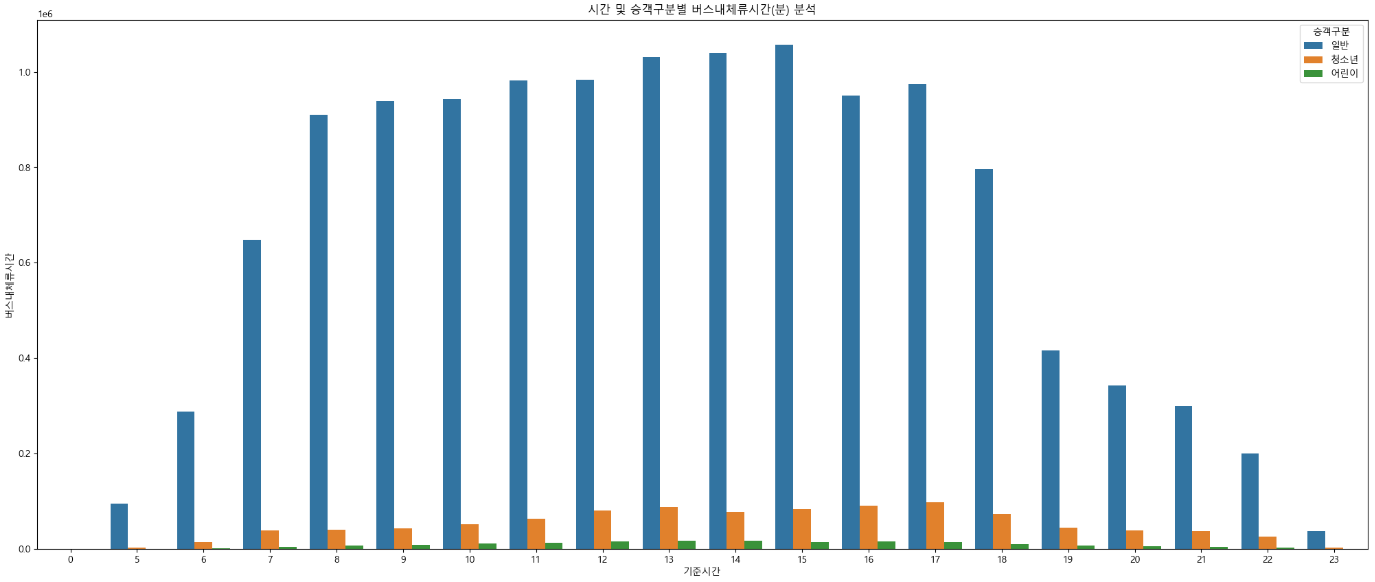
그래프 해석 - 버스 이용량에 대한 분석결과, 일반적으로 출/퇴근 시간에 많아야 할 버스 이용량이 포항시의 경우 오후 시간대에 이용량이 밀집되어있다. - 특히, 오후1시와 3시에 높은 이용량을 나타내고 있다. - 이는 출/퇴근 시간에 자가 차량을 이용하는 사람이 많을 수도 있다는 예상을 할 수 있으며, 인구 분포가 노령인구가 많기에 오후에 이용자가 많을 수도 있을 수 있다. - 따라서, 포항시 인구현황 데이터, 경제활동인구 분석을 통해 비교 분석이 가능할 것으로 예상된다. - 또한, 해당 이용량이 높은 시간대의 노선을 확인하여 특성 확인도 필요할 것으로 예상된다.
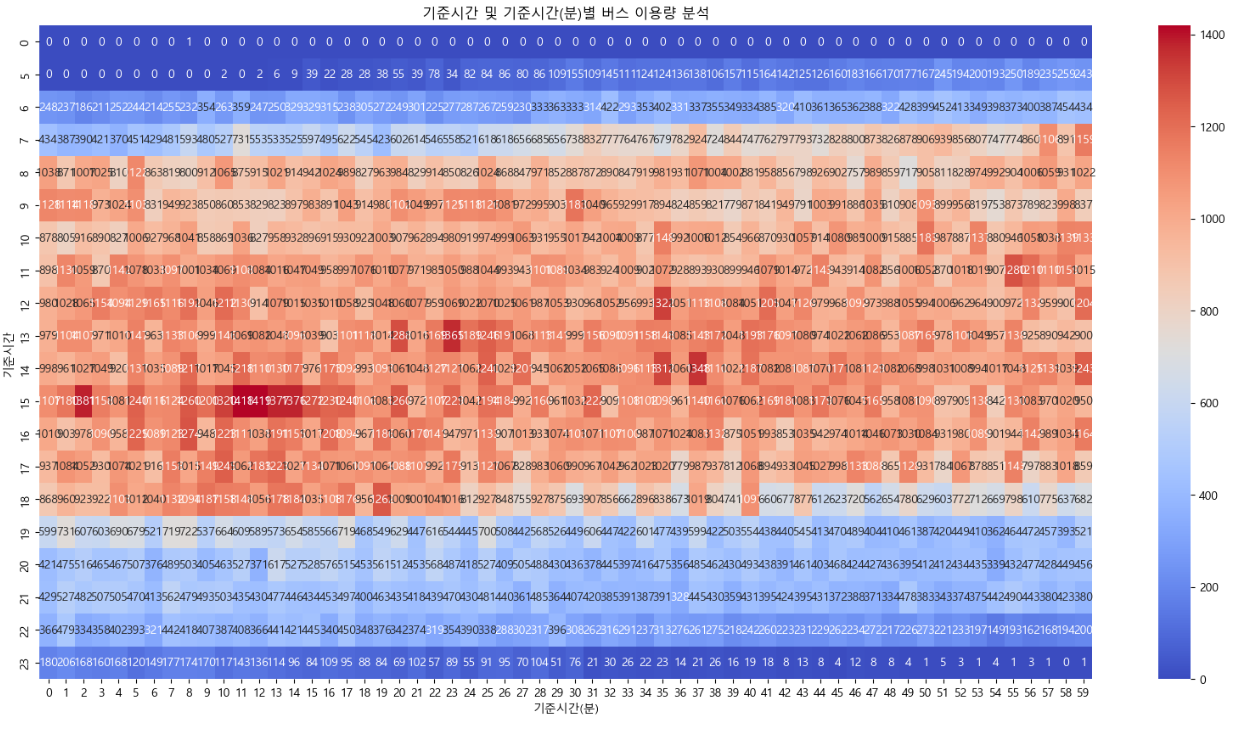
그래프 해석 - 출근 시간대의 버스이용량을 볼 때 오전 7시 55분 ~ 8시 10분 사이에 이용량이 많은 것으로 보인다. - 퇴근 시간대의 버스 이용량을 볼 때 오후 6시 ~ 6시 20분까지 이용량이 많은 것으로 보인다. - 특히 오후 3시 20분까지 버스 이용량이 매우 크게 나타나고 있다. - 오후 시간대 이용자에 대한 추가 확인이 필요할 것으로 보인다.
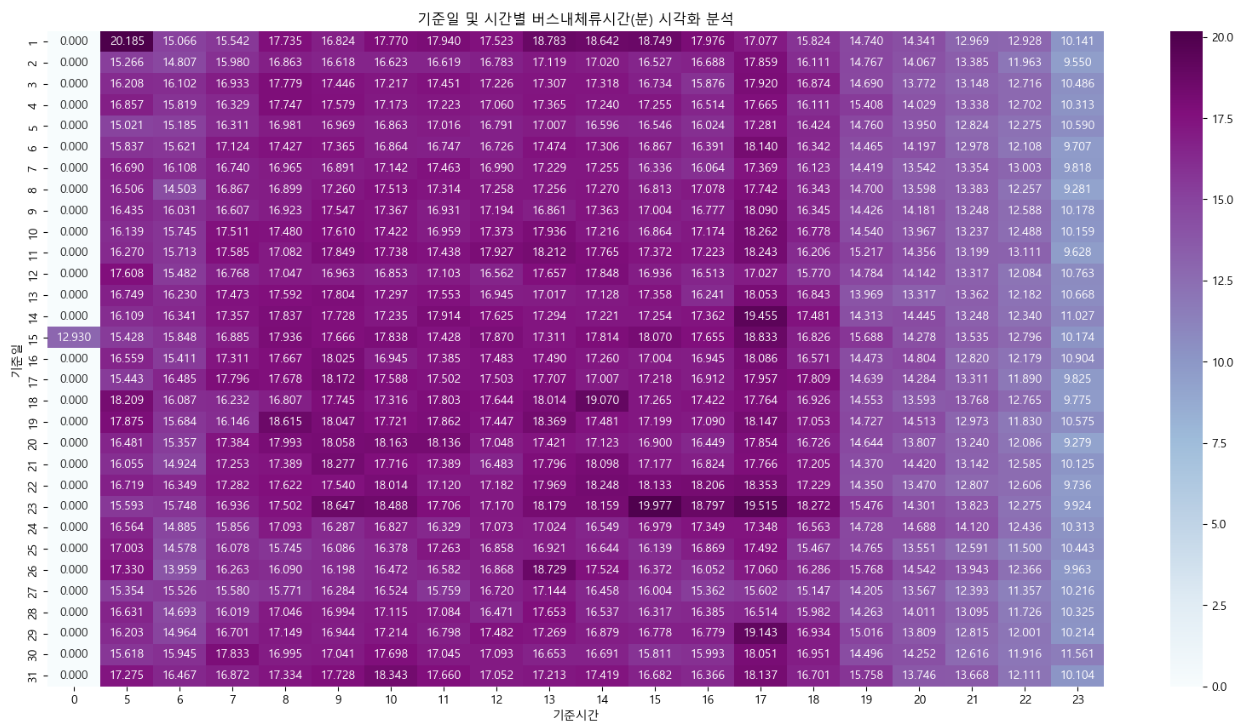
그래프 해석 - 매월 1일에 장거리 이용자가 다소 분포하고 있으며 오전 5시부터 8시를 전후로 장거리 이용자가 증가하고 있다. - 오후 5시에 장거리 이용자가 매우 많게 나타난다. 이는 포항시 주변 상권(경제활동인구)의 출/퇴근 시간의 영향을 받을 수도 있을 것으로 예상된다. - 오후 7시 이후로는 장거리 이용자가 보편적으로 나타나고 있으며, 위에서 분석한 기준일 및 시간별 이용량 분석에서 확인한 바와 같이 7시 이후의 버스 이용량도 급격하게 줄어드는 것을 보아 저녁시간 버스 이용이 현저히 낮은것으로 보인다. - 장거리 이용자가 많은 시간대에 급행버스의 도입에 대한 추가 확인은 필요할 것으로 여겨진다.
fig = plt.figure(figsize=(25, 10))
plt.title("시간 및 승객구분별 버스내체류시간(분) 분석")
### hue : x축 및 y축을 기준으로 비교할 대상 컬럼 지정(범주형 데이터를 보통 사용)
sns.barplot(x="기준시간", y="버스내체류시간", hue="승객구분", data=df_temp2)
plt.show()
밀도그래프 시각화( histplot )
2개의 그래프 조합
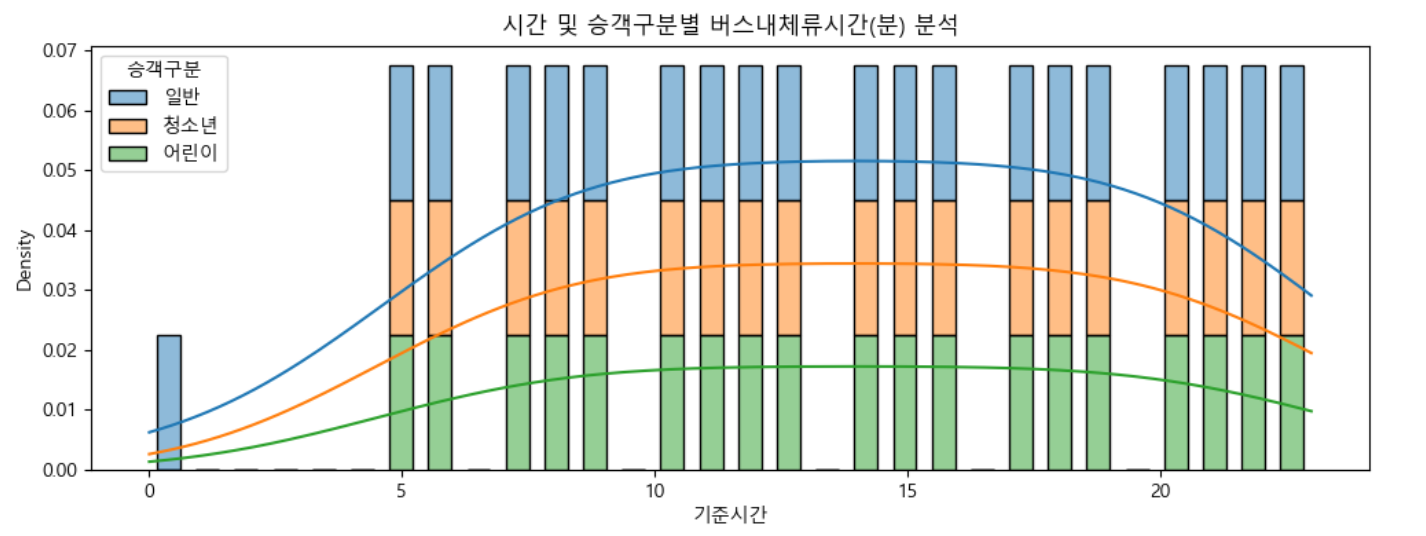
🐳시간대 및 승객구별 버스내체류시간(분) 시각화
plt.figure(figsize=(12, 4))
plt.title("시간 및 승객구분별 버스내체류시간(분) 분석")
sns.histplot(data = df_temp2,
x = "기준시간",
### 사용할 막대의 최대 갯수
bins = 30,
### 막대그래프에 밀도 선그리기
kde = True,
### 범주 데이터
hue = "승객구분",
### 여러 범주를 하나의 막대에 표현하기
multiple = "stack",
### 비율로 표시
stat = "density",
### 막대 너비 : 0.6은 60% 축소한 너비 사이즈
shrink = 0.6)
plt.show()
선그래프 시각화
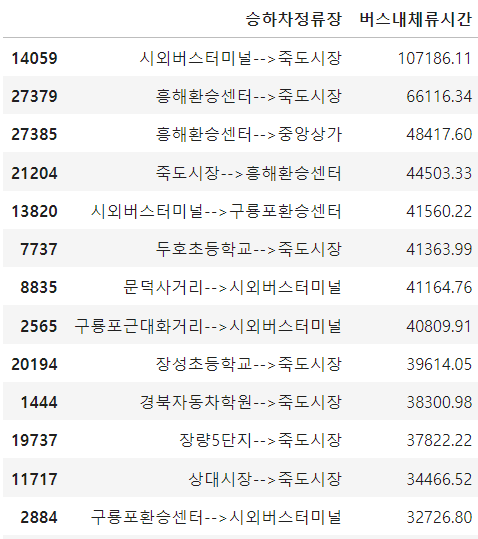
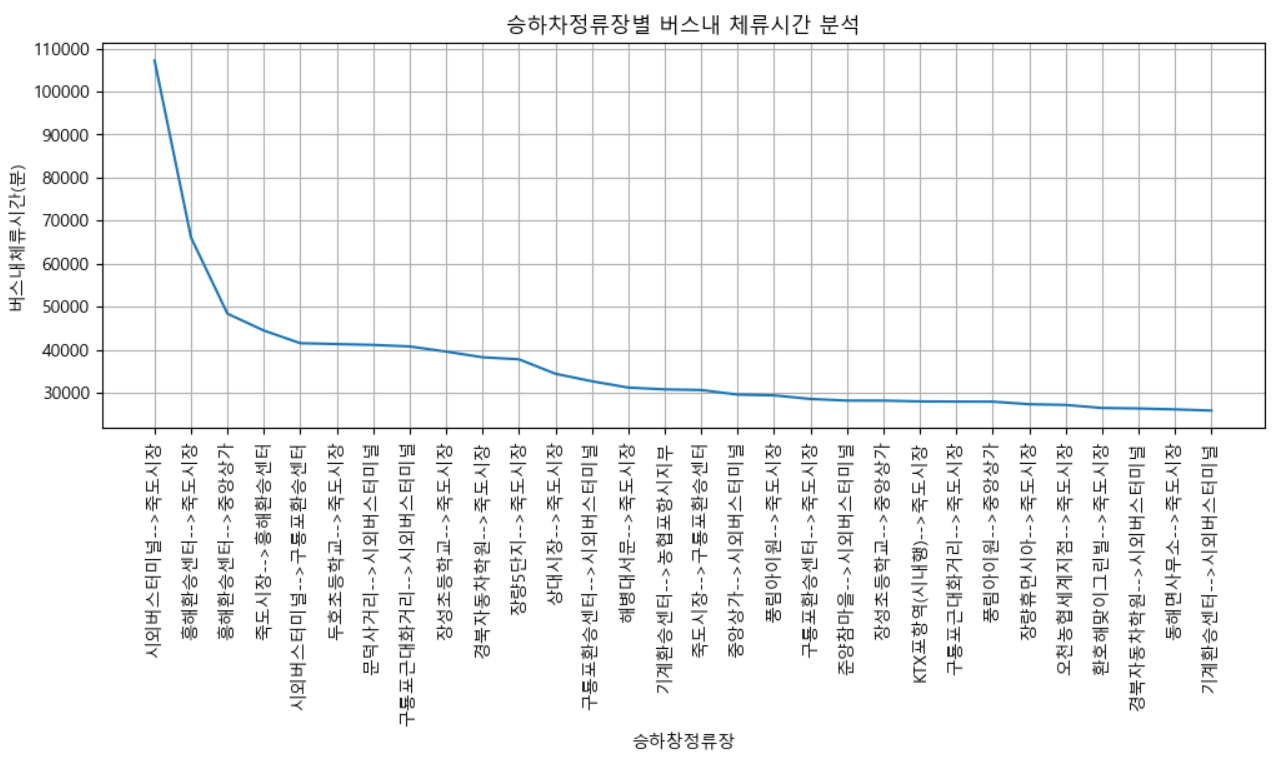
🐳승차하정류장별 버스내체류시간(분) 상위 30건 시각화 분석
구간(승차정류장 ~ 하차정류장) 까지의 버스내 체류시간을 이용하여 체류시간이 많은 구간을 확인하기
df_bus_card_col_new_dict = {}
for k, v in zip(df_bus_card_col_org.iloc[:, 0], df_bus_card_col_org.iloc[:, 1]) :
# print(k,v)
df_bus_card_col_new_dict[k] = v
df_bus_card_col_new_dict
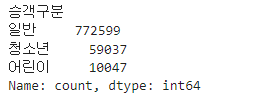
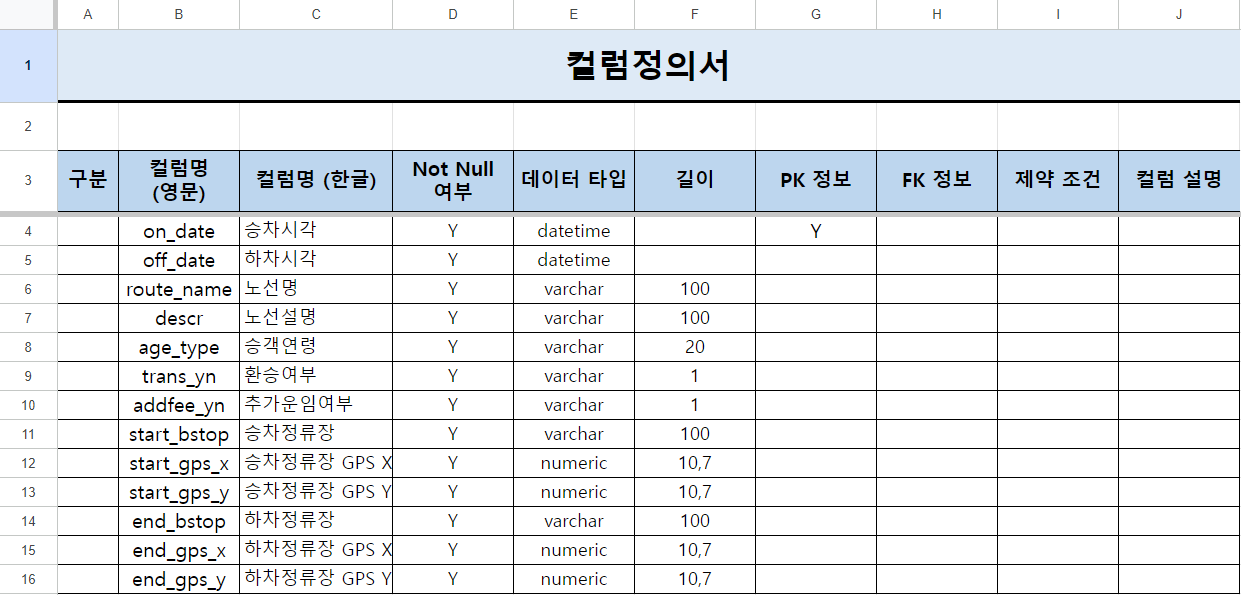
소주제 <버스 이용량 분석> * 기준월 및 기준일자별 버스 이용량 분석 비교 * 기준일 및 시간대별 버스 이용량 분석 비교 * 기준시간 및 시간(분)별 버스 이용량 분석 비교
<버스 내 체류시간 분석> * 기준월 및 기준일자별 버스 체류시간(하차시간 - 승차시간) 분석 비교 * 기준일 및 시간대별 버스 체류시간 분석 비교 * 기준시간 및 시간(분)별 버스 체류시간 분석 비교 * 승하차정류장 구간별(정류장 체류시간의 합) 버스 내 체류시간 - 체류시간(분) 상위 30건 분석 비교
🍀 분석을 위한 데이터 가공하기
데이터 프레임 복제하기
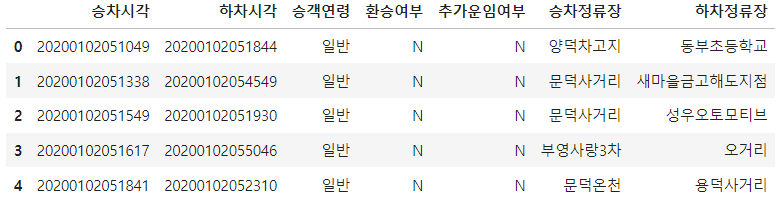
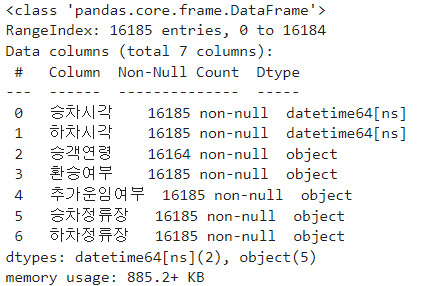
df_bus_card_kor = df_bus_card_org.copy()
승차시각과 하치시간 데이터 타입을 문자열로 변환하기 - astype() : 데이터 형변환 함수. replace 지원안하기 때문에 바뀐 형상을 자기 자신에게 반영시켜야 한다.