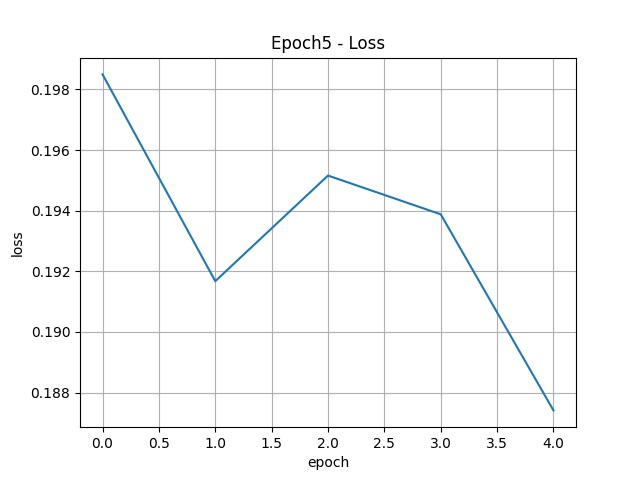
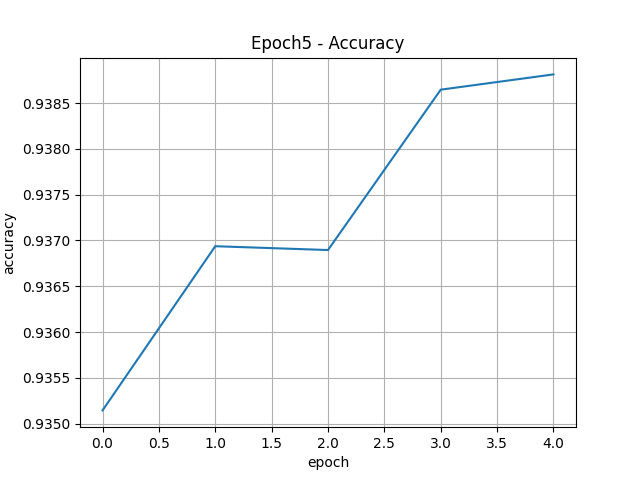
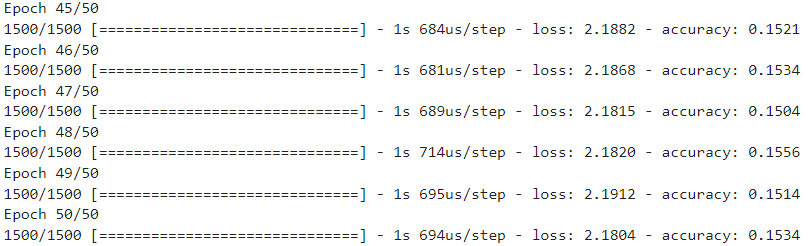
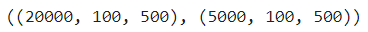import tensorflow as tf
from tensorflow import keras
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
사용 데이터셋
from tensorflow.keras.datasets import imdb
💡 IMDB : 영화 리뷰 감상평 데이터 - 순환신경망에서 대표적으로 사용되는 데이터셋(외국) - 케라스에서 영어로된 문장을 정수(숫자)로 변환하여 제공하는 데이터셋 - 감상평이 긍정과 부정으로 라벨링 되어있음 - 총 50,000개의 샘플로 되어 있으며, 훈련 및 테스트로 각각 25,000개씩 분리하여 제공됨
IMDB 데이터 읽어들이기 - num_words=500 : 말뭉치 사전의 갯수 500개만 추출하겠다는 의미 * list 1개 = 문장 1개 * 5만개의 문장 들어있음 * 마지막 list는 긍정/부정에 대한 값이 들어있음(0 : 부정, 1 : 긍정)
텍스트 길이 조정 속성(매개변수) - truncating → 추출 위치(앞 또는 뒤부터) → pre 뒤쪽부터 추출하기 (기본값), 앞쪽 제거하기 → post 앞쪽부터 추출하기, 뒤쪽 제거하기 - padding → 채울 위치(앞 또는 뒤부터) → pre 앞쪽을 0으로 채우기 (기본값) → post 뒤쪽을 0으로 채우기
계층 생성 및 모델에 추가하기 - input_shape=(100, 500) : 100은 특성 갯수, 500은 말뭉치 갯수
''' 계층 생성 및 모델에 추가하기
- input_shape=(100, 500) : 100은 특성 갯수, 500은 말뭉치 갯
'''''' 입력계층이면서 RNN 계층 '''
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
''' 출력계층 '''
model.add(keras.layers.Dense(1, activation="sigmoid"))
원-핫(One - Hot) 인코딩
📍 RNN에서 사용할 독립변수 처리 방식 - RNN 모델에서는 독립변수의 데이터를원-핫 인코딩데이터 또는임베딩 처리를 통해서 훈련을 시켜야 한다
📍 원-핫(One-Hot) 인코딩 방식 - 각 데이터(값) 중에 1개의 단어당 분석을 위해 500개의 말뭉치와 비교하여야 함 - 이때 비교하기 위해 원-핫 인코딩으로 변환하여 비교하는 방식을 따름 - keras.util.to_categorical() 함수 사용 - 프로그램을 통해 변환해야 함(별도 계층이 존재하지는 않음) - 각 단어별로 원-핫인코딩 처리가 되기에 데이터가 많아지며, 속도가 느림 - 데이터가 많아지기 떄문에 많은 메모리 공간을 차지함
📍 단어 임베딩(Embedding) 방식 - 원-핫 인코딩의 느린 속도를 개선하기 위하여 개선된 방식(메모리 활용) - 많은 공간을 사용하지 않음 - keras.layers.Embedding() 계층을 사용함(프로그램 처리 방식이 아님)
''' 자동 저장 및 종료하는 콜백함수 정의하기 '''
model_path = "./model/best_simpleRNN_model.h5"''' 모델 자동 저장 콜백함수 '''
checkpoint_cb = keras.callbacks.ModelCheckpoint(model_path)
''' 자동 종료 콜백 함수 '''
early_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights = True)
checkpoint_cb, early_cb
모델 훈련하기 - batch_size : 훈련 시 데이터를 배치사이즈 만큼 잘라서 종속변수와 검증 진행 → 배치사이즈 만큼 종속변수와 비교 시 틀리게 되면, 다음 배치사이즈에서 오류를 줄여가면서 훈련을 진행하게 된다 → 배치사이즈의 값을 정의하지 않으면 전체 데이터를 기준으로 종속변수와 비교 및 훈련 반복 시 오류 조정 진행 된다 → 배치사이즈의 값은 정의된 값은 없으며, 보통 32, 64 정도로 주로 사용함 → 튜닝 대상 하이퍼파라미터 변수
history = model.fit(train_oh,train_target, epochs=100, batch_size=64,validation_data=(val_oh, val_target),callbacks=[checkpoint_cb, early_cb])
📍 퍼셉트론(Perceptron) - 인공신경망의 한 종류 - 주로 이진분류 또는 다중분류에 사용되는 초기 인공신경망 모델 - 종속변수가 연속형인 회귀에서는 사용되지 않음(분류에서만 사용) - 퍼셉트론에는 단층 퍼셉트론과 다층 퍼셉트론이 있음 - 주로 다층 퍼셉트론이 성능이 좋음
📍 단층 퍼셉트론(Single-Layer perceptron, SLP), 인공신경망 층 - 입력층과 출력층으로만 구성되어 있음 - 주로 이진 분류에 사용됨(성능이 낮은 경우, 다층 퍼셉트론으로 사용) - 선형 활성화 함수(linear)를 사용
📍 다층 퍼셉트론(Multi-Layer perceptron, MLP), 심층신경망 층 - 입력층, 은닉층(1개 이상), 출력층으로 구성됨 - 주로 다중 분류에 사용됨(이진분류도 가능) - 단층 퍼셉트론보다 높은 성능을 나타냄 - 여러 층(입력, 은닉, 출력)으로 이루어져 있다고 해서 "다층"이라고 칭함 - 은닉층에는 비선형 활성화 함수를 사용함(linear를 제외한 나머지, Sigmoid, RelU 등) - 발전된 모델들이 현재 사용되는 모델들이며 계속 나오고 있음
퍼셉트론 분류데이터 사용
라이브러리 정의
import padnas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
''' 단층 퍼셉트론 모델 '''from sklearn.linear_model import Perceptron
''' 다층 퍼셉트론 모델 '''from sklearn.neural_network import MLPClassifier
''' 최적의 하이퍼파라미터 찾기 '''from sklearn.model_selection import GridSearchCVR
''' 성능평가 '''from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
''' 시각화 '''import matplotlib.pyplot as plt
import seaborn as sns
데이터 불러들이기
독립변수와 종속변수로 분류하기
정규화하기
훈련 : 검증 : 테스트 = 6 : 2 : 2 로 분리하기 4가지 모두 이전과 동일하므로 코드 생략
param_grid = {
### hidden_layer_sizes : 은닉계층 정의# - (10,) : 은닉계층 1개 사용, 출력크기 10개를 의미함# - (10, 10) : 은닉계층 2개 사용, 각각의 출력 크기가 10개라는 의미# - (10, 11, 12) : 은닉계층 3개 사용, 각각의 출력 크기는 10, 11, 12"hidden_layer_sizes" : [(10,), (50,), (100,)],
"alpha" : [0.0001, 0.001, 0.01],
"max_iter" : [1000]
}
param_grid
- 입력계층의 출력크기 64 - 은닉계층의 출력크기 32 - 나머지는 ? - 콜백함수 모두 적용 - 옵티마이저 모두 적용해보기 - 정밀도, 재현율, f1-score, confusion_matrix출력
작성한 코드
라이브러리 정의
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras
from sklearn.metrics import precision_score, recall_score, f1_score, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
데이터 가져오기 - 데이터프레임 변수 : data - 데이터 읽어들이기 - 종속변수 : 주택가격 - 주택가격이 연속형 데이터이므로 회귀데이터
data = pd.read_csv("./data/08_wine.csv")
data.head(1)
독립변수(X)와 종속변수(y)로 분리하기
X = data.iloc[:,:-1]
y = data["class"]
X.shape, y.shape
데이터 정규화 - X_scaled 변수명 사용
ss = StandardScaler()
ss.fit(X)
X_scaled = ss.transform(X)
X_scaled.shape
훈련 : 테스트 데이터로 분류하기 (8 : 2) - 사용 변수 : X_train, X_test, y_train, y_test
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
데이터 불러들이기
data = pd.read_csv("./data/08_wine.csv")
data.head(1)
데이터 정규화
ss = StandardScaler()
ss.fit(X)
X_scaled = ss.transform(X)
X_scaled.shape
훈련 : 검증 : 테스트 데이터로 분류하기 (6 : 2 : 2)
X_train, X_temp, y_train, y_temp = train_test_split(X_scaled, y,
test_size=0.4,
random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp,
test_size=0.5,
random_state=42)
print(f"훈련 데이터 {X_train.shape} : {y_train.shape}")
print(f"검증 데이터 {X_val.shape} : {y_val.shape}")
print(f"테스트 데이터 {X_test.shape} : {y_test.shape}")
모델 생성
model = Sequential()
model
계층 생성
'''
입력 은닉 계층에는 softmax빼고 다른 함수 다 들어갈 수 있다.
softmax는 출력 계층에만 들어간다
''''''
<입력계층>
- 64 : 출력크기
- activation=relu0 : 활성화 함수. relu는 0보다 크면 1, 0보다 작으면 0
- input_dim=3 : 입력 특성의 갯수 (input_shape 대신에 사용가능)
'''
model.add(Dense(64, activation="relu", input_dim=3))
'''
Dropout은 과대적합 나올때 은닉계층 전에 사용하여 모델을 덜 똑똑하게 만들어버린다.
은닉계층이 두개라면 은닉계층 전에 사용할 수 있기 때문에 dropout또한 2개 사용 가능하다.
''''''
<은닉 계층>
'''
model.add(Dense(32, activation="relu"))
'''
<출력 계층>
- sigmoid : 이진분류이기 때문에 0.5를 기준으로 0 또는 1로 나뉘는 sigmoid 사용
'''
model.add(Dense(1, activation="sigmoid"))
'''
- validation_data : 검증 데이터를 이용해서 성능평가를 동시에 수행함
'''
history = model.fit(train_scaled, train_target, epochs=20, verbose=1,
validation_data=(val_scaled, val_target))
history에서 가져올수 있는 값 확인
history.history.keys()
훈련에 대한 loss와 검증에 대한 loss 비교하는데 유용
시각화 - 손실곡선
'''
- 훈련과 검증에 대한 손실(loss) 곡선 그리기
'''# 훈련 손실률 그래프
plt.plot(history.epoch, history.history["loss"])
# 검증 손실률 그래프
plt.plot(history.epoch, history.history["val_loss"])
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid()
# 범례 추가
plt.legend(['Train_Loss', 'Val_Loss'])
# 제목 설정
plt.title("Epoch20 - Train_Loss & Val_Loss")
# 그래프 저장
plt.savefig("./saveFig/Train-Loss-Val-Loss.png")
plt.show()
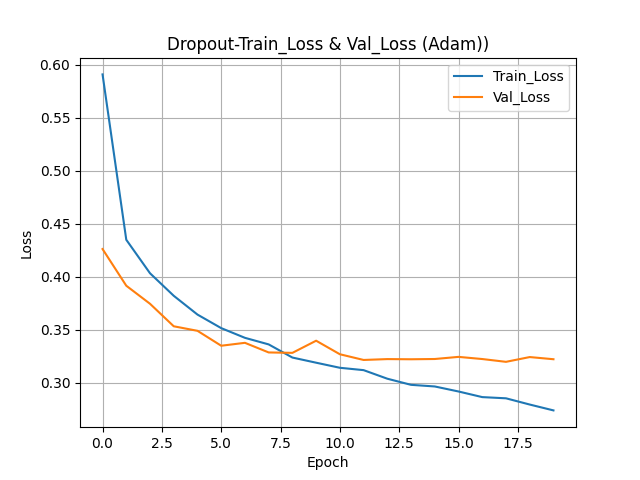
- 딥러닝은 손실률을 기준으로 판단한다.
- 훈련 곡선이 검증 곡선 보다 밑에 있어야 과소적합이 일어나지 않는다.
- Epoch가 2인 시점에 두 곡선이 가장 가까우면서 그 이후로 과대적합이 발생하고 있다.
시각화 - 정확도 곡선
'''
- 훈련과 검증에 대한 정확도(accuracy) 곡선 그리기
'''# 훈련 정확도 그래프
plt.plot(history.epoch, history.history["accuracy"])
# 검증 정확도 그래프
plt.plot(history.epoch, history.history["val_accuracy"])
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.grid()
# 범례 추가
plt.legend(['Train_Accuracy', 'Val_Accuracy'])
# 제목 설정
plt.title("Epoch20 - Train_Acc & Val_Acc")
# 그래프 저장
plt.savefig("./saveFig/Train-Acc-Val-Acc.png")
plt.show()
- 손실이 과대적합이 일어나면 정확도 또한 과대적합이 일어날 가능성이 높다.
- Epoch가 2인 시점부터 시작하여 과대적합이 일어나고 있다.
훈련 및 검증에 대한 손실 및 정확도 표현하여 과적합 여부 확인하기
- model 변수명으로 신규 모델 만들기 - 옵티마이저 adam 사용 - 훈련 및 검증 동시에 훈련시킨 후 손실 및 검증 곡선 그려서 과적합 여부 확인하기
함수 호출하기
model = model_fn()
모델 설정
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adam",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
모델 훈련
history = model.fit(train_scaled, train_target, epochs=20, verbose=1,
validation_data=(val_scaled, val_target))
시각화 - 손실곡선 & 정확도 곡선
# 훈련 정확도 그래프
plt.plot(history.epoch, history.history["accuracy"])
# 검증 정확도 그래프
plt.plot(history.epoch, history.history["val_accuracy"])
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.grid()
# 범례 추가
plt.legend(['Train_Accuracy', 'Val_Accuracy'])
# 제목 설정
plt.title("Adam-Train_Acc & Val_Acc")
# 그래프 저장
plt.savefig("./saveFig/Adam-Train-Acc-Val-Acc.png")
plt.show()
Epoch 3인 시점에서 두 곡선이 가장 가깝다.
그 이후로는 과대적합이 일어나고 있다.
Epoch 200번으로 설정하여 모델 훈련 및 시각화
history = model.fit(train_scaled, train_target, epochs=200, verbose=1,
validation_data=(val_scaled, val_target))
심층신경망_성능 규제
📍성능 규제 - 성능(과적합 여부 포함)을 높이기 위한 방법 - 보통 전처리 계층을 사용하게 된다. - 전처리 계층은 훈련에 영향을 미치지 않음
성능 규제 방법 - 드롭 아웃(Dropout())
📍드롭아웃(Dropout) - 훈련 과정 중 일부 특성들을 랜덤하게 제외 시켜서 과대적합을 해소하는 방법 - 딥러닝에서 자주 사용되는 전처리 계층으로 성능 개선에 효율적으로 사용됨
📍사용방법 - 계층의 중간에 은닉층(hidden layer)으로 추가하여 사용됨 - 훈련에 관여하지 않음 → 데이터에 대한 전처리라고 보면 됨
모델 생성
''' Dropout(0.3) : 사용되는 특성 30% 정도를 제외하기 '''
dropout_layer = keras.layers.Dropout(0.3)
model = model_fn(dropout_layer)
model.summary()
모델 설정
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adam",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
모델 훈련
history = model.fit(train_scaled, train_target, epochs=20, verbose=1,
validation_data=(val_scaled, val_target))
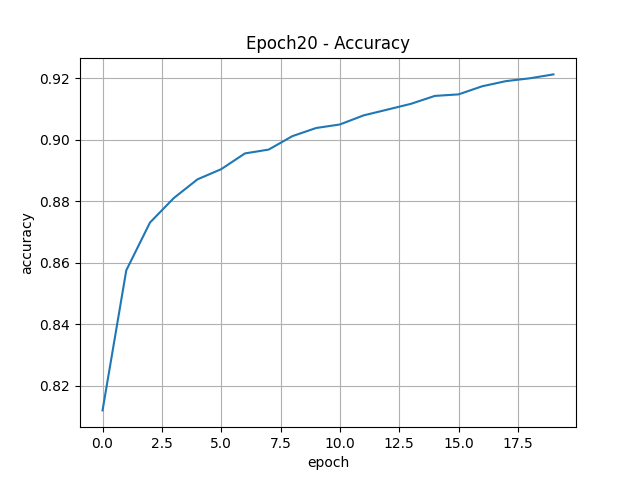
강사님 그래프 설명 손실률은 훈련 곡선이 아래 있어야 함 Epoch 8 시점에서 두 곡선이 가까움 Epoch 7.5를 기점으로 과대적합이 점점 일어나고 있음 > Epoch 8까지가 적당 훈련 곡선이 검증 곡선 위에 있으면 과소적합이 일어남
정확도는 훈련 곡선이 위에 있어야 함 Epoch 10을 기준으로 왼쪽은 과소적합 오른쪽은 과대적합
손실률이 Epoch 8 시점에서 가장 좋게 나타나면 정확도 Epoch 8 시점을 비교해 본다 손실률과 정확도를 비교하여 적절한 Epoch를 찾아내고 그 시점까지로 다시 훈련시킨다. Epoch 14회 정도 돌리면 가장 적절한 횟수를 찾을 수 있을 것 같다
모델 저장 및 복원하기
📍모델 저장하는 방법 - 가중치만 저장하기 → 모델이 훈련하면서 찾아낸 가중치 값들만 저장하기 → 모델 자체가 저장되지는 않는다 → 모델 신규생성 > 저장된 가중치 불러와서 반영 > 예측 진행 → 별도로 훈련(fit)은 하지 않아도 된다 - 모델 자체 저장하기 → 저장된 모델을 불러와서 > 예측 진행
가중치 저장 및 불러들이기
가중치 저장하기
''' 저장시 사용되는 확장자는 보통 h5를 사용한다 '''
model.save_weights("./model/model_weight.h5")
저장된 가중치 불러들이기
''' 1. 모델 생성 '''
model_weight = model_fn(keras.layers.Dropout(0.3))
model_weight.summary()
''' 2. 가중치 적용하기 '''
model_weight.load_weights("./model/model_weight.h5")
''' 이후 부터는 바로 예측으로 사용 '''
모델 자체를 저장 및 불러들이기
모델 자체 저장하기
model.save("./model/model_all.h5")
모델 자체 불러들이기
model_all = keras.models.load_model("./model/model_all.h5")
model_all.summary()
''' 이후 부터는 바로 예측으로 사용 '''
📍 콜백함수(Callback Function) - 모델 훈련 중에 특정 작업(함수)를 호출할 수 있는 기능 - 훈련(fit)시에 지정하는 함수를 호출하는 방식 - 훈련 중에 발생시키는 "이벤트"라고 생각하면 된다 - 별도의 계층은 아니며, 속성(매개변수)으로 정의된다.
📍 콜백함수 종류 - ModelCheckpoint() : epoch 마다 모델을 저장하는 방식 : 단, 앞에서 실행된 훈련 성능보다 높아진 경우에만 저장됨 - EarlyStopping() : 훈련이 더이상 좋아지지 않으면 훈련(fit)을 종료시키는 방식 : 일반적으로 ModelCheckpoint()와 함께 사용
ModelCheckPoint 콜백 함수
모델 생성하기
model = model_fn(keras.layers.Dropout(0.3))
모델 설정하기
model.compile(
### 옵티마이저 정의 : 손실을 줄여나가는 방법
optimizer="adam",
### 손실함수 : 종속변수의 형태에 따라 결정 됨
loss="sparse_categorical_crossentropy",
### 훈련 시 출력할 값 : 정확도 출력
metrics="accuracy"
)
콜백함수 생성하기 - 훈련(fit) 전에 생성 - save_best_only = True : 이전에 수행한 검증 손실률보다 좋을 떄 마다 훈련모델 자동 저장 시키기 : 훈련이 종료되면, 가장 좋은 모델만 저장되어 있다. - save_best_only = False : epoch마다 훈련모델 자동 저장 시키기 - 저장된 모델은 모델 자체가 저장되는 방식으로 추후 불러들인 후 바로 예측으로 사용 가능
콜백함수 생성하기 - patience=2 : 더 이상 좋아지지 않는 epoch의 갯수 지정 : 가장 좋은 시점의 epoch 이후 2번 더 수행 후 그래도 좋아지지 않으면 종료시킨다는 의미 - restore_best_weights=True : 가장 낮은 검증 손실을 나타낸 모델의 하이퍼파라미터로 모델을 업데이트 시킴
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
''' 실행 결과를 동일하게 하기 위한 처리(완전 동일하지 않을 수도 있음) '''
tf.keras.utils.set_random_seed(42)
''' 연산 고정 '''
tf.config.experimental.enable_op_determinism()
데이터 정의
'''
- 패션MNIST 데이터 읽어들이기 (훈련 및 테스트 데이터)
- 정규화 하기
- 훈련 및 검증 데이터로 분류하기
'''''' 패션MNIST 데이터 읽어들이기 '''
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
''' 정규화 '''
train_scaled_255 = train_input / 255.0
test_scaled_255 = test_input / 255.0''' 훈련 및 검증 데이터로 분류하기 '''
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled_255,
train_target,
test_size=0.2,
random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)
print(test_scaled_2d.shape, test_target.shape)
심층신경망(Deep Neural Network, DNN)
인공신경망(Artificial Neural Networt, ANN) : 계층이 1개인 경우 또는 은닉계층이 없는 경우
심층신경망(Deep Neural Network, DNN) : 은닉계층을 가지고 있는 경우
모델 생성시키는 함수 생성하기
- 함수이름 : model_fn → 매개변수 : a_layer 매개변수 → 은닉계층이 있는 경우 계층자체를 매개변수로 받아서 아래에서 추가 - 모델생성 - 입력층(1차원 전처리계층) 추가 - 100개의 출력을 담당하는 은닉계층 추가, 활성화 함수 "relu" - 추가할 은닉계층이 있으면 추가, 없으면(None) 건너뛰기 - 출력층 - 모델 반환
함수 생성
defmodel_fn(a_layer = None):
model = keras.Sequential()
model.add(keras.layers.Flatten(28, 28))
model.add(keras.layers.Dense(100, activation='relu'))
''' 추가할 은닉계층이 있는 경우만 실행 '''if a_layer :
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model
1. 신경망 모델 생성 2. 계층 추가하기 - 1차원 전처리 계층 추가 - 은닉계층 추가, 활성화함수 relu 사용, 출력크기 100개 - 최종 출력계층 추가 3. 모델설정하기 - 옵티마이저는 adam 사용, 학습률 0.1 사용 4. 훈련시키기 - 훈련횟수 : 50 5. 성능 평가하기
''' 1. 신경망 모델 생성 '''
model = keras.Sequential()
''' 2. 계층 추가하기
- 1차원 전처리 계층 추가
- 은닉계층 추가, 활성화함수 relu 사용, 출력크기 100개
- 최종 출력계층 추가
'''
model.add(
keras.layers.Flatten(input_shape=(28, 28))
)
model.add(
keras.layers.Dense(100, activation="relu")
)
model.add(
keras.layers.Dense(10, activation="softmax")
)
''' 3. 모델설정하기
- 옵티마이저는 adam 사용, 학습률 0.1 사용
'''
adam = keras.optimizers.Adam(
learning_rate=0.1
)
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics="accuracy"
)
<실습> - 옵티마이저에 적용할 학습기법(sgd, adagrad, rmsprop, adam) 중에 가장 좋은 성능을 나타내는 옵티마이저 학습기법 확인하기 - 훈련횟수 : 50회 - 학습률은 기본값 사용 - 은닉계층 relu 사용 - 성능 평가결과를 이용해서 손실율이 가장 낮을 때의 학습방법, 정확도가 가장 높을 때의 학습방법을 각각 출력하기
작성한 코드
''' 1. 신경망 모델 생성 '''
model = keras.Sequential()
''' 2. 계층 추가하기 '''
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
opt = ["sgd", "adagrad", "rmsprop", "adam"]
best_loss_optimizer = None
best_accuracy_optimizer = None
best_loss = float('inf') # 초기값을 무한대로 설정
best_accuracy = 0.0for i in opt:
if i == "sgd":
optimizer = keras.optimizers.SGD()
elif i == "adagrad":
optimizer = keras.optimizers.Adagrad()
elif i == "rmsprop":
optimizer = keras.optimizers.RMSprop()
else:
optimizer = keras.optimizers.Adam()
print(f"-------------------옵티마이저 {i} 시작-------------------")
model.compile(
optimizer=optimizer,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
model.fit(train_scaled, train_target, epochs=50)
loss, accuracy = model.evaluate(val_scaled, val_target)
print(f"손실율 : {loss} / 정확도 : {accuracy}")
print(f"-------------------옵티마이저 {i} 종료-------------------")
# 가장 좋은 성능인지 확인if loss < best_loss:
best_loss = loss
best_loss_optimizer = i
if accuracy > best_accuracy:
best_accuracy = accuracy
best_accuracy_optimizer = i
print("손실율이 가장 낮을 때의 학습방법:", best_loss_optimizer)
print("정확도가 가장 높을 때의 학습방법:", best_accuracy_optimizer)
강사님 코드
### 옵티마이저 학습방법 및 반복횟수를 받아서 처리할 함수 정의defgetBestEval(opt, epoch) :''' 모델 생성 '''
model = keras.Sequential()
''' 레이어계층 생성 및 모델에 추가하기 '''
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
''' 모델 설정하기 '''
model.compile(optimizer = opt,
loss="sparse_categorical_crossentropy",
metrics="accuracy")
''' 모델 훈련시키기 '''
model.fit(train_scaled, train_target, epochs=epoch)
''' 성능평가 '''
score = model.evaluate(val_scaled, val_target)
''' 성능결과 반환하기 '''return score
''' 함수 호출하기 '''''' 옵티마이저를 리스트로 정의하기 '''
optimizers = ["sgd", "adagrad", "rmsprop", "adam"]
''' 최고 정확도를 담을 변수 정의 '''
best_acc = 0.0''' 최고 정확도일 때의 학습방법을 담을 변수 정의 '''
best_acc_opt = ""''' 최저 손실율를 담을 변수 정의 '''
best_loss = 1.0''' 최저 손실율일 때의 학습방법을 담을 변수 정의 '''
best_loss_opt = ""''' 옵티마이저의 학습방법을 반복하여 성능 확인하기 '''for opt in optimizers :
print(f"--------------------------{opt}--------------------------")
''' 함수 호출 '''
epoch=10
rs_score = getBestEval(opt, epoch)
''' 가장 높은 정확도와 이 때 학습방법 저장하기 '''if best_acc < rs_score[1] :
best_acc = rs_score[1]
best_acc_opt = opt
''' 가장 낮은 손실율과 이때 학습방법 저장하기 '''if best_loss < rs_score[0] :
best_loss = rs_score[0]
best_loss_opt = opt
print()
print('전체 실행 종료 >>>>>>>>>>>>>>>')
print(f"best_acc_opt : {best_acc_opt} / best_acc : {best_acc}")
print(f"best_loss_opt : {best_loss_opt} / best_loss : {best_loss}")