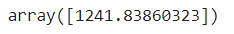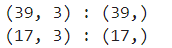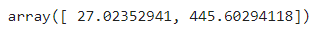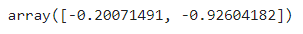정규화 : StandardScaler→ 분류 또는 회귀에서 사용가능하며, 주로 분류에서 사용됨
정규화 :RobustScaler → 분류 및 회귀 모두 사용가능
표준화 : MinMaxScaler→ 분류 또는 회귀에서 사용가능 하며, 주로 회귀에서 사용됨(최대 및 최소 범위 내에서 처리되는 방식)
1. 정규화 : StandardScaler
'''
훈련데이터 정규화 변수 : train_std_scaler
테스트데이터 정규화 변수 : test_std_scaler
'''
from sklearn.preprocessing import StandardScaler
''' 정규화 클래스 생성하기 '''
ss = StandardScaler()
''' 정규화 패턴 찾기 : 훈련데이터만 사용 '''
ss.fit(train_input)
''' 훈련 및 테스트 독립변수 변환하기 '''
train_std_scaler = ss.transform(train_input)
test_std_scaler = ss. transform(test_input)
train_std_scaler.shape, test_std_scaler.shape
2. 정규화 :RobustScaler
'''
훈련데이터 정규화 변수 : train_rbs_scaler
테스트데이터 정규화 변수 : test_rbs_scaler
'''
from sklearn.preprocessing import RobustScaler
''' 정규화 클래스 생성하기 '''
rbs = RobustScaler()
''' 정규화 패턴 찾기 : 훈련데이터만 사용 '''
rbs.fit(train_input)
''' 훈련 및 테스트 독립변수 변환하기 '''
train_rbs_scaler = rbs.transform(train_input)
test_rbs_scaler = rbs. transform(test_input)
train_rbs_scaler.shape, test_rbs_scaler.shape
3.표준화 : MinMaxScaler
'''
훈련데이터 표준화 변수 : train_mm_scaler
테스트데이터 표준화 변수 : test_mm_scaler
'''
from sklearn.preprocessing import MinMaxScaler
''' 표준화 클래스 생성하기 '''
mm = MinMaxScaler()
''' 표준화 패턴 찾기 : 훈련데이터만 사용 '''
mm.fit(train_input)
''' 훈련 및 테스트 독립변수 변환하기 '''
train_mm_scaler = mm.transform(train_input)
test_mm_scaler = mm. transform(test_input)
train_mm_scaler.shape, test_mm_scaler.shape
🍇 훈련하기
''' 훈련모델 생성하기 '''
from sklearn.ensemble import RandomForestClassifier
''' 모델(클래스) 생성하기
- cpu의 코어는 모두 사용, 랜덤값은 42번을 사용하여 생성하기
- 모델 변수의 이름은 rf 사용
'''
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
''' 모델 훈련 시키기 '''
rf.fit(train_std_scaler, train_target)
''' 훈련 및 검증(테스트) 정확도(score) 확인하기 '''
train_score = rf.score(train_std_scaler, train_target)
test_score = rf.score(test_std_scaler, test_target)
print(f"훈련 = {train_score} / 검증 = {test_score}")
### 모델 라이브러리 불러들이기
from sklearn.linear_model import LinearRegression
### 사용할 데이터
train_input, train_target, test_input, test_target
### 모델(클래스 생성하기)
lr = LinearRegression()
### 모델 훈련 시키기
lr.fit(train_input, train_target)
### 훈련 정확도
train_r2 = lr.score(train_input, train_target)
### 테스트(검증) 정확도
test_r2 = lr.score(test_input, test_target)
print(f"훈련={train_r2} / 테스트={test_r2}")
### (해석)
# - 결정계수 확인 결과, 훈련 결정계수 > 테스트 결정계수이므로 과소적합은 일어나지 않았으나,
# - 두 계수의 차이가 0.12로 과대적합이 의심됨
- 임의 값 예측 시 KNN보다는 성능이 좋은 예측이 가능하며, 과적합이 발생하지 않는 일반화된 모델로 보여지나, y절편의 값이 음수로 예측시 음수의 데이터가 예측 될 가능성이 있는 모델로 보여짐 - 종속변수 무게의 값은 0이하로 나올 수 없기에 이상치를 예측할 수 있는 모델로 현재 사용하는 데이터를 예측하기에는 부적합한 모델로 여겨짐
🧁 다항회귀모델
데이터의 분포가 선형이면서 곡선을 띄는 경우에 사용됨
곡선(포물선)의 방정식이 적용되어 있음
y = (a * x^2) + (b * x) +c
독립변수는 2개가 사용됨 : x^2값과 x값
🧁 훈련 및 테스트데이터의 독립변수에 x^2값 추가하기
# - 훈련 독립변수
train_poly = np.column_stack((train_input**2, train_input))
# - 테스트 독립변수
test_poly = np.column_stack((test_input**2, test_input))
train_poly.shape, test_poly.shape
🧁 모델 훈련 및 예측
### 모델 생성하기
# - 선형, 다형, 다중 회귀모델은 하나의 모델(클래스) 사용
# - 직선, 곡선에 대한 구분은 독립변수의 갯수로 모델이 알아서 구분해준다.
lr = LinearRegression()
### 모델 훈련 시키기
lr.fit(train_poly, train_target)
### 훈련 정확도 확인하기
train_r2 = lr.score(train_poly, train_target)
### 테스트 정확도 확인하기
test_r2 = lr.score(test_poly, test_target)
### 과적합 여부 확인(해석)
# - 0.007 정도의 과소적합(훈련 < 검증)이 발생
print(f"훈련 결정계수 = {train_r2} / 테스트 결정계수 = {test_r2}")
### 임의 값 길이 50으로 예측하기
pred = lr.predict([[50**2, 50]])
print(f"길이 50 예측 결과 : {pred}")
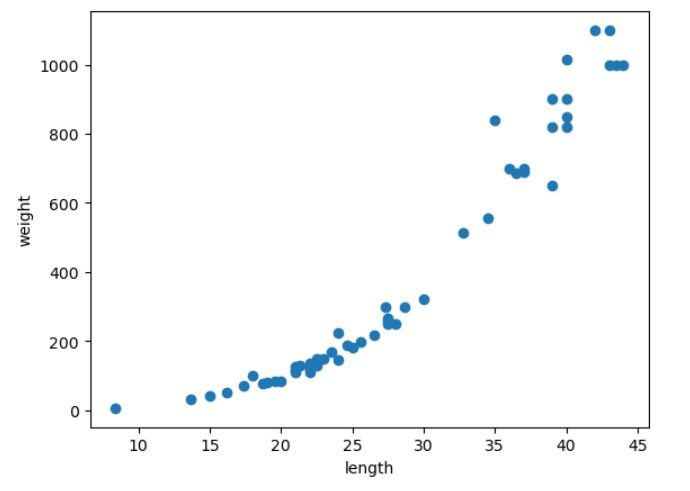
🧁 추세선 그리기
추세선을 그리기 위해서는 곡선의 방정식에 사용할 계수 a,b와 절편 c를 알아야 함
print(f"계수 = {lr.coef_} / 절편 = {lr.intercept_}")
a = lr.coef_[0]
b = lr.coef_[1]
c = lr.intercept_
print(f"a = {a} / b = {b} / c = {c}")
plt.scatter(train_input, train_target)
plt.scatter(50, pred[0], marker='^')
# 추세선
# - 추세선이 사용할 x축값 지정(0~50까지의 순차적인 값 사용)
point = np.arange(0, 51)
plt.plot(point, a*point**2 + b*point + c)
plt.grid()
plt.show()
해석 - 선형회귀모델의 경우에는 음의 절편값이 나타나는 모델이었으나, 다항회귀모델의 경우에는 이를 해소할 수 있었음 - 단, 길이(x)가 10이하의 독립변수는 사용하면 안됨 - 다항회귀모델의 훈련 및 테스트 결정계수의 결과 미세한 과소적합을 보이고 있으나, 사용가능한 모델로 판단됨 - 선형회귀모델에 비하여 독립변수들이 전체적으로 추세선에 가깝게 위치하고 있기에 오차가 적은 모델이라고 분석 됨
🧁 과소 / 과대 적합을 해소하기 위한 방법
데이터 양(row 데이터, 행)을 늘릴 수 있는지 확인
분석 모델이 좀 더 집중해서 훈련할 수 있도록 특성(독립변수)을 추가하는 방법 확인 → 특성을 추가(늘리는)하는 방법은 "특성공학" 개념을 적용 → 특성을 늘려서 사용하는 모델로 다중회귀모델이 있음 → 특성을 늘린다는 의미는 훈련의 복잡도를 증가시킨다고 표현하며, 복잡도가 증가되면, 훈련의 집중력이 강해지게 됨
복잡도를 늘리는 방법으로는 "규제" 방법이 있음 → "규제"를 하는 하이퍼파라미터 속성을 이용하는 방식으로 릿지와 라쏘 회귀모델 방식이 있음
이외 다른 회귀모델을 사용하여 비교
특성 → 컬럼, 필드, 퓨처 모두 같은 의미
데이터 처리 분야에서는 컬럼 또는 필드라고 칭하며, 머신러닝에서는 특성이라고 칭하며, 딥러닝에서는 퓨처라고 칭함
💎 다중회귀모델(Multiple Regression)
여러개의 특성을 사용한 회귀모델
특성이 많을수록 복잡도가 증가됨(훈련 시간이 오래걸림, 시스템 성능에 따라 빠를 수도 있음)
다중회귀모델 공식 y = a*x1 + b*x2 + c*x3 + ... + y절편 (x의 값은 3개 이상)
💎 데이터 불러들이기
사용할 데이터프레임 변수
import pandas as pd
df = pd.read_csv("./data/03_농어의_길이_높이_두께_데이터.csv")
💎 농어의 길이, 두께 높이 값을 이용해서 무게 예측하기
독립변수 : 길이, 두께, 높이
종속변수 : 무게
독립변수 생성하기 → 데이터프레임의 특성 중에 독립변수로 사용할 특성들을 2차원의 리스트 또는 배열 형태로 만들어아야 한다. → to_numpy() : 행렬 데이터 형태를 리스트 배열 형태로 바꿈
from sklearn.linear_model import LinearRegression
### 모델 생성하기
lr = LinearRegression()
### 모델 훈련시키기
lr.fit(train_input, train_target)
### 훈련 정확도 및 검증(테스트) 정확도 확인하기
train_r2 = lr.score(train_input, train_target)
test_r2 = lr.score(test_input, test_target)
print(f"훈련 = {train_r2} / 테스트 = {test_r2}")
과적합 여부 판단하기 - 훈련과 검증(테스트) 결정계수의 결과로 볼 때 과소적합은 발행하지 않았다. 또한, 0.07 ~ 0.08 정도로 과대적합 또한 일어나지 않은 일반화 된 모델로 볼 수 있음 - 다만, 검증(테스트) 정확도가 0.8대에서 0.9대로 올릴 수 없을지 고민해 본다. - 특성공학을 적용하여 특성 늘리는 방법으로 집중도를 강화하는 방식을 사용해서 성능 향상이 되는지 확인한다.
특성을 생성하는 라이브러리 - 사용 패키지 : sklearn.preprocessing - 사용 클래스 : PolynomialFeatures(변환기라고 보통 칭한다) - 사용 함수 : fit(훈련 독립변수에서 생성할 특성의 패턴 찾기), transform(찾은 패턴으로 특성 생성하기) - 종속변수는 사용되지 않는다.
💎 테스트 데이터로 예측하기
test_pred = lr.predict(test_input)
test_pred
💎 평균절대오차(MAE) 확인하기
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(test_target, test_pred)
mae
💎 특성공학
💎 특성공학 적용하기
패키지 정의하기
from sklearn.preprocessing import PolynomialFeatures
클래스 생성하기 - 특성을 생성 시킬 때 y절편값도 생성을 함께 시킨다. - 특성만 있으면 되기 때문에 y절편은 생성에서 제외시키기 위해서 include_bias(y절편) = False로 설정한다.
poly = PolynomialFeatures(include_bias = False)
sample 데이터로 어떤 특성들이 만들어지는지 확인하기
temp_data = [[2, 3, 4]]
temp_data
특성을 만들 패턴 찾기
poly.fit(temp_data)
찾은 패턴으로 특성 생성하기
poly.transform(temp_data)
💎 실제 독립변수를 이용해서 특성 생성하기
클래스 생성하기
degree = 2 - 차원을 의미하며 2는 제곱승을 의미함 - 3을 넣으면 2의 제곱, 3의 제곱을 수행 - 4를 넣으면 2의 제곱, 3의제곱, 4의 제곱승을 수행함 - 기본값은 2 (생략하면 2의 제곱승이 적용됨)
### 훈련 독립변수에 특성 추가하기
train_poly = poly.transform(train_input)
### 테스트 독립변수에 특성 추가하기
test_poly = poly.transform(test_input)
train_poly.shape, test_poly.shape
사용된 패턴 확인하기
poly.get_feature_names_out()
💎 모델 생성 / 훈련 / 예측 / 평가
### 모델 생성하기
lr = LinearRegression()
### 모델 훈련시키기
lr.fit(train_poly, train_target)
### 훈련 정확도 및 검증(테스트) 정확도 확인하기
train_r2 = lr.score(train_poly, train_target)
test_r2 = lr.score(test_poly, test_target)
### 예측 하기
test_pred = lr.predict(test_poly)
### 모델 평가하기(MAE)
mae = mean_absolute_error(test_target, test_pred)
print(f"훈련 = {train_r2} / 테스트 = {test_r2} / 오차 = {mae}")
해석 - 특성공학을 적용하지 않은 모델은 검증(테스트) 정확도가 다소 낮았으며, 오차가 50g 정도 있으나- 특성공학을 적용하여 특성을 추가하여 훈련 집중도를 높였을 때는 훈련 및 검증(테스트) 정확도 모두 높아졌으며, 과적합이 발생하지 않은 일반화 모델로 오차는 30g정도의 매우 우수한 모델로 판단 됨 - 이 모델을 사용하려면, 독립변수의 특성 길이, 높이, 두께 3개의 특성을 사용해야 하고 특성 생성 시 degree 2를 적용한 특성을 사용해야 함
💎규제
💎 규제
과대 또는 과소 적합 중에 주로 과대적합이 발생 했을 때 사용된다.
훈련의 정확도가 다소 낮아지는 경향이 있으나. 검증(테스트) 정확도를 높이는 효과가 있음
훈련모델을 일반화하는데 주로 사용되는 방법임
규제 개념을 적용한 향상된 모델 : 릿지(Ridge)와 라쏘(Lasso)가 있다.
💎 규제 순서
정규화(단위(스케일)을 표준화 시키는 방식)
규제가 적용된 모델 훈련 / 검증
💎 훈련 및 테스트 독립변수 정규화 하기
정규화를 위한 라이브러리
from sklearn.preprocessing import StandardScaler
정규화 순서 1. 정규화 클래스 생성 2. fit() : 정규화 패턴 찾기(훈련 독립변수 사용) 3. transform() : 찾은 패턴으로 정규화 데이터로 변환(훈련 및 테스트 독립변수 변환)
''' 1. 정규화 클래스 생성 '''
ss = StandardScaler()
''' 2. 정규화 패턴 찾기 '''
ss.fit(train_poly)
''' 3. 찾은 패턴으로 훈련 및 테스트 독립변수 변환 생성하기 '''
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
print(f"{train_scaled.shape} / {test_scaled.shape}")
릿지(Ridge) 모델
from sklearn.linear_model import Ridge
''' 모델 생성하기'''
ridge = Ridge()
''' 모델 훈련시키기 '''
ridge.fit(train_scaled, train_target)
''' 훈련 및 검증(테스트) 정확도 확인하기 '''
train_r2 = ridge.score(train_scaled, train_target)
test_r2 = ridge.score(test_scaled, test_target)
train_r2, test_r2
해석 - 과적합 여부를 확인한 결과, 과소적합은 발생하지 않았으며- 기존 특성공학을 적용한 우수한 모델보다는 훈련 정확도는 0.005정도 낮아 졌지만 검증(테스트) 정확도는 0.013 정도 높아졌음 - 또한, 평균절대오차(MAE)도 1g 낮아졌음 - 따라서, 일반화되고, 오차가 적은 Ridge 모델은 매우 우수한 모델로 판단됨
라쏘(Lasso) 모델
### 사용할 패키지
from sklearn.linear_model import Lasso
### 모델 생성하기
lasso = Lasso()
''' 모델 훈련시키기 '''
lasso.fit(train_scaled, train_target)
''' 훈련 및 검증(테스트) 정확도 확인하기 '''
train_r2 = lasso.score(train_scaled, train_target)
test_r2 = lasso.score(test_scaled, test_target)
train_r2, test_r2
### 훈련 독립변수 2차원 만들기
# -1 : 전체를 의미함
train_input = train_input.reshape(-1, 1)
### 테스트 독립변수 2차원 만들기
test_input = test_input.reshape(-1, 1)
print(f"{train_input.shape} / {test_input.shape}")
해석 - 훈련 및 테스트 정확도는 매우 높게 나타난 성능 좋은 모델로 판단됨 - 그러나 과적합 여부를 확인한 결과, 훈련 정확도가 테스트 정확도보다 낮게 나타난 것으로 보아 과소 적합이 발생하고 있는 것으로 판단됨 - 이는 데이터의 갯수가 적거나, 튜닝이 필요한 경우로 이후 진행을 하고자 함
모델 평가하기 : 평균절대오차(MAE)
🎈 평균절대오차(MAE; Mean Absolute Error)
회귀에서 사용하는 평가방법
예측값과 실제값의 차이를 평균하여 계산한 값
즉, 사용된 이웃들과의 거리차를 평균한 값
라이브러리
from sklearn.metrics import mean_absolute_error
🎈 예측하기
5개 이웃의 평균 값이 나옴
test_pred = knr.predict(test_input)
test_pred
🎈 평가하기
mean_absolute_error(실제 종속변수, 예측 종속변수)
mae = mean_absolute_error(test_target, test_pred)
mae
해석 - 해당 모델을 이용해서 예측을 할 경우에는
- 평균적으로 → 약 19.157g 정도의 차이(오차)가 있는 결과를 얻을 수 있음
- 즉, 예측결과는 약 19.157g 정도의 차이가 있다
하이퍼파라미터 튜닝
🎈 과소적합을 해소하기 위하여 튜닝을 진행해 보기
이웃의 갯수 → 기본값 사용
### KNN 모델의 이웃의 갯수(하이퍼파리미터)를 조정해보기
### 이웃의 갯수 -> 기본값 사용
knr.n_neighbors = 5
### 하이퍼파라미터 값 수정 후 재훈련 시켜서 검증해야 한다.
knr.fit(train_input, train_target)
### 훈련정확도 확인
train_r2 = knr.score(train_input, train_target)
### 테스트(검증) 정확도 확인
test_r2 = knr.score(test_input, test_target)
print(f"훈련={train_r2} / 테스트={test_r2}")
해석
- 과적합 여부 확인 결과 과소적합이 발생하여, 훈련모델로 적합하지 않음
- 과소적합 해소 필요
이웃의 갯수 조정
### KNN 모델의 이웃의 갯수(하이퍼파리미터)를 조정해보기
knr.n_neighbors = 3
### 하이퍼파라미터 값 수정 후 재훈련 시켜서 검증해야 한다.
knr.fit(train_input, train_target)
### 훈련정확도 확인
train_r2 = knr.score(train_input, train_target)
### 테스트(검증) 정확도 확인
test_r2 = knr.score(test_input, test_target)
print(f"훈련={train_r2} / 테스트={test_r2}")
해석
- 과소적합 해소를 위해 이웃의 갯수를 조정하여 하이퍼파라미터 튜닝을 진행한 결과 - 과소적합을 해소할 수 있었음 - 또한, 훈련 정확도와 테스트 정확도의 차이가 크지 않기에 과대적합도 일어나지 않았음 - 다만, 테스트 정확도는 다소 낮아진 반면 훈련정 확도가 높아졌음 - 이 모델은 과적합이 발생하지 않은 일반화된 모델로 사용가능
🎈 가장 적합한 이웃의 갯수 찾기(하이퍼파리미터 튜닝)
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 갯수 찾기
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2):
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
# - 훈련 독립변수
train_input = fish_data[ : 35]
# - 훈련 종속변수
train_target = fish_target[ : 35]
print(len(train_input), len(train_target))
🧤 테스트 데이터(test)
# - 훈련 독립변수
test_input = fish_data[35 : ]
# - 훈련 종속변수
test_target = fish_target[35 : ]
print(len(test_input), len(test_target))
모델 생성하기
from sklearn.neighbors import KNeighborsClassifier
🧤모델(클래스) 생성
이웃의 갯수는 기본값 사용
kn = KNeighborsClassifier()
kn
🧤 모델 훈련 시키기
훈련데이터 적용
kn.fit(train_input, train_target)
🧤 훈련 정확도 확인하기
# - 훈련 데이터 사용
train_score = kn.score(train_input, train_target)
### 검증하기
# - 테스트 데이터 사용
test_score = kn.score(test_input, test_target)
train_score, test_score
해석 - 훈련 정확도가 1 이기 때문에 과대적합이 발생하였으며, 검증 정확도가 0으로 나타났음
- 따라서, 이 훈련 모델은 튜닝을 통해 성능 향상을 시켜야 할 필요성이 있음
원인분석 - 데이터 분류시 : 35개의 도미값으로만 훈련을 시켰기 때문에 발생한 문제
- 즉, 검증데이터가 0이 나왔다는 것은, 또는 매우 낮은 정확도가 나온 경우데이터에 편향이 발생하였을 가능성이 있다고 의심해 본다.
-샘플링 편향: 특정 데이터에 집중되어 데이터가 구성되어 훈련이 이루어진 경우 발생하는 현상 -샘플링 편향해소방법 : 훈련 / 검증 / 테스트 데이터 구성시에 잘 섞어야 한다. (셔플)
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 갯수 찾기
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2):
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
과대적합이 보통 0.1 이상의 차이를 보이면 정확도의 차이가 많이난다고 의심해 볼 수 있음
모델 선정 기준
과소적합이 일어나지 않으면서, 훈련 정확도가 1이 아니고 훈련과 검증의 차이가 0.1 이내인 경우
선정된 모델을 "일반화 모델"이라고 칭한다.
다만, 추가로 선정 기준 중에 평가기준이 있음
가장 바람직한 결과는 훈련 > 검증> 테스트
(훈련 > 검증 < 테스트인 경우도 있음)
🧤 하이퍼파라미터 튜닝
### 1보다 작은 가장 좋은 정확도일 때의 이웃의 갯수 찾기
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(train_input, train_target)
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
for n in range(3, len(train_input), 2):
kn.n_neighbors = n
score = kn.score(train_input, train_target)
print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
- 예측 결과는 빙어로 확인되었으나, 시각적으로 확인하였을 때는 도미에 더 가까운 것으로 확인 됨 - 실제 이웃을 확인한 결과 빙어쪽 이웃을 모두 사용하고 있음 - 이런 현상이 발생한 원인 : 스케일(x축과 y축의 단위)이 다르기 때문에 나타나는 현상 → "스케일이 다르다" 라고 표현 한다.
-해소 방법 : 데이터 정규화 전처리를 수행해야 함
🧤 정규화 하기
현재까지 수행 순서
1. 데이터 수집 2. 독립변수 2차원과 종속변수 1차원 데이터로 취합 3. 훈련, 검증, 테스트 데이터로 섞으면서 분리 4. 훈련, 검증, 테스트 데이터 중에 독립변수에 대해서만 정규화 전처리 수행 5. 훈련모델 생성 6. 모델 훈련 시키기 7. 훈련 및 검증 정확도 확인 8. 하이퍼파라미터 튜닝 9. 예측
### 모델(클래스 생성)
kn = KNeighborsClassifier()
### 훈련시키기
kn.fit(fish_data, fish_target)
### 정확도가 가장 높을 떄의 이웃의 갯수를 담을 변수
nCnt = 0
###정확도가 가장 높을때의 값을 담을 변수
nScore = 0
# - 반복문 사용 : 범위는 3 ~ 전체 데이터 갯수
for n in range(3, len(fish_data), 2):
kn20.n_neighbors = n
score = kn20.score(fish_data, fish_target)
print(f"{n} / {score}")
19일 때 가장 높은 정확도를 가짐
동일한 정확도일 때 이웃 갯수가 많을수록 PC과부하
그러므로 가장 갯수가 적은 19를 선택
for n in range(3, len(fish_data), 2):
kn20.n_neighbors = n
score = kn20.score(fish_data, fish_target)
#print(f"{n} / {score}")
### 1보다 작은 정확도인 경우
if score < 1 :
### nScore의 값이 score보다 작은 경우 담기
if nScore < score :
nScore = score
nCnt = n
print(f"nCnt = {nCnt} / nScore = {nScore}")
해석: 모델의 성능이 가장 좋은 시점의 이웃의 갯수를 추출하기 위한 하이퍼파리메터 튜닝 결과, 이웃의 갯수 19개를 사용하였을 때가장 좋은 성능을 발휘하는 것으로 확인 됨